Data Management Patterns for Microservices
Learn common database patterns for microservices, explore CQRS (including how it differs from CRUD), and, finally, how it can be combined with event sourcing.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2022 Database Systems Trend Report.
For more:
Read the Report
One of the key components of microservices is how to manage and access data. The means to do that are different compared to traditional monolithic or three-tier applications. Some patterns are quite common, but others are specific and need to be evaluated before being incorporated into a solution. We will briefly go over some of these common database patterns for microservices before exploring CQRS (including how it differs from CRUD) and, finally, look at how it can be combined with event sourcing.
Common Database Patterns for Microservices
There are multiple patterns for using databases in the context of microservices. In this section, we will cover a few, starting with one of the most common patterns.
Database per Microservice
Instead of "one size fits all," using a database per microservice helps ensure that each service can use the database per its requirements based on data storage, modeling, etc. There are situations where a relational database is the perfect fit, while other use cases will benefit from a key-value or even document-based (JSON) database. The details of the underlying database are abstracted by a service-specific API, ultimately leading to flexible and loosely coupled architectures.
API Composition
Each service has its own database and exposes its API thanks to the database per microservice pattern.
The API composition pattern introduces another level of abstraction, where an API composer component takes on the responsibility of querying individual services' APIs. This scatter-gather type of approach avoids complexity by providing a unified interface to client applications.
Saga
This is an advanced pattern that helps overcome the constraints introduced by the database per microservice pattern and the distributed nature of microservices architectures in general. These patterns require interacting with multiple services (and their respective databases), making transactional workflows (with ACID compliance) difficult to implement. The Saga pattern involves orchestrating multiple local (service-specific) transactions and executing a compensating transaction(s) to undo them in case of failure.
Command Query Responsibility Segregation and Event Sourcing
Like the saga pattern, Command Query Responsibility Segregation (CQRS) and event sourcing are relatively advanced techniques that involve separating read and write paths. The next section will discuss more about CQRS and how it compares with another widely used technique — create, read, update, delete (CRUD).
CQRS and CRUD
Let's get a basic understanding of these terminologies.
CRUD
CRUD-based solutions are commonly used to implement simple application logic. Take, for example, a user management service that handles user registration, listing users, updating user information (enabling/disabling), and removing users. CRUD is so attractive because it uses a single data store and is well understood, making it easy to embrace common architectural patterns, such as REST over HTTP (with JSON being a widely used data format).
CQRS
In contrast to CRUD-based solutions, CQRS is about using different data models for read and write operations — within a single database or across multiple databases. This allows for managing read/write portions of the application independently. For example, you can have separate database tables for read/write operations or leverage read-replicas to scale out read-heavy applications.
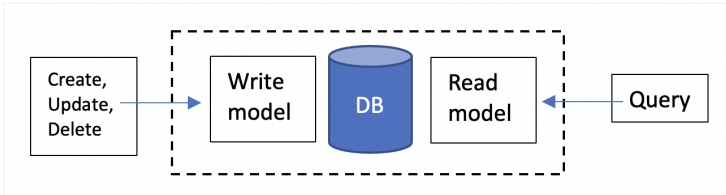
Figure 1: CQRS, same or different data stores
CRUD and CQRS: Differences
Let's learn more about CQRS and, in the process, understand how it's different from CRUD by examining various characteristics.
Type of Data Stores
As mentioned earlier, it's possible to implement CQRS with single or multiple data stores. In the case of a single database, you might use techniques such as separate read/write tables and read replicas. Alternatively, you could leverage different databases to cater to specific requirements of the read/write paths of your operation — for example, you could use a relational database with ACID semantics to handle low to medium write workloads and use an in-memory cache (like Redis) to serve read requests.
Synchronous or Asynchronous
CRUD operations are mostly executed in a synchronous way, although, depending on the programming language and client library, you can have asynchronous implementation on the client side. CQRS also can be implemented in a synchronous way, but that's rare. Because CQRS involves multiple data stores (same or different databases), it benefits from a mechanism wherein the read model is updated asynchronously in response to changes in the write data store. For example, user information inserted (or updated) in an RDBMS table results in the Redis for low-latency reads at high scale/volume. But this approach forces us to think about another important attribute — consistency.
Consistency
Since CRUD systems are synchronous in nature and benefit from ACID support (in relational databases), they get strong consistency (almost for free). With CQRS implementations, your architecture needs to embrace eventual consistency due to its asynchronous nature and make sure your applications can tolerate reading (possibly) stale data, even though it might for only a short period of time.
Scalability
The fact that CQRS solutions can leverage multiple data stores and can operate asynchronously allows them to be more scalable. For example, leveraging separate data stores optimizes for high-read volumes if there is a need to do so. Scalability of CRUD solutions is constrained by the single data store and a synchronous mode of operation.
Complexity
As obvious as this might sound, it's quite complex to architect applications using the CQRS pattern. As mentioned previously, you may need to use multiple data stores, implement asynchronous communication between them, and also tackle eventual consistency and its caveats. CRUD operations are well understood and widely used, so there often is great support, such as code-generators, object-relational modeling libraries, etc., which significantly eases the development process.
Here is a table summarizing the differences:
| Characteristic | CQRS | CRUD |
|---|---|---|
| Type of data store | Single or multiple data stores | Single data store |
| Synchronous or asynchronous | Asynchronous (mostly) | Synchronous |
| Consistency | Eventual consistency | Strong consistency |
| Scalability | High | Limited |
| Complexity | High | Relatively low |
CQRS and Event Sourcing — Better Together?
With event sourcing, the "C" in CQRS (which stands for command) comes alive. The write part of the system is now responsible for storing commands in an event store while the read part is all about having a denormalized form of the data — this form is also referred to as materialized views that support specific queries for a UI or application. An event sourcing- and CQRS-based solution might have several such views across multiple data stores. Often, these patterns are natively supported by data stores themselves, such as Postgres, Cassandra, etc.
Events are not ordinary data — these represent actions in your system; hence, the write model leverages an append-only, immutable data store. Sometimes, event sourcing solutions also leverage streaming platforms, such as Apache Kafka, in the write path instead of traditional SQL/NoSQL databases.
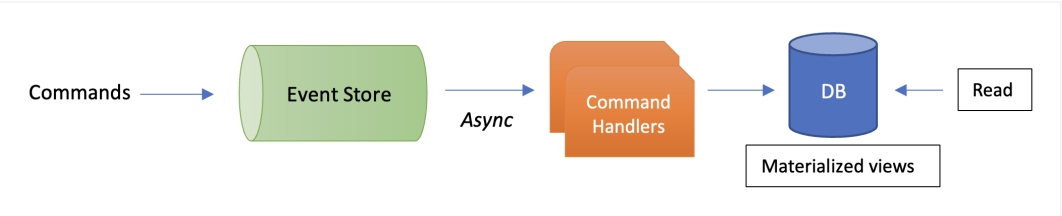
Figure 2: Event sourcing
Let's look at a simple example. Think of a limited subset of functionality in an application like Twitter — users send tweets, follow each other, and see tweets from users they follow. A naive solution is one where the follower timelines are updated synchronously when a user tweets. This is not scalable for a system where users can have millions of followers. A better approach is to split this into different parts where "tweet sent" (the command) is used as an event to that can trigger the timeline update of followers, which can happen asynchronously. Followers can then see the tweet, which would be handled by the "query" part of the solution and potentially backed by a different data store — the system has to tolerate eventual consistency, which is acceptable for this particular use case.
Pros and Cons
Event sourcing and CQRS do give you a lot of power, but with that comes great responsibility. If you don't have a complicated data model, stick to a CRUD-based solution to simplify your overall architecture.
Event sourcing involves capturing the commands/events (that have changed the system) in an append-only, immutable manner — this implies that there is a possibility of replaying "historical" data to rebuild some/entire parts of the system if there is a need to do so. However, this is not easy in practical scenarios, and such processes need to be planned out well to minimize downtime and service disruption. If your application does not have such intensive requirements, it's a good idea to avoid event sourcing/CQRS.
Your architecture deals with events, and you can build multiple applications to handle them. For example, a user-created event can trigger a send email handler while another handler can take care of a different operation (in parallel). At the same time, you need to factor in error handling, retries, and eventual consistency. Be aware of these requirements, and don't use CRQS/event sourcing if your application cannot tolerate eventual consistency.
Conclusion
As microservices have become the norm, many techniques and patterns have emerged to tackle their increased complexity. CRUD-based solutions are widely used but have their limitations. Advanced patterns, such as CQRS and event sourcing, can help with scalability, but you need to avoid falling into the premature optimization trap. Using the right tool/pattern for the job goes a long way in long-term application maintainability.
This is an article from DZone's 2022 Database Systems Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments