Navigating the LLM Landscape: A Comparative Analysis of Leading Large Language Models
Here is an in-depth analysis comparing top LLMs, including OpenAI and its exciting contenders like LangChain, Anthropic, Cohere, Google, and more.
Join the DZone community and get the full member experience.
Join For FreeAs the demand for advanced natural language processing capabilities continues to surge, the emergence of large language models (LLMs) has become a pivotal milestone in the field. With the rapid advancement of AI technology, LLMs have revolutionized the way we interact with text, enabling us to communicate, analyze, and generate content with unprecedented sophistication. In this in-depth analysis, we delve into the world of leading LLMs, exploring their capabilities, applications, and performance. Our comparative analysis not only includes renowned OpenAI models but also sheds light on other noteworthy contenders such as LangChain, Anthropic, Cohere, and Google.
Join us as we unravel the fascinating landscape of LLMs, uncover their unique features, and ultimately help you make informed decisions by harnessing the power of natural language processing systems.
Meet the Leading Large Language Models
We invite you to meet the leading large language models that are shaping the landscape of artificial intelligence. These remarkable models possess extraordinary capabilities in comprehending and generating text, setting new standards in natural language processing.
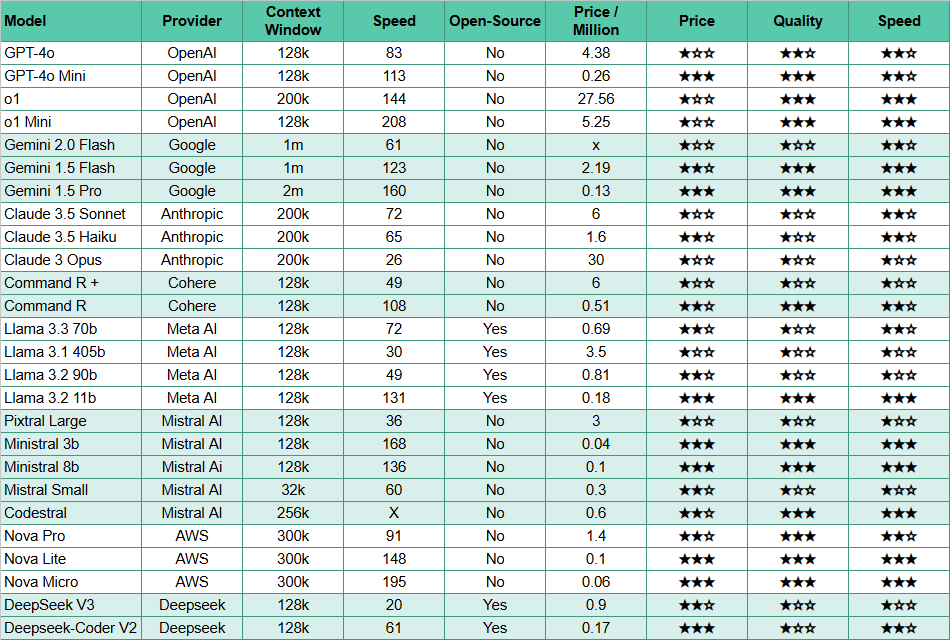
A more detailed version of this leaderboard can be found here.
Now, let's examine each of these models in more detail.
OpenAI
OpenAI, a frontrunner in the field of artificial intelligence, has carved a remarkable path in advancing the boundaries of human-like language processing.
OpenAI released numerous influential language models, including the entire GPT family such as GPT-3 and GPT-4, which power their ChatGPT product, that have captured the imagination of developers, researchers, and enthusiasts worldwide.
OpenAI models have garnered attention for their impressive features and state-of-the-art performance. These models possess remarkable capabilities in natural language understanding and generation. They excel at a wide range of language-related tasks, including text completion, translation, question-answering, and more.
The GPT family of models, including GPT-4 and GPT-3.5 Turbo, has been trained on internet data, codes, instructions, and human feedback, with over a hundred billion parameters, which ensures the quality of the models.
The GPT-4o model family is designed for seamless human-computer interaction. With its omnidirectional capabilities stemming from native multimodality, GPT-4o can process a variety of inputs including text, audio, image, and video, and generate corresponding outputs. It boasts remarkable speed, responding to audio inputs in milliseconds. Notably, GPT-4o matches GPT-4 Turbo's performance in English text and code, excelling further in non-English languages, all while being significantly faster and more cost-effective.
OpenAI's o1 model family, introduced in September 2024, represents a major leap in AI reasoning, particularly in complex problem-solving across mathematics, coding, and science. The family includes o1-preview, which performs at PhD-level proficiency in subjects like physics and chemistry, scoring 83% on the American Invitational Mathematics Examination, and o1-mini, a faster, more cost-effective version optimized for coding and STEM tasks at 80% lower cost. These models leverage reinforcement learning to improve step-by-step reasoning and error correction, making them significantly more capable than previous AI systems. OpenAI's o1 models mark a shift toward AI that "thinks" before responding, enabling more advanced, human-like problem-solving.
OpenAI provides different usage options through their API, including fine-tuning, where users can adapt the models to specific tasks or domains by providing custom training data. Additionally, options like temperature and max_tokens control the output style and length of the generated text, allowing users to customize the behavior of the models according to their specific needs.
OpenAI has pioneered the development of Reinforcement Learning from Human Feedback (RLHF), a technique that shapes the behavior of their models in chat contexts. RLHF involves training AI models by combining human-generated feedback with reinforcement learning methods. Through this approach, OpenAI's models learn from interactions with humans to improve their responses.
In terms of performance, OpenAI models often achieve top-tier results in various language benchmarks and evaluations. However, it's important to note that the performance and capabilities of OpenAI models can vary depending on the specific task, input data, and the fine-tuning process.
Google, a global technology giant, has developed several pioneering large language models (LLMs) that have reshaped the landscape of natural language processing.
Google has introduced the Gemini model family, out of which the Gemini Ultra model outperforms the OpenAI’s GPT-4 model in most benchmarks, providing support for not only textual data but also image, audio, and video data, natively. Following that, Google has developed the Gemma family of lightweight, state-of-the-art open models, which was built by the same research and technology that formed the basis of the Gemini models.
We encourage you to explore the Hugging Face hub for the available models developed by Google.
Google's Gemini models represent the company’s latest advancement in artificial intelligence, providing flexibility and scalability. The latest Gemini models come in two sizes - Gemini 1.5 Pro, their best model for general performance with a huge context length of 1m tokens and Gemini 1.5 Flash is their lightweight model optimized for speed, efficiency, and cost.
What sets Gemini apart is its native multimodal design, enabling seamless understanding and reasoning across diverse inputs like text, images, and audio. Gemini's sophisticated reasoning capabilities make it proficient at extracting insights from vast amounts of data in fields from science to finance. Gemini excels in explaining complex reasoning, especially in subjects like math and physics. Gemini also emerges as a leading foundation model for coding.
Gemma models, derived from the technology behind Gemini, offer top-tier performance relative to their sizes compared to other open models. They can run seamlessly on developer laptops or desktops, surpassing larger models on crucial benchmarks while maintaining our strict standards for safe and ethical outputs.
Anthropic
Anthropic is an organization that seeks to tackle some of the most profound challenges in artificial intelligence and shape the development of advanced AI systems. With a focus on robustness, safety, and value alignment, Anthropic aims to address critical ethical and societal considerations surrounding AI.
In 2024, Anthropic introduced the next generation of Claude. The Claude 3 models can facilitate open-ended conversation, collaboration on ideas, coding tasks, working with text, and processing and analyzing visual input such as charts, graphs, and photos.
The Claude 3 model family offers three models listed here in ascending order of capability and cost: Haiku, Sonnet, and Opus.
-
Claude 3 Haiku is the fastest and most compact model as compared to the other Claude 3 models.
-
Claude 3 Sonnet provides a balance between capability and speed. It is 2x faster than Claude 2 and Claude 2.1 with higher quality output.
-
Claude 3 Opus is the most capable out of all Claude 3 models and outperforms other LLMs on most of the common evaluation benchmarks for AI systems.
The key features of Claude 3 models include multilingual capabilities, vision and image processing, and steerability and ease of use.
Anthropic's Claude 3 models utilize a feature known as constitutional AI, which involves a two-phase process: supervised learning and reinforcement learning. It addresses the potential risks and harms associated with artificial intelligence systems utilizing AI feedback. By incorporating the principles of constitutional learning, it aims to control AI behavior more precisely.
Cohere
Cohere, an artificial intelligence research company, bridges the gap between humans and machines, focusing on creating AI technologies that augment human intelligence.
Cohere has successfully developed Command models that excel at interpreting instruction-like prompts and exhibit better performance and fast response.
The Command R model enhances the capabilities of the original Command model with a focus on retrieval-augmented generation. These models are particularly adept at generating contextually relevant responses by integrating retrieval mechanisms that pull information from external databases or documents. This improvement allows the Command R model to provide more accurate and contextually appropriate outputs.
The Command R Plus model combines the robust natural language generation and retrieval capabilities of the Command R model with additional enhancements for performance and accuracy. It is designed to excel in demanding environments where precision and contextual relevance are paramount.
Meta AI
Meta AI, an artificial intelligence laboratory, has released large language models including Llama 3, and Code Llama.
Llama 3 model family showcases notable advancements in AI technology. These open source models excel in language understanding, programming, mathematical reasoning, and logic, outperforming previous iterations and rival models. Through extensive training and cutting-edge techniques, the Llama 3 models deliver superior performance across various tasks. Designed for versatility and efficiency, they offer reliable solutions for natural language processing and complex problem-solving scenarios.
Code Llama models are designed to excel in code understanding, generation, and related programming tasks. With extensive training data and state-of-the-art techniques, the Code Llama models demonstrate exceptional performance across a range of programming languages and tasks. From code completion to bug detection, these models provide accurate and efficient solutions to programming challenges.
Mistral AI
Mistral AI, a Paris-based AI company, has recently gained prominence in the AI sector. Positioned as a French counterpart to OpenAI, Mistral distinguishes itself by emphasizing smaller models with impressive performance metrics. Some of Mistral's models can operate locally, featuring open weights that can be freely downloaded and utilized with fewer restrictions compared to closed AI models from competitors like OpenAI.
Mistral 7B is a 7.3 billion-parameter model that showcases strong performance across various benchmarks. Notably, it outperforms Llama 2 13B on all benchmarks and surpasses Llama 1 34B on many. While excelling in English tasks, Mistral 7B approaches CodeLlama 7B performance on coding-related tasks. This model is optimized for faster inference through Grouped-query attention (GQA) and efficiently handles longer sequences at a smaller cost with Sliding Window Attention (SWA). Released under the Apache 2.0 license, Mistral 7B can be freely used without restrictions. Users can download and use it locally, deploy it on cloud platforms like AWS, GCP, or Azure, and access it on HuggingFace. Additionally, Mistral 7B is easily fine-tuned for various tasks, demonstrated by a chat model that outperforms Llama 2 13B in chat-related applications.
Mixtral 8x7B is a Sparse Mixture of Experts model (SMoE) with open weights, licensed under Apache 2.0. With remarkable capabilities, Mixtral outperforms Llama 2 70B on most benchmarks, offering 6x faster inference and establishing itself as the strongest open-weight model with an advantageous cost/performance profile. Particularly noteworthy is its competitive performance against GPT3.5 on standard benchmarks. Mixtral has been pre-trained on data from the open web. It excels in handling a context of 32k tokens and supports multiple languages, including English, French, Italian, German, and Spanish. It demonstrates robust performance in code generation and can be fine-tuned into an instruction-following model. Mixtral operates as a sparse mixture-of-experts network, employing a decoder-only model with a unique feedforward block that selects from 8 distinct groups of parameters. With 46.7B total parameters but only using 12.9B parameters per token, Mixtral achieves input processing and output generation at the speed and cost of a 12.9B model.
Mixtral 8x22B is a larger Sparse Mixture of Experts model (SMoE) from Mistral AI with open weights, licensed under Apache 2.0. it leverages up to 141B parameters but only uses about 39B during inference, leading to better inference throughput at the cost of more vRAM. It has a context length of 64k. Mixtral 8x22B is a larger and better version of Mixtral 8x7B and outperforms it on most tasks while also remaining cheap and quick.
Mistral Small, Medium & Large are the 3 proprietary models by Mistral AI only available for use through the Mistral AI Platform. They all have an input length of 32k tokens and have different tradeoffs between speed, quality, and cost. Mistral small is suitable for simple tasks that one can do in bulk (Classification, Customer Support, or Text Generation). Mistral medium is ideal for intermediate tasks that require moderate reasoning (Data extraction, Summarizing a Document, Writing emails, Writing a Job Description, or Writing Product Descriptions). Mistral large is Mistral AI’s flagship model that's ideal for complex tasks that require large reasoning capabilities or are highly specialized (Synthetic Text Generation, Code Generation, RAG, or Agents).
AWS
AWS (Amazon Web Services), a leader in cloud computing, has expanded its AI offerings with advanced Nova and Titan model series, providing state-of-the-art AI capabilities through Amazon Bedrock.
The AWS Nova series represents Amazon’s latest generation of high-performance large language models. Designed for enterprise-scale AI applications, Nova models excel in natural language understanding, generation, and reasoning tasks. These models are optimized for efficiency, allowing faster inference and lower latency while maintaining high accuracy. The Nova series is built with deep contextual awareness, making it well-suited for applications requiring in-depth analysis, summarization, and conversational AI.
In addition to the Nova models, AWS offers the Titan model family, which includes Titan Text for natural language generation and Titan Image for AI-powered visual content creation. AWS models integrate seamlessly with the broader AWS ecosystem, including Amazon S3, Lambda, SageMaker, and Bedrock, enabling scalable and secure AI deployments.
DeepSeek
DeepSeek, an emerging AI research organization from China, has gained recognition for its high-performance large language models that emphasize efficiency, multilingual capabilities, and powerful reasoning.
DeepSeek has introduced a series of DeepSeek LLMs, designed to compete with state-of-the-art language models in natural language understanding, generation, and coding tasks. The DeepSeek Coder model is optimized for programming-related applications, showcasing strong performance in code generation, completion, and debugging across multiple programming languages. Additionally, DeepSeek models emphasize cost-effective deployment with optimized inference speeds and lightweight architectures that maintain high performance.
DeepSeek’s models have been trained on a diverse dataset, covering multiple domains, and offer competitive benchmarks against leading closed and open-source LLMs. The models support multilingual tasks, making them valuable for global AI applications.
Published at DZone with permission of Jorge Torres. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments