Building a Graph Database Wannabe (Part 1)
Learn how I built Uranus DB, a graph database wannabe, in five to seven days and about ten bucks worth of Diet Dr. Pepper.
Join the DZone community and get the full member experience.
Join For FreeLast year, Microsoft announced Cosmos DB, a multi-modal database with graph support. I think multi-modal databases are like Swiss army knives — they can do everything, just not very well. I imagine you would design it to be as good as it can be in its main use case while not losing the ability to do other things. So it's neither fully optimized for its main thing nor very good at the other things. Maybe you can do pretty well with two things by making a few compromises, but if you try to do everything... it's just not going to work out.
Can you imagine John Rambo stalking his enemies with an oversized Swiss army knife? Here, let me help with the mental image:

Yeah... not super effective, and definitely not nearly as cool. Sometimes, you need a screwdriver and sometimes, you need a scary-looking big ass knife. But instead of looking at the cosmos, let's focus in on our own solar system.
A few weeks ago, Amazon announced Neptune, their RDF/graph database hybrid. That's two big players announcing graph-capable databases within months of each other. There are a bunch of small players also bringing graph databases to market.
Yeah, well, I'm gonna go build my own graph database with hook ...wait, hold on.
According to database industry analyst Curt Monash, there are two cardinal rules of DBMS development:
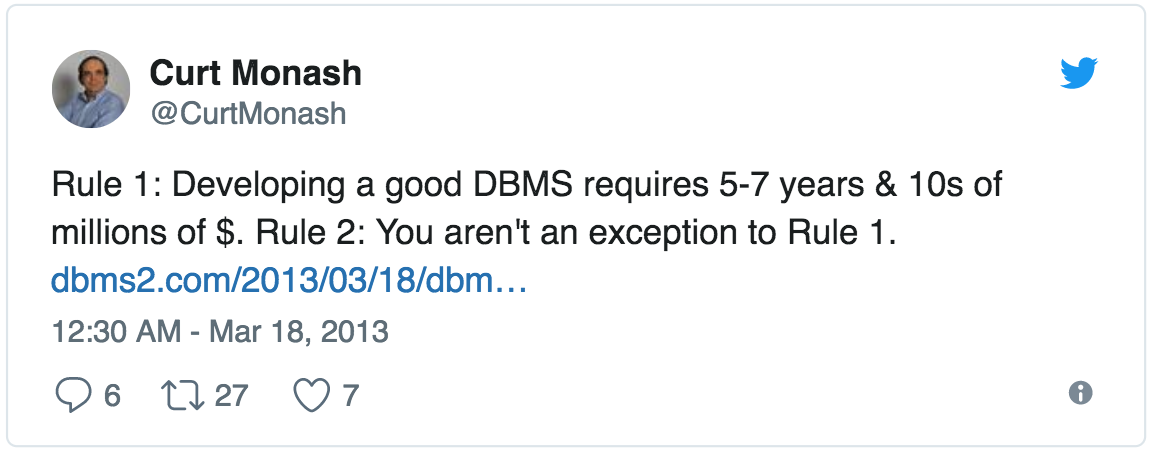
How long have Amazon and Microsoft been working on these databases? How much money do those smaller players have? Hm... yeah, good luck deploying your mission-critical graph database-backed applications on those platforms... you'll need it. But to be fair, someone had to take a chance on Neo4j once, too.
But forget about them; if I was building a new graph database today, I would start by watching all these videos and actually paying attention this time, then write it in C++ with SeaStar. It would be "in memory" because 99% of all operational databases fit in memory. It would be serializable because, once again, 99% of all operational databases don't need more speed than a single core of a machine can handle. It would just log write queries instead of changes to the store. So an update one property query and an update 1M properties query would both just write the query, not all the changes. I would avoid locking and latching and try to follow some of the same ideals as VoltDB, as explained by Stonebraker on this video presentation. It's an hour long, but there is a TLDR version:
However, I don't have five to seven years to spare, or tens of millions of dollars. But as DHH says, constraints are our friends. So I built Uranus DB, a graph database wannabe, in five to seven days and about ten bucks worth of Diet Dr. Pepper. I say five to seven days because I honestly can't remember since most of the time I was drugged up on pain meds from my (second) heel surgery. Some people get allergic reactions; I write databases.
I am calling it Uranus because that is the girlfriend of Neptune in the Sailor Moon anime and frankly because I wanted to make the joke that Amazon's Neptune is just behind Uranus.

If you are a casual reader, you can probably laugh, stop here, and go do something productive with your life. But if you are trying to decide if I am an idiot or a madman to write thousands of lines of code to make a joke, then continue on.
I am not going to go over the whole thing line by line (you can read the code yourself if you want to see what code on drugs looks like), but I do want to go over some things. In the center, there is a Graph API that looks and feels a lot like the Neo4j Java API. Underneath that is a mess of data structures mostly coming from fastutil. The real workhorse is a ReversibleMultiMap that houses the node relationship combinations. To the side of the Graph API is UranusGraph, a layer that implements the Tinkerpop Graph API so we can run Gremlin on Uranus.
As a side note: Yes, it really only takes about a week to add Gremlin to a database (badly, but tests still pass). It's really easy to add, and that's why everybody supports it... the problem is that it takes much longer and it is much harder to learn Gremlin itself. Sure, Marko, Stephen, and a handful of people know it well... but how many genius-level developers work for your company?
On top is an HTTP API that resembles the Neo4j REST API, but not really. A UranusServer running on top of Undertow takes requests and passes them off to a Disruptor that processes each item serially. The first handler persists write queries to a ChronicleQueue (which I would repurpose for replication and recovery if I get around to it) and then the second handler forwards the request to a series of actions which call the Graph API, serialize the answer, and reply. Still with me? Ha!
First, I realized that most of the time, I want quick access to a node by something I know about it. We call these Anchor nodes in our queries, where we parachute into the graph and then radiate outwards looking for whatever pattern we are interested in. So, I made it mandatory that all nodes have a single Label and a Key. For a User node, it may be that the key is their username property, for example. For nodes that don't have a key, a random GUID would work, but of course, it would no longer be easy to remember how to get to it. Maybe a hash of properties would work... you decide. I am going to go small and just use integers as IDs for my Nodes and Relationships. I could have used longs, but that would have complicated some of the pieces, you'll see. The Nodes part of the API looks like this:
int addNode(String label, String key);
int addNode(String label, String key, Map<String, Object> properties);
boolean removeNode(String label, String key);
Map<String, Object> getNode(String label, String key);
int getNodeId(String label, String key);
Map<String, Object> getNodeById(int id);
String getNodeLabel(int id);
String getNodeKey(int id);Naturally, I wanted this concept to extend to Relationships, but they rarely if ever have a natural key. Instead, most of the time, I can point to a relationship by the two nodes it connects and the type. So I made the getRelationship method take a type and the label and keys of both nodes as parameters. This makes sense because most of the time, the relationship between nodes is unique. I FOLLOW this person on Twitter only once. I am a FRIEND of another person just once. We see this manifested in Neo4j by the massive amount of MERGE queries trying not to duplicate relationships between nodes.
But there is one small problem with this plan... what if two nodes are connected by the same relationship type more than once? Can I RATE a Movie more than once? Is that a second relationship or am I updating the first one? I can certainly WATCH a Movie more than once, and I definitely LISTEN to a Song more than once. So my choices are: allow only a single relationship of each type between nodes or simply add a "number" to the relationship API on access. So the Relationship part of the API looks like this:
int addRelationship(String type, String label1, String from, String label2, String to);
int addRelationship(String type, String label1, String from, String label2, String to, Map<String, Object> properties);
boolean removeRelationship(int id);
boolean removeRelationship(String type, String label1, String from, String label2, String to);
boolean removeRelationship(String type, String label1, String from, String label2, String to, int number);
Map<String, Object> getRelationship(String type, String label1, String from, String label2, String to);
Map<String, Object> getRelationship(String type, String label1, String from, String label2, String to, int number);
Map<String, Object> getRelationshipById(int id);One of the things I like about the Neo4j API that was introduced in the last couple of years is the ability to quickly fetch the degree of a node. In Neo4j if a node has less than 40 relationships, it just counts them. If it's a "dense" node with 40 or more relationships, we store the count by type in the relationship group chain of each node. So, I added a Node Degree part to the API... and yeah, it is missing the by ID access.
int getNodeDegree(String label, String key);
int getNodeDegree(String label, String key, Direction direction);
int getNodeDegree(String label, String key, Direction direction, String type);
int getNodeDegree(String label, String key, Direction direction, List<String> types);For Traversals, sometimes, I want the properties of the relationships I am traversing and other times, I want the relationship IDs. Other times, I simply want the node IDs at the other side of the relationships and sometimes, I want the nodes on the other side. So, my Traversal part of the API looked like:
List<Map<String, Object>> getOutgoingRelationships(String label1, String from);
List<Map<String, Object>> getOutgoingRelationships(int from);
List<Map<String, Object>> getOutgoingRelationships(String type, String label1, String from);
List<Map<String, Object>> getOutgoingRelationships(String type, int from);
List<Integer> getOutgoingRelationshipIds(String label1, String from);
List<Integer> getOutgoingRelationshipIds(int from);
List<Integer> getOutgoingRelationshipIds(String type, String label1, String from);
List<Integer> getOutgoingRelationshipIds(String type, int from);
List<Integer> getOutgoingRelationshipNodeIds(String type, String label1, String from);
List<Integer> getOutgoingRelationshipNodeIds(String type, Integer from);
Object[] getOutgoingRelationshipNodes(String type, String label1, String from);
Object[] getIncomingRelationshipNodes(String type, String label2, String to);Wait. Why are my Relationships Lists of Maps and my Nodes Object Arrays? I probably screwed up there. Anyway, moving on. I also wanted to be able to iterate over all the nodes and relationships (or their IDs) and by type or label... so:
Iterator<Map<String, Object>> getAllNodes();
Iterator getAllNodeIds();
Iterator<Map<String, Object>> getNodes(String label);
Iterator<Map<String, Object>> getAllRelationships();
Iterator getAllRelationshipIds();
Iterator<Map<String, Object>> getRelationships(String type);Lastly, I wanted to quickly check if two nodes were related by type and direction, so I threw that in there, as well.
boolean related(String label1, String from, String label2, String to);
boolean related(String label1, String from, String label2, String to, Direction direction, String type);
boolean related(String label1, String from, String label2, String to, Direction direction, List<String> types);Let's look at the implementation and start with the Nodes. I want to be able to get to a node quickly, so I store an ArrayMap of HashMaps of Strings (Object2IntMap) to accomplish this. The outer ArrayMap has the Label of the nodes as the key, and then the keys of the internal HashMaps are the keys of my nodes. The int stored as the value is the ID of the Node I want. The properties of the nodes are stored in an Array as a Map. Once set, the location of a node doesn't change, any deleted nodes are set to null but kept and a RoaringBitmap keeps track of what nodes are deleted so they can be reused when new nodes are created.
private Object2ObjectArrayMap<String, Object2IntMap<String>> nodeKeys;
private ObjectArrayList<Map<String, Object>> nodes;
private RoaringBitmap deletedNodes;The relationships are a bit more complicated. Remember how I mentioned I wanted to be able to quickly check if a relationship exists between two nodes? But I can have many relationships of the same type between two nodes... so I have a Map that combines the relationship type and count as the key. So the majority of the time they would end in "1" like "FRIEND-1", but sometimes you would have "LISTEN-1", "LISTEN-2", and "LISTEN-3" as keys to keep track of multiple relationships of the same type between nodes. The value is a HashMap of Long2Int. So the key is a long with the from node ID and to node ID (which are both ints) squished into a long, and the value is the actual relationship. Is that insane? Just buy more RAM. I also wanted to keep track of all the relationship counts by type... that one was easy enough:
private Object2ObjectArrayMap<String, Long2IntOpenHashMap> relationshipKeys;
// relKey.put(((long)node1 << 32) + node2, id); <-- squish
private Object2IntArrayMap<String> relationshipCounts;The properties of the relationships are kept in a big Array of Maps just like the nodes, with a matching RoaringBitmap for the deleted ones. To keep track of how many relationships of the same type between two nodes I have, I have relatedCounts which uses the same squish technique as the key and stores the count as the value. I probably could have rolled it into relationshipKeys using a special key like "{type}-count", but it's fine.
private ObjectArrayList<Map<String, Object>> relationships;
private Object2ObjectArrayMap<String, Long2IntOpenHashMap> relatedCounts;
private RoaringBitmap deletedRelationships;Now, we get to related. This is a Map of ReversibleMultiMaps. The key is just the relationship type. The value is a lie.
private Object2ObjectOpenHashMap<String, ReversibleMultiMap> related;Inside each ReversibleMultiMap are actually four Multimaps. One pair stores the node to node IDs and their reverse; the other pair stores the node to relationship IDs and their reverse. I do this because sometimes I just want node IDs, other times, I want relationship IDs, and sometimes, I need the whole relation object (which fetches it from the relationships array by ID).
private Multimap<Integer, Integer> from2to = ArrayListMultimap.create();
private Multimap<Integer, Integer> from2rel = ArrayListMultimap.create();
private Multimap<Integer, Integer> to2from = ArrayListMultimap.create();
private Multimap<Integer, Integer> to2rel = ArrayListMultimap.create();Let's walk through just two methods, adding a node and adding a relationship to the graph. We start addNode by getting or creating the Object2IntOpenHashMap of the label for our new Node. If this Label-Key combination already exists, we exit with a -1. Otherwise, we add the label and key as "hidden" properties to the node. We then check the deletedNodes bitmap to reuse an ID and find the size of our node array. Using either one as our ID, we include the id as another "hidden" property and insert it into the nodes array. Then we add the label-key-id combination to our nodekeys and return the newly created node ID.
public int addNode (String label, String key, Map<String, Object> properties) {
Object2IntMap<String> nodeKey = getOrCreateNodeKey(label);
if (nodeKey.containsKey(key)) {
return -1;
} else {
properties.put("~label", label);
properties.put("~key", key);
int nodeId;
if (deletedNodes.isEmpty()) {
nodeId = nodes.size();
properties.put("~id", nodeId);
nodes.add(properties);
nodeKey.put(key, nodeId);
} else {
nodeId = deletedNodes.first();
properties.put("~id", nodeId);
nodes.set(nodeId, properties);
nodeKey.put(key, nodeId);
deletedNodes.remove(nodeId);
}
return nodeId;
}
} In our addRelationship method, we first find the node IDs for the from and to nodes or error out if we can't find them. We add a new ReversibleMultiMap to related if this is a new relationship type. We increment our relationshipCounts by one. Then, we see how many relationships of this type between these two nodes exist and increment that by one. Then we set the ID by getting the relationship size... we should have checked deleted relationships here, I'll fix it later. Next, the hidden properties get added and then the properties map gets added to relationships. We update the relatedCount, add our relationship to related ReversibleMultiMap, and add our relationship to relationshipKeys.
public int addRelationship(String type, String label1, String from, String label2, String to) {
int node1 = getNodeKeyId(label1, from);
int node2 = getNodeKeyId(label2, to);
if (node1 == -1 || node2 == -1) { return -1; }
related.putIfAbsent(type, new ReversibleMultiMap());
relationshipCounts.putIfAbsent(type, 0);
relationshipCounts.put(type, relationshipCounts.getInt(type) + 1);
relatedCounts.putIfAbsent(type, new Long2IntOpenHashMap());
Long2IntOpenHashMap relatedCount = relatedCounts.get(type);
long countId = ((long)node1 << 32) + node2;
int count = relatedCount.get(countId) + 1;
int id = relationships.size();
HashMap<String, Object> properties = new HashMap<>();
properties.put("~incoming_node_id", node1);
properties.put("~outgoing_node_id", node2);
properties.put("~type", type);
properties.put("~id", id);
relationships.add(properties);
relatedCount.put(countId, count);
related.get(type).put(node1, node2, id);
addRelationshipKeyId(type, count, node1, node2, id);
return id;
} That is a ton of stuff to keep track off. I think the worst thing is deleting a node because you have to delete all its relationships as well. Take a look at the source code if you are interested.
My dog Tyler is right next to me and just farted the nastiest fart. I think this is a good place to stop for now. I'll continue to Part 2 soon.

Published at DZone with permission of Max De Marzi. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments