Managing Global Data in Microservice Polyglot Persistence Scenarios
Analyzing the management of global data in a microservices environment where polyglot persistence is adopted
Join the DZone community and get the full member experience.
Join For FreeEditor’s Note: The following is an article written for and published in DZone’s 2021 Data Persistence Trend Report.
Microservices architectures are naturally prone to host polyglot persistence scenarios. Thanks to the fact that microservices are technology-agnostic, indeed, it is possible to adopt different data storage technologies depending on their functionalities.
On the one hand, such an approach allows for increasing the overall performance of a system. Architects and developers may tune each microservice to be as effective as possible by selecting technology that offers functionalities best suited to the performance needs unique to each service. On the other hand, there could be an increment of complexity. One aspect that can increase such complexity is represented by those data that have a global scope with respect to single microservices, thus requiring them to be synchronized.
This article is focused on analyzing the management of global data in a microservices environment where polyglot persistence is adopted. In particular, we will discuss some possible solutions for dealing with the alignment of global data among all the involved microservices. A discussion about transactional synchronization in a distributed microservice architecture is out of the scope of this article — eventual consistency scenarios are considered instead.
Polyglot Persistence and Microservices
Polyglot persistence means the usage of multiple data storage technologies within the same application, where each technology can be used for addressing different requirements. For example, there are:
- Key-value databases – usually adopted when fast read and writes are required.
- RDBMSs – used when transactions are strictly necessary and data structures are fixed.
- Document-based databases – used when dealing with high loads and flexible data structures.
- Graph databases – used when rapid navigation among links is necessary.
- Column databases – used when large-scale analytics are needed.
Polyglot Persistence Scenario: One-to-One
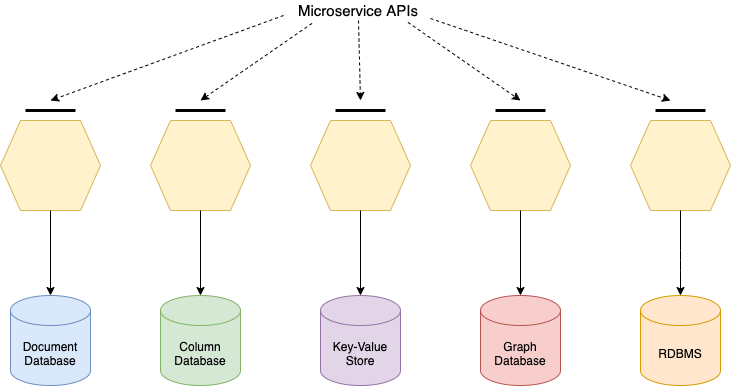
The ideal polyglot persistence scenario in a microservices architecture is what we call the one-to-one scenario (Figure 1), where there is a unique microservice for each data persistence technology. This is one of the natural derivations of the microservice approach through which microservices boundaries can be defined depending on the technology they manage, thus offering a set of APIs to external invokers, which abstract away from the peculiarities of the underlying technology.
Figure 1
Complex Polyglot Persistence Approaches
In real life, the scenarios could be more complicated. More microservices could need access to the same data source, and more data sources can be used within the same microservice. We name the former case more-to-one scenario and the latter case one-to-more. Finally, we call more-to-more the mixed one. Figure 2 illustrates each of these scenarios:
Figure 2
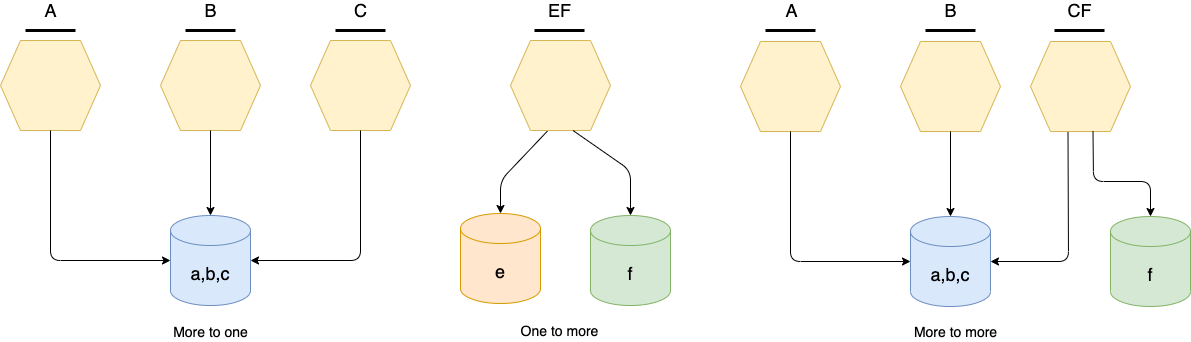
Table 1
| Scenario | Description |
| More-to-one | When the data contained in a single data source are so large and differentiated that they require more microservices that offer sets of different functionalities An intuitive example: a large catalogue of various products having microservices that manage different types of products because they have diverse characteristics In Figure 2, a, b, and c are mapped into API ABC at the microservice level. Note: ABC is not necessarily the bare sum of A, B, and C — it could be just a basic set of APIs from which it is possible to extract A, B, and C by refinement and composition. |
| One-to-more | When the data model of the microservice requires data to be stored in multiple data sources Figure 2 shows datasets e and f are composed at the microservice level and are mapped into the API EF. |
| More-to-more | A combination of the more-to-one and one-to-more scenarios |
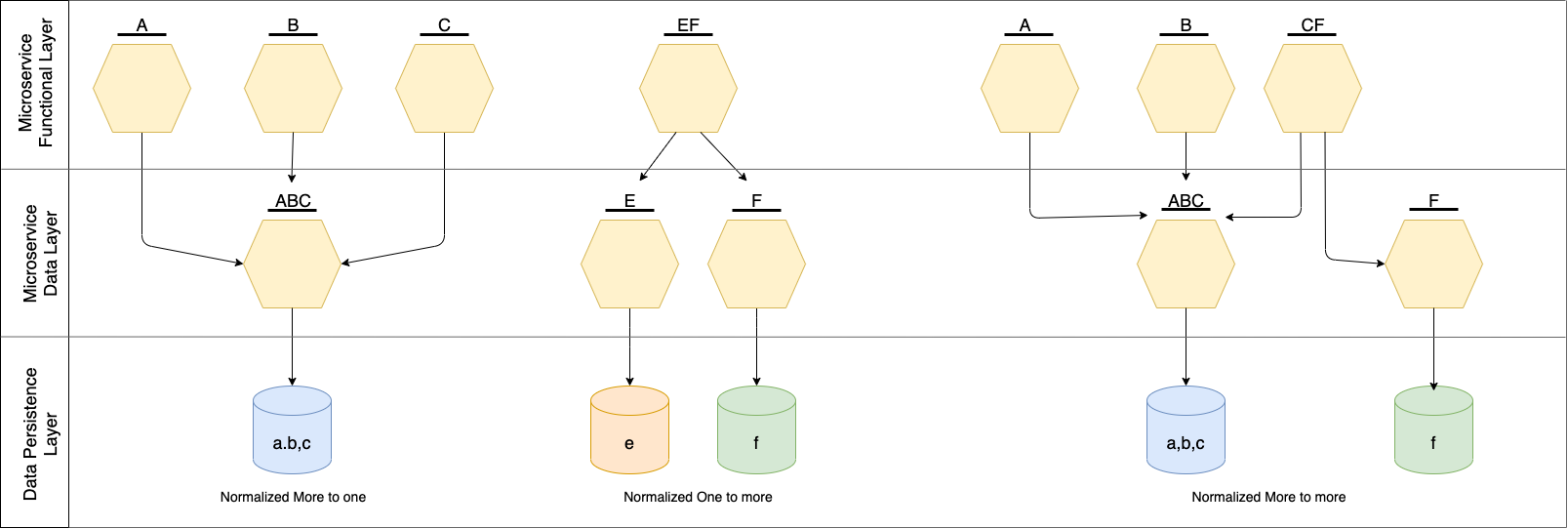
Ideally, these three scenarios can be normalized into a pure one-to-one scenario. Such a normalization allows for dividing the architecture into three fundamental layers:
- Data persistence layer – the bottom layer where there are data sources.
- Microservice Data Layer – the microservice layer that manages the data source.
- Microservice Functional Layer – the microservices that implement the business functionalities.
Such a normalization step is not mandatory, but it may be useful as a reference when making architectural decisions. Figure 3 reports how the above approaches can be normalized into a one-to-one approach using a three-layered architecture:
Figure 3
Global Data and Data Master Services
Global data has a scope that spans even more microservices, thus it can be present in the signatures of different microservices. As an example, let us consider the field email of a customer. It will be stored in the data source with user profiles, but it could also be required to perform payments or generate reports. In Figure 4, both microservices B and D provide functionalities where global data EMAIL is present. Microservice B retrieves EMAIL from microservice W, whereas microservice D retrieves EMAIL from microservice U. In this case, we suppose EMAIL is stored both in the RDBMS and the column database.
Figure 4
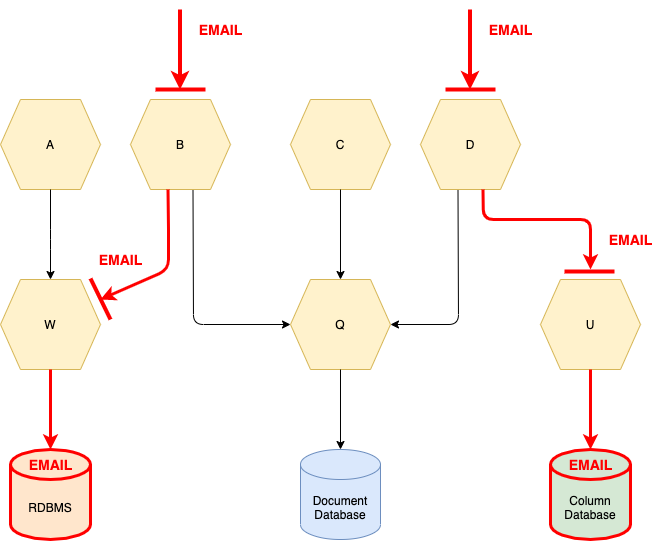
Clearly, in the depicted scenario, it is possible that the EMAIL could differ because of a modification. Thus, it is necessary to synchronize the value of EMAIL within both databases.
To do that requires identifying the master data source and the slave sources. Every modification of the data must be performed in the master source and then communicated to the slaves. Usually, the master data source is more focused on the specific type of global data. In the previous example, the EMAIL could be stored in the master data source — the RDBMS, which keeps the customer registry — whereas the column database could act as a slave.
This is an excerpt from DZone's 2021 Data Persistence Trend Report.
For more:
Read the Report
Synchronizing Data Using Batch Processes
Batch processes are often used for extracting data from a data source and transferring them into another. They are periodically triggered and can transfer a huge amount of data, but they are strongly coupled with the data source technologies and cannot guarantee an immediate synchronization. Further, they can easily increment technical debt, thus limiting the overall flexibility of the system.
In Figure 5, global data EMAIL is stored in three data sources — RDBMS-1, CD (column database), and RDBMS-2 — and is accessed by microservices W, U and Q, respectively. RDBMS-1 is the master and accepts writing operations from W. The others are slaves and are periodically synchronized thanks to two batch processes (grey rectangles). U and Q can only read the value of EMAIL without altering it.
Figure 5
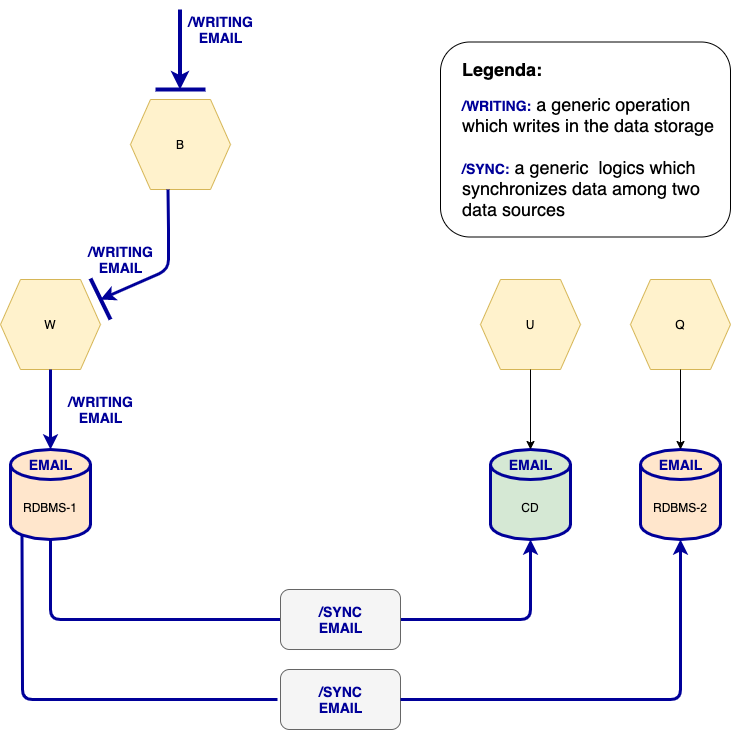
Table 2: Using Batch Processes
| Advantages | Disadvantages |
| Massive data synchronization |
|
Synchronizing Data Using a Coordinator and an Asynchronous Queue
A solution that is most suitable for microservices architectures is using a coordinator with an asynchronous queue (see example in Figure 6). This approach includes:
- An asynchronous queue – keeps all the data change records in order to process them in the right sequence.
- A gateway interceptor– intercepts both the request and response of the writing of global data, and then pushes the data change records into the queue.
- A temporary queue can store pending requests while the microservice completes the writing and clears when the response message is intercepted.
- The temporary queue helps find inconsistencies in global data synchronization due to writing microservice malfunctioning.
- A coordinator – processes the data change record into the queue and calls all of the involved microservices to write the update.
Figure 6
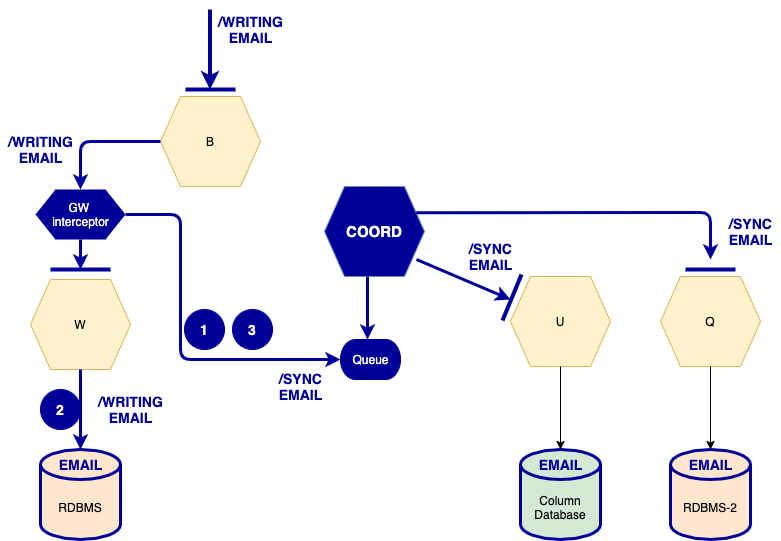
It is worth noting that from the design point of view, the slave microservices APIs should not offer explicit writing operations for global data — just the synchronizing ones. Such a choice will avoid direct writing of global data into slave microservices.
Table 3: Using a Coordinator and Asynchronous Queue
| Advantages | Disadvantages |
|
|
Synchronizing Data Using an Event-Based Backbone
Finally, a Kafka event backbone can be used when there are numerous data to be synchronized and the slave microservices could vary; some of them can be added and others can be removed. In this scenario, there are specific topics programmed into the backbone — a topic for each global data to be synchronized. Each slave microservice can independently retrieve the data change from the backbone and then synchronize its own data. This is a pluggable infrastructure that can scale easily.
Here, the price to pay is that each slave microservice must be equipped with a specific agent that is in charge of getting the data from the backbone. Figure 7 depicts an example of a Kafka backbone where a specific topic is dedicated to global data EMAIL. The master writes on the topic every time there is a modification, and the slaves read from the topic to be kept aligned.
Figure 7

Table 4: Using an Event-Based Backbone
| Advantages | Disadvantages |
|
|
Conclusion
In this article, we analyzed polyglot persistence scenarios with microservices. We showed how to normalize an architecture to become the more ideal one-to-one architecture and discussed the differences between master and slave microservices. Finally, we demonstrated three ways to synchronize global data across microservices, which are reexamined simply below:
- Batch processes – a legacy solution that should be deprecated.
- Coordinator with an asynchronous queue – the right solution when there are a limited set of global data and slave microservices to be synchronized.
- Event-based backbone – the right solution when the system is quite complex with many microservices and different data to be synchronized.
| Claudio Guidi, Chairman of the Board at italianaSoftware s.r.l. @cguidi on DZone | @guidiclaudio on Twitter | @claudioguidi on LinkedIn Claudio is the co-creator and language designer of the programming language Jolie. He works also as a software architect consultant, and he is a member of the Council of the Microservices Community. |
Opinions expressed by DZone contributors are their own.
Comments