Understanding N-Gram Language Models and Perplexity
This guide explains how N-gram language models work, how they estimate probabilities, handle unknown words, and evaluate performance using perplexity and other methods.
Join the DZone community and get the full member experience.
Join For FreeLanguage models are designed to predict what words are likely to come next in a sequence, assigning probabilities to each possible continuation. In this article, we explore how an N-gram language model works, how it assigns probabilities to sentences and sequences of words, and then examine how well this model performs. By understanding and evaluating this approach, we gain insight into how language models handle the complexity of human language.
Applications
- Augmentative communication
- Machine translation
- Spelling correction
- Speech recognition
Language Models
Definition
A language model consists of a finite set V and a function f(x1, x2, ..., xn) such that:
- For any <x1, x2, ..., xn>; ∈ V*, f(x1, x2, ..., xn) ≥ 0
![]()
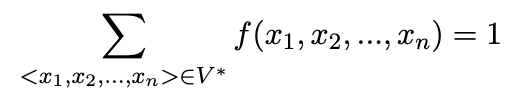
1 and 2 above implies that f(x1, x2, ..., xn) is a probability distribution over the sentences in V*, where
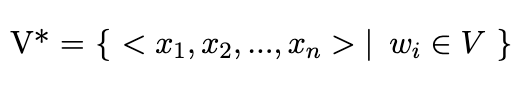
Estimation
Now our task is to compute the joint probability P(w1, w2, ..., wn), where wi denotes ith word in the sequence of words. Before that, lets take an example and understand how to calculate the probability P(the | hilary clinton is). The conventional approach is to calculate as follows:
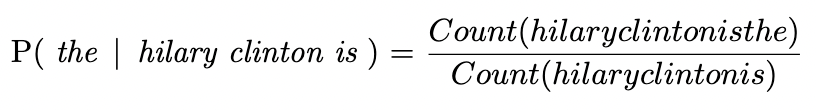
But we don’t have a large enough corpus to approximate the probability calculated above with the exact probability values. So, the generalization is poor. Also, there may be the case that in the corpus, some sequences of words are not there but in the English language, such sequences of words do exist. In that case, the probability would come out to be zero, which is not correct. Now, lets assume, for the sake of notational convenience, we take
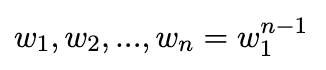
So,
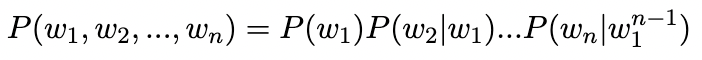
But again, the question remains: how do we calculate P(wn | w1n-1)?
N-gram Models
General N-gram model
An N-gram language model applies the Markovian assumption to the expression obtained above for P(w1, w2, ..., wn). We will assume that the probability of the next word depends only on the N already occurred words. Hence, we get several variance of N-gram models.
Some important ones are:
- Bigram (N=2)
- Trigram (N=3)
Here, we will discuss the theory for only the Bigram model. The same theory will be applicable to general N-gram models. For general N-gram model, we approximate,
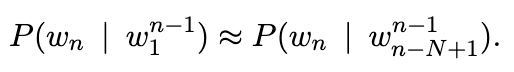
Bigram Model
Here, we approximate,
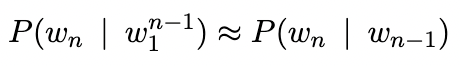
Hence,
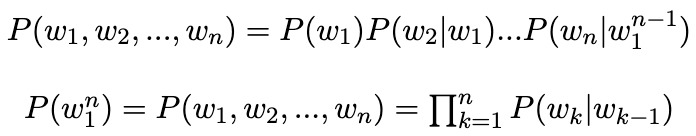
We will calculate P(wn | wn-1) by the Maximum Likelihood Estimation (MLE) method. To calculate MLE for parameters of Bi-gram model, we normalize the counts of Bi-gram which we desire, with the counts of all the Bi-gram which has the first word as wn-1.
So,

We will introduce two special markers for marking the start of the sentence and end of the sentence, <s> and </s >, respectively.
For example, if we have three sentences,
<s> He is Shubham </s>
<s> Shubham He is </s>
<s> He doesn’t like chicken and cheese </s>
Then we have the following probabilities.
- P (He | <s>) = 1/3
- P (</s> | Shubham) = 1/2
- P (Shubham | <s>) = 1/3
- P (doesn′t | He) = 1/3
For general N-gram model,
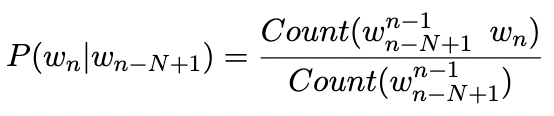
Evaluation of Language Models
The three methods of evaluation are:
- Extrinsic evaluation
- Intrinsic evaluation
- Perplexity (PP)
Extrinsic Evaluation
In this approach, a language model's quality is assessed by integrating it into a complete application and measuring the improvement in the application's overall performance. This evaluation strategy is known as the end-to-end evaluation method. While effective in providing real-world insights, running large NLP systems in an end-to-end manner can be computationally intensive and costly. So we use intrinsic way of evaluation for such cases.
Intrinsic Evaluation
In this evaluation method, a language model is assessed by training it on a dataset (the training corpus) to learn probability distributions over sequences of words. The model's performance is evaluated on a separate test set that contains data the model has not seen during training. It is essential that no sentences from the test set appear in the training data. If there is overlap, the model may simply memorize and assign high probabilities to those sentences, leading to an unrealistic estimate of performance on truly unseen data. Instead of calculating P(w1, w2, ..., wN) we calculate log(P(w1, w2, ..., wN)) because as the number of words in the sequence increases and since all the probabilities are in between 0 and 1, so the value of P(w1, w2, ..., wN) becomes too low that an underflow occurs on the computer. That is why we calculate log(P(w1, w2, ..., wN)).
Perplexity (PP)
Perplexity of a language model on a test set W = w1, w2, ..., wn is defined as,
PP(W) = P (w1, w2, ..., wN )-1/N
Using the test set during training introduces high bias, which causes the model to assign disproportionately high probabilities to familiar data. This results in artificially low perplexity scores, which can give a misleading impression of model quality. In general, lower perplexity indicates a better language model, as it suggests the model predicts unseen data more effectively. We can think of perplexity in another way also: Weighted average branching factor. The branching factor of a language refers to the number of possible words that can follow a given word in a sequence. Suppose we want to recognize the digits in English (zero, one, two, ... ten). Suppose we are also given that probability of occurring of each of the 10 digits is 1/10. Then the perplexity of this small version of language is 10. You can see this by assuming we have string of digits of length N. Then, we will have
PP(W) = P (w1, w2, ..., wN )-1/N
PP(W) = P (1/10N)-1/N = 10
Generalization and Zeroes (Sparsity)
Generalization
Our n-gram model is dependent on training corpus. This fact has the following implications:
- Probabilities that we calculate, many times encode specific facts about a given training corpus.
- Performance of the n-gram model increases as we increase the value of N.
Let me illustrate how to generate bigrams. Suppose the words of the English language cover a probability space between 0 and 1, where the intervals assigned to each word are proportional to their frequencies. First, generate a random bigram starting with <s> and ending with w. Next, generate a bigram starting with w, and continue this process to create longer sentences. We can observe how the performance of the model improves as we increase N by examining the results generated on Shakespeare’s corpus (refers to the collected works of William Shakespeare, often used in NLP research as a dataset of literary English) and the Wall Street Journal corpus (a collection of articles and text from the Wall Street Journal, commonly used in computational linguistics as a source of contemporary, formal written English for training and evaluating language models).
Sparsity
In a given corpus, if an n-gram occurs a sufficient number of times, then we may get a good estimate of its probability. However, there may still be some sequences of words that are perfectly acceptable in the English language but do not appear in the corpus. For these missing word sequences, we have to assign zero probabilities, even though they should, in reality, have some non-zero probability. For example, suppose our test corpus contains the following four 3-grams with their frequencies as shown below:
"talked about politics" occurs 5 times
"talked about sports" occurs 2 times
"talked about healthcare" occurs 1 time
"talked about economics" occurs 1 time
But if our test set contains:
talked about food
talked about government
Our model will estimate P(food | talked about) = 0, which is wrong.
Things that do not occur in the training set but appear in the test set are called zeroes. These zeroes create problems because:
- We underestimate the probabilities of all words that could have occurred, which reduces the performance of the application we want to run on this data.
- If any word in the test set has a probability of zero, the entire probability of the test set becomes zero. As a result, we cannot calculate perplexity.
Unknown Words <UNK>
Until now, we assumed that our training set only contained words from a predefined vocabulary. But in practice, the training data often includes words that are not in our existing vocabulary. To handle this, we use a special token <UNK> to represent all unknown words. We can estimate probabilities for unknown words in two main ways.
First, convert the problem into a closed vocabulary problem:
- Choose a vocabulary and fix it in advance.
- During text normalization, convert any word in the training set that is not in the vocabulary into the unknown word token .
- Estimate the probabilities of unknown words from their counts, just as we do for other words in the training set.
Second, we do not fix the vocabulary in advance but instead build it implicitly during training:
- Replace low-frequency words in the training set with the
<UNK>token based on their occurrence. - For instance, if we have a vocabulary of 10,000 words, we can retain only the top N most frequent words and replace the rest with
<UNK>. - Alternatively, define a frequency threshold: any word in the training set occurring less than that threshold is replaced with
<UNK>.
The way we model <UNK> significantly impacts perplexity. A smaller vocabulary can lead to lower overall probabilities and higher probabilities assigned to unknown words. As a result, to fairly compare perplexity across different language models, it's important to use the same vocabulary for all models.
References
- Speech and language processing. (n.d.). https://web.stanford.edu/~jurafsky/slp3/
- COMS E6998-3: Machine Learning for Natural Language Processing. (n.d.). https://www.cs.columbia.edu/~mcollins/courses/6998-2011/index.html
Opinions expressed by DZone contributors are their own.
Comments