New StackPod Episode: Implementing an SRE Practice
We invited Hyke’s Yousef Sedky. Yousef shares his insights about his journey while building an infrastructure from scratch and implementing SRE practice.
Join the DZone community and get the full member experience.
Join For Free
For our latest StackPod episode, we invited Hyke’s DevOps team lead and AWS Cloud architect: Yousef Sedky. Axiom Telecom is one of the largest telephone retailers in the United Arab Emirates and Saudi Arabia, and Hyke, its sister company, is a distribution platform for mobile products.
Yousef joined Hyke about 2.5 years ago. His first challenge was to build the architecture from scratch, which was a great experience for him. "All the logistics you don't know about when you're in a corporate company, you come to do it by yourself in a startup company," says Yousef. Yousef and his team learned a lot about DevOps principles and how to incorporate them into their practice, like CI/CD, infrastructure as code, production control, security, centralized logging and monitoring.
At the same time, Hyke was growing very fast, so Yousef and his team decided to implement the SRE practice so they could continue to deploy quickly. “We started to go deep on learning,” says Yousef. “How do other companies do it? Big companies like Amazon, Facebook, and Google are deploying to production with zero downtime. They could actually be deploying multiple releases without us even knowing.”
In this episode, Yousef shares his insights and learning with host Anthony Evans about his journey while building an infrastructure from scratch and implementing an SRE practice:
- How did Yousef and his team implement DevOps concepts in the most productive way; instead of just doing what everybody else does?
- What steps did they take to implement an SRE practice from scratch?
- How did they decide what tools to use?
- How did Yousef and his team make sure the rest of the organization was on board with the SRE practice?
- What does infrastructure as code mean, and why did they introduce it?
During the episode, Yousef talks about their SRE MindMap that is revised from time to time. They take a new part of it and then customize it into their Hyke stack.
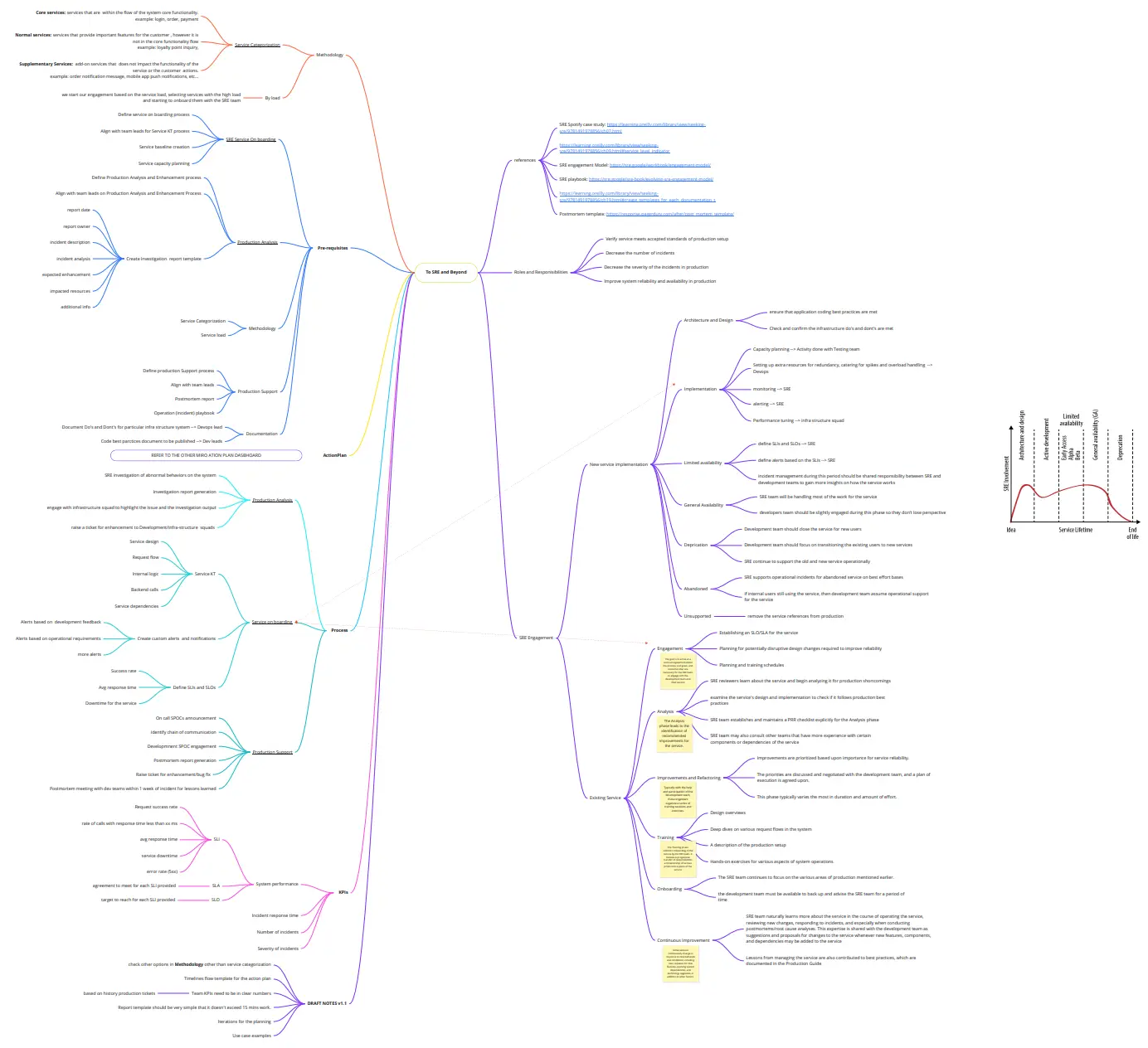
Finally, here are some useful links that Yousef shared with us if you want to implement an SRE practice into your organization:
- Spotify’s SRE Case Study
- Google’s SRE Playbook
- The SRE Engagement Model by Google
- Do Docs Better: Integrating Documentation into the Engineering Workflow
- Postmortem Template
Episode Transcript
Yousef (00:00): Why don't we spare some 10% or 20% of our sprint planning, trying to assign some areas where we can do improvement. It requires some patience, but what I see from my experience, it has very good reasons to do that."
Annerieke (00:18): Hey there, and welcome to the StackPod. This is the podcast where we talk about all things related to observability because that's what we do, and that's what we're passionate about, but also what it's like to work in the ever-changing, dynamic tech industry. So if you are interested in that, you are definitely in the right place.
Annerieke (00:36): So today, we invited Yousef Sedky. Yousef is a DevOps team lead and AWS Cloud architect at Axiom and its sister company Hyke. Axiom Telecom is one of the largest telephone retailers of the United Arab Emirates and Saudi Arabia, and Hyke, its sister company, is a distribution platform for mobile products. Yousef joined Hyke about 2.5 years ago, and his first challenge was to build the architecture from scratch. At the same time, Hyke was growing very fast, so Yousef decided to implement the SRE practice to make sure they could continue to deploy fast, with zero to minimal downtime. In this episode, Yousef talks to Anthony about his lessons learned while implementing the SRE practice. So how did they decide what their SRE strategy would look like? How did he build the team? How did Yousef and his team make sure the rest of the organization was on board? What are the lessons learned? and much more. So, without further ado, let’s get into it and enjoy the podcast.
Anthony (01:36): Hey everybody, Anthony Evans, here recording the StackPod, the best tech podcast there is by any stretch. But to get into that, let's start by introducing our guest for today. Our guest is Yousef Sedky. I'm going to let Yousef introduce himself and where he works, and what he does. Yousef, go ahead.
Yousef (02:03): Hi Anthony. Thank you very much. My name is Yousef Sedky. I'm working under Hyke company. It's a B2B digital distribution platform based in Dubai. It's a sister company for Axiom Telecom. It's a very well-known company here in UAE and KSA. We are mainly leading in the distribution of mobile products. What we came up with is a complete startup digital transformation.
Yousef (02:33): We are mainly responsible as a B2B solution that connects distributors to dealers. And the platform is actually not restricted to mobile electronics. It actually can absorb multiple product streams. So we started initially in 2019 in mobile products, and we took Axiom as our first customer, a big distributor.
Anthony (02:59): Oh cool.
Yousef (02:59): Yeah. And this was the plan or the strategy for that at that time. So we can see if we can actually prove our product to our first customer, which is Axiom Telecom. Then Hyke started to go into the gaming industries like the CD games and the video games and so on. Is still a B2B distribution as well. And we started initially to step into other projects like FMCG. And we are still exploring each area on this to explore the platform, to absorb different streams in general. So this is mainly Hyke.
Yousef (03:35): My role is actually leading the DevOps area and SRE team, and also responsible on the cloud architecture for the Hyke platform. Me personally, I have worked in the software industry for almost plus ten years. I graduated as a network engineer, and I worked for one year in network field, mainly in Orange, France Telecom then-
Anthony (04:02): The irony of getting a networking degree and now you're a cloud guy where there's literally only configuration, and nobody's running around with networking cables anymore.
Yousef (04:15): Exactly. Yeah. Then I moved to Vodafone. I worked for almost six years and a half in Vodafone. It was a very interesting journey as well. I started as a system engineer for a couple of years, and I became a tech leader in this area. Then it came to us guys; there is something called DevOps coming to the picture. We will build a team called deployment. You guys want to... Who wants to join, and so on. And we took all the risk, and we said, "Okay, let's try this." It were all new technology for us. It was like algorithmic names, Kubernetes, Docker, Kafka, Python.
Anthony (04:54): My dad calls it Kubernaties because he listens to this podcast. And so, now every time I talk to my dad, he's like, "How is the Kubernaties this week?"
Yousef (05:08): Yeah, exactly. So it was actually very new technology to us. We never knew anything about it. The documentation was almost very limited even for us to understand. We started to read a lot on this, and we came to know that Kubernetes came from Google, established from Google, and this is the thin layer that Google actually gave it to the people to work on it. And we liked the idea.
Yousef (05:30): Then we started to learn more about DevOps and DevOps principles and what we want to achieve in a DevOps team. And step by step, we grew the team together, and we worked on multiple projects; major ones, at least on my side, was the eSim. Is the virtual SIM card that you have in your Apple product, Apple watch, or Samsung mobile. Yeah, exactly. I remember Apple used to test with Vodafone almost six months to onboard it in multiple ops at that time. It was a very interesting journey, to be honest. We learned a lot. We understood the principle of DevOps. We also understood the streams that we want to have, like the CI/CD, the infrastructure as a code, the production control, security, centralized logging, monitoring.
Yousef (06:19): Then I moved here in this interesting opportunity of working on a startup company because startups used to grow a lot in the last years, and everyone is building a startup, and it's growing, and I like the idea. Then that's why it made me take my decision to actually move to Dubai here and to join Hyke as a platform. It's very good progress so far. I remember we were like twenty in the room at that time, mainly me and a couple of engineers. Now we grow up a lot. We have almost two zones now. One in the first room, one in the second floor, was full of engineers. We have people in the UAE. We have people based in India.
Yousef (07:05): And it's good because you are building the architecture from scratch. And all the logistics that you don't know about when you're in a corporate company, you came to do it by yourself in a startup company. Starting was even connecting with the vendors and trying to assess the technology stack and so on, you know. That's mainly at the start, and then I, as I already approached you guys, that I want to speak on the SRE because this was my second phase of the journey, is how did we came to build an SRE team and how we are trying to work on the site reliability culture in the organization level and on the team level as well. Yeah.
Anthony (07:47): That's an incredible journey. This, from beginning to end. I have a few questions. So, you mentioned, you know, you kind of were in this position where you were figuring everything out infrastructure as code, you were getting to know these new services, buzzwords, CI/CD, things were coming into play. And your background being in networking, what were some of the key things that helped you successfully incorporate these new concepts and these new technologies in a productive way as opposed to them just being science experiments and doing what everybody does? "Oh, we need to migrate to the cloud because we don't know; it's just what everybody's doing." You know what I mean? It's-
Yousef (08:41): Yeah, exactly. Yeah.
Anthony (08:43): You don't want it to be a science experiment. How did you manage that? And what were some of the things that you did?
Yousef (08:47): Yeah, that's a very good question. Actually, it comes in two ways actually. There is theoretical learning that you, for sure, need to know. You need to have the base, what exactly CI/CD means, and why it's beneficial for the business, for the end user. Why do we need to establish something like this? And the second way is the practical way. We need to have a practical use case for the company that lets us drive this change and to go deep on that. And I was, maybe, one of the lucky guys that these issues were already there and these gaps were already there. We used to have issues in releasing to production, how quickly we go chipping, or maybe time to market. So it came to us that we need to have a proper CI/CD stream here.
Yousef (09:34): And from that point, we started to go deep on learning. Okay, how did the other companies do it? How the big companies like Amazon, Facebook, and Google are actually deploying to production with a zero downtime. And maybe in one day, they could actually deploy multiple releases without even us knowing. When you come to Facebook, you find the like button, they have a face happy there, and you don't know, just as a user, you just refresh and it's up, it's done. So that was very interesting, to be honest, is how to map technically to the end user. How he actually feels that this is happening very quickly and reliably as well without any issues.
Yousef (10:10): So, it leads us to this point. What we amplify, take a CI/CD as an example, "Okay, how can we deploy quicker?" We use the CI/CD. "What kind of tools everyone is using?" Some of the tools, to be honest, we started to assess some tools we didn't know; we said, "Okay, let's try it and let's do POC, and if it works, then we are fine. If it's not, then let's search for a better thing." Then, "Okay, how everyone is deploying now without downtime." We started to see what is zero downtime deployment? What are the methodologies? There is Canary or Blue-green or whatever. And so, the same way we took the rest of the use cases. So when we started new projects, even in Hyke here. So we are building an environment, let's say, a production environment. Okay, the guys need a development environment. It took us the same time to build the same environment. Then when we are doing tests, there could be human errors during testing. Okay, guys this should be something way more robust than this.
Yousef (11:08): And we introduced the infrastructure as a code. What does it mean? It's a centralized code. You're putting all your code, you're putting all your variables across the environment, and you're running it from the same place. I'm reducing the human error that during the implementation, the configuration itself. I'm also having a centralized environment that whenever I need to build a new environment, I'll just add a piece of code and spin quickly. So many use cases that you face plus the theoretical learning that you have as a base. That, what I could see, personally helped me. And later on, we started to develop small exercises that if you want to step in on something new and we don't have a use case for it, okay, let's build a use case and try to see the outcome of it. And if we liked it, let's add it in our stack if it has a business value; if not, then at least we knew that this is something happening on the ground.
Anthony (11:59): Yeah. It's very interesting. You keep bringing everything back to the business, right and talking about business value. And a lot of the time, and this is also getting back to the whole experimentation thing, right and science projects, and, you know, you adopt all these new technologies just because it is what it is. But it sounds like you've really approached a lot of issues based on: is this going to work for the business? In other words, is this going to work for us? Is it going to work for our product? And is it going to work for our bottom line at the end of the day? Is it going to reduce the meantime to resolution? Is it going to improve reliability? Would that be an accurate kind of estimation? Because it sounds to me like you had a lot of time to play and prove things out, like not play, but you know what I mean? Like POC things so that they can work. And that sounds like a luxury, but really, if you're running it from a business standpoint, you're basically saying, "Let's prove if this works or not." Is that an accurate statement?
Yousef (13:06): Yeah, You're right. And some environments and some companies will not give you the chance to do that, to be fair. I understand. But if we are having issues happening concurrently and every time during maybe our deployment, during our planning, even during our... Starting from working Waterfall versus Agile until I'm actually...how I'm deploying in production and how long it takes to release a new feature to production. "Okay, guys, but we have an issue. We keep on repeating it every time when we have an issue. So why don't we spare some 10% or 20% of our sprint planning, trying to assign some areas where we can do improvement. It requires some patience, but what I see from my experience, it has very good reasons to do that." And yeah.
Anthony (13:57): Yeah, I think. Well, it's the old-fashioned thing. When you're younger, and you're looking at cars, I've got kids, so I'm like talking when you're kids. Everything is like a red, green, or a blue car, right? They only look at the color and what's outside. And I think developers get the same way, right? They want the enhancements; they want the shiny things, the things that people notice. Nobody wants to change the oil, right? And that's kind of what it is, right? You need to maintain the car so that it can keep on going because, at the end of the day, it doesn't matter what color it is or how big the engine is. If you're not taking care of it and you don't ensure that it can go the mileage, you're not building something that's going to be ultimately successful. And that's quite hard for a lot of people to adopt.
Yousef (13:40): Exactly. Agreed.
Anthony (14:50): Yeah. So you went over to Hyke. You've taken this experience with you. People should go to your website. You do have a great product that you've got. It's got a great user interface. And I think that's part of the core value proposition, right? Is centralizing everything. Make it a nice experience from either a mobile or from a desktop, whatever it may be, and create value for your customer. And obviously, reliability comes into that. Can you talk to me a little bit about, in more detail, in any case, how you built out the SRE practice from scratch at Hyke and how you got to where you're at today?
Yousef (15:40): Yeah, sure. This actually came back last year, the first start of last year. And to be honest, the idea itself came from my ex-manager, and I want to thank him for this as well. We started the journey originally when we built the platform. Okay, I told him I will focus mainly on the infrastructure monitoring as a start for two reasons. This is the area that I'm expert with. And at that time, due to the budget purposes, and we don't know if the product or the platform itself will succeed or not. But once we did this and the platform actually showed extraordinary results than we expected, and we had even fifteen distributors right now are using our platform. Things started to grow in different ways. We have customer base; we have dealers every day using the mobile app and the tablet, and the web portal, day to day.
Yousef (16:26): So we are actually growing a lot. The microservices, even on a microservice level, we started with 12, 15, 20, 54, 75, 80, and so on. The rate is actually very high, and the technology stack started to grow way bigger. We came to understand that monitoring just as a monitoring solution is not; it will not fit us. The normal monitoring behavior and to have an operations team that does the classical way. Once everything is in production, they start to monitor the new features. And if there's an issue, they will raise it to us. And the hectic process is not actually going to be the best fit for us. So I remember we started to read on the SRE role. It came from Google. We know that Google established this. The only code that I could say that Google engine doesn't fall down. We never hear that Google engine goes down, so how are these guys doing this? So for sure, these are the best people who did this.
Yousef (17:28): So we started to read the model. We started to read their case studies. Even they have an SRE e-book on the internet, we read it all. Then we started to look at case studies who actually used this. One of them was Spotify, if I remember, and Netflix. They took this model, and they mentioned in their technical case that they customized the model based on their own current platform and resources and setup, and so on. Then we find out that not everything could fit for us, at least as a start. So what we did is we hired one SRE engineer. He is actually still with me right now since the start.
Yousef (18:14): And we together, we said, "Okay, let's explore from a knowledge perspective." We built an SRE mind map. So the SRE mind map is actually connecting everything that we read about on this map. And we see at the end of the months, if this is actually going to fit for us? Yes. We take it as a green check. If this is not going to fit for us now let's make a red check and we can look for it later on. Due to the current resources, due to the current stage of the platform and so on. And after the SRE mind map we started to look, okay, now we understood. Now we have the theoretical ways. And we have of course production issues happen sometimes from time to time, database, for example, goes up to CPU, microservices. Sometimes-
Anthony (18:57): It's a fact of life. It doesn't matter how great your processes are, technology fails. Otherwise, everybody would've perfect phone calls. Nobody would buy a new TV. Nobody would buy a new PC because technology is finite. It ages, you have to replace it. And even the best laid plans of mice and men and all that kind of fun stuff. You can't predict the future, right?
Yousef (19:23): Yeah, exactly. So we have cases, we have history of cases. We also have the knowledge. Okay, how we can actually adapt our knowledge to these historical cases that we have on the system. We found out that we took a lot of time to investigate, to know the root causes for a specific smooth thing. So we find out okay, then we need to look at the tools, the technology tools that could help us to achieve our goals. And we started to look for APM solutions. We enhanced our monitoring end to end from Prometheus, Grafana. We built monitoring levels across all the layers starting from the hardware or the cloud, you could say. Until the network, until the logs itself to see the frequent logs that could come up, and so on. And then, this was the start.
Yousef (20:11): And this was actually on the SRE level. I started to take it in a bigger scope. Okay, how can we now use this to help our business or help our platform to be reliable? So we took the PRR model, which is Production Readiness Review. It's something Google has implemented. They have five to six steps if I remember starting from, I think if I remember, the first step was like engagement with the people inside the organization. How you're going to engage yourself with the development teams, with the architects, and so on. Moving to the analysis and improving and refactoring and training and service onboarding. And it was more into theoretical thinking. And they gave us a graph for the service lifetime. Any service starts with architecture development then limited availability. We do beta or alpha testing then general availability then monitoring.
Yousef (21:11): And then depreciation service is not going to be there later on. Okay then we sat together, we said, "Okay, let's now try to build the framework customized for Hyke so we can work on it." And we said, "Okay, we have two types of methodologies. We either onboard our microservices to the SRE." Because we cannot simply say, "Okay, we have SRE, we will take all the microservices part of the stack." This is not going to happen. We said we will work on microservice by microservice. And whenever we do optimization on this microservice, we will onboard it in our SRE stack. From whatever is not there, it's fine. We can keep it as it is as long it's running. And this is the framework and the strategy that we used. And we started to break down our microservices into three layers to be honest. Core surfaces, which is pure core flow. If it goes down, it will impact all the users-
Anthony (22:04): Like the front end, right?
Yousef (22:05): Yeah-
Anthony (22:08): Front end goes down then-
Yousef (22:10): Exactly. Or the management, payment. One of the core services, if it goes down, it's catastrophic for us. Then the second one was actually the normal services, which have major features but not part of the core flow, could be loyalty points that we give to the customer, could be collection, could be something that could have an impact but not an major flow. And the third one is the supplementary, like for example, SMS notification. There could be a delay in SMS, could be received to that but at the end of the day the payment has gone. So we break down the service into this categorization and we started to pick them based on that. And it wasn't enough to be honest. I thought that now we are ready, let's do it. No, it wasn't because features are going and people are developing on top of these microservices.
Yousef (22:58): So we started to do the engagement. We found out that this is not enough for us to work alone. We need to go into the software development life cycle and we need to explore our culture to everyone. We worked with the backend guys on the front end. We are actually squad restructured and we have something called an infrastructure squad. This squad is not DevOps, they are actually backend and front end guys. And we are working with them to enhance the system reliability of the platform. So we started with them because these are the closest guys that we could understand our pain areas. And we told them, "Okay, guys, let's build a framework. Let's build a framework for engagement and let's build a framework on a service level." So on a service level, we have optimized it into five phases. We worked on how we can do service benchmarking, how we can do capacity planning, performance tuning, how we can do monitoring on production. What kind of alerts we needed because excessive alerts is actually a negative thing on your end as well.
Yousef (23:59): Then it worked successfully. We get good results. We started with one microservice, which was having an issue on it in production in the last two, three months. We said, "Okay, this is the best case that we can work on and see good results." Once it was actually successful, stable. We started to explore the engagement across all the teams. I spoke with the architects, I told them, "Okay, the SRE team needs to be involved from the start to know the idea. Moving to the basic architecture we need to know what microservices will be introduced. What existing flows will come to the picture."
Yousef (24:34): Then we spoke with the back-end on the front-end teams. We sit with them in the pre-sprint planning, especially on introducing the API calls. We call it the technical solution metering. What API calls will come to the picture? How will this impact us on the SRE? How this will impact the numbers that are already there that we have within our area?
Yousef (24:56): Moving to the QA team because we have performance testing but not that big number. So, we work on automation. This is maybe a little bit of a DevOps mindset. Okay, if you guys don't have enough resources, let's automate what you guys are doing as much as we can. And SRE and QA are working together using the same tools and the execution of the service benchmarking and the results is happening via CI/CD via Jenkins. And we are releasing the reports or the results from the Jenkins to the Bitbucket repository so that they can view the results, and so on. Yeah. That's mainly high-level.
Anthony (25:38): You did notice something really. So if you take a step back, right. In the Genesis of you getting more involved with the Dev team was about, okay, how do we prioritize services, right? So that we can deliver the best reliability. And if we take those three examples that you had, right. Where let's say the least important was the text message notification, right? Going back. With CI/CD and developers being developers. If you're not involved in the development life cycle; how are you going to know when a new API comes on board? That in actual fact means that somebody is now going to use the notification microservice to actually reach out to a payment API, so that a payment doesn't happen until let's say an encrypted text message leaves with a confirmation. Now if that's delayed, all of a sudden, that microservice is now priority one and you would've never known about it, right?
Anthony (26:38): So by embedding yourself into the development life cycle you are able to understand and see a microservice's importance is only as important as the developer makes it, right? And if the developer makes it more important or less important, you need to be aware of it because that's going to ultimately impact your bottom line, which is the reliability of the application. Frankly, you couldn't care if there are bells and whistles or not, you obviously want that as a product to deliver a better experience, but is a better experience better than no experience? You got to, yeah, you got to get that-
Yousef (27:22): Balanced. Yeah, exactly. Yeah, I'll tell you why because one of our DevOps automations that we did. It's not that whenever any new microservice will come into the picture, we don't need to step up on the DevOps team, "Guys, we have a new microservice, please build the CI/CD for it." Okay, I told them, "No, we will give you an automation that you can actually, whenever you have a new microservice with a REPL already created for it and a code, just go to the Jenkins..." They will put the URL of the Bitbucket or the GitHub URL for the REPL, and that's it. It will automatically create a CI/CD. If it's Java, it'll have the same CI/CD Java based on the previous microservice. If It's Node.Js, it will do the same. If it's something else, it will have three templates that can actually create the CI/CD from them.
Yousef (28:08): So the issue of this it's good they're not depending on us to create CI/CDs, but the bad for us that sometimes we don't know, there's a new microservice scheme to production actually, at that time. Because they don't need DevOps, they are just creating it from the automation that we did. So we figure out the new microservices scheme which impacted our flow. So this was the challenge, how we can be aware without even slowing them down. And this is where we started to build the engagement and the framework that can achieve both of us.
Anthony (28:40): Yeah. So, one of the things that, as you enhance this practice now and development is getting more aligned with site reliability and it's an actual DevOps say, as opposed to not. One of the things you might begin to notice, right, as you go into your run phase is that Kubernetes is expensive to run, right? And when you're in it, sorry. When you're running it on AWS, you do have alternatives. So are you experiencing additional complexity right now by people maybe experimenting with using a mixture of microservices, as well as, like, serverless stuff? So like, Lambda scripts running code because we don't need them running with an EC2 environment running all the time supporting Kubernetes because they're just not used frequently enough. How are you dealing with that challenge as more complexity is coming into the environment?
Yousef (29:41): Currently I'm using only Kubernetes extensively, actually across all the environments, I have around 100 plus servers for around five to six clusters currently, right now. I'm not using Lambda functions extensively. I'm just using it for automation parts as well, only. Specifically on the lower environments. We stop down the environments and we spin it up every day to save cost via Lambda scripts, which takes our servers by chronological order, starting from shutting down the database and the EC2s and so on. And spinning up without human intervention. This is mainly Lambda. Kubernetes is mainly hosted on EKS with a mixture of autoscaling groups. We are using on demand and on-spot machines. Some people would say why on-spot, on-spot is completely unreliable, which is against our culture. However, we are doing it in a way that we can have a mixture between on demand and on-spot to actually have the benefits of high specs with a low cost.
Yousef (30:52): And, at the same time, the same microservice with a replica is actually spinned over the on-demand and on-spot. And we are using some open source technologies like pod anti-affinity, cluster over provisional, and cluster autoscaler. These tools are allowing me to spin the same microservice replica across different availability zones, different machine specs, different events, machines, family sizes, and different hosts. Which leads to this reliability option. And I'm still benefiting from high CPU and low cost at that time or high specs and low cost at that time.
Yousef (31:33): My only concern on the Lambda functions itself, that if I move to the serverless architecture, I would save a lot of cost but I would be a little bit locked in with the vendor. If I need to move to another cloud provider, I need to repeat all this automation again. But Kubernetes again, it's an open source tool. I have the microservice, I have the replica. Simply, I would spin them using Helm charts or CI/CD or even Kubectl and the awareness and the technology knowledge is even higher than the serverless architectures. At least on this stage, we don't know tomorrow, tomorrow could even be the future now, we don't know. But this was my assessment at that time.
Anthony (32:14): So just a little sidebar here. I don't know if it's just me, but I have huge problems with EKS and autoscaler groups. Have you ever noticed how they don't work? You always have the minimum nodes and then when you update it to like say, "Okay, I want to change my minimum from three to five." It never changes for me. I don't know if it's just me.
Yousef (32:39): No-
Anthony (32:41): ...but then I end up with my three nodes. Maybe this is a brief AWS sidebar technical support thing, but it's not just happened to me. It's happened to my customers as well. We're having to just respin up an autoscaler group. It's like the most least reliable component in AWS I've used.
Yousef (32:57): I'm actually using auto scaling and aggressively on three worker modes. I think my minimum is around 22 and the maximum is 55, something like this, for one only group. I have three groups actually. The autoscaling specifically for the on-spot is very aggressive, but so far it's working. I don't know but I haven't faced this problem so far, which is good. The cluster autoscaler is working fine as long as you're updating it with the right numbers, it's working fine. I don't know-
Anthony (33:31): See that's what I do. I put the numbers in and it's not...That's just a sidebar, but we have actually just about ran out of time now. Before we leave everybody today, do you have any recommendations? I know you've mentioned the SRE handbook by Google. If somebody is about to undertake this position and they want to be as knowledgeable as possible going into this or maybe it's just a book or something you're reading on the side that doesn't necessarily pertain to SRE, what would you recommend?
Yousef (33:24): Actually, I recommend first starting with the Google case because this is the guys, these are the owners who started the SRE model itself. And this is to be honest was our first article at that time. I could also send you a couple of links that we work through. We still have it as a reference here, as a history. This gave us a lot of theoretical knowledge which we actually needed at that time. After understanding the theoretical base, you need to understand some metrics. How can you measure your team's service level objectives, service level indicators, metrics like, sub metrics actually could help you to let's say, take the theoretical work into numbers, which every team actually needed for the OKRs. This could be the second step as well. Then you need to assess the technology stack, how you can achieve your goal, how you want to achieve these metrics or the OKRs that you actually start.
Yousef (35:02): Okay, you said, I want to have the system reliable 99.93 this year. Okay so, it could be four hours could be five hours, okay. You will have an error budget for four hours after this, you'll be charged, theoretically charged, on your mind. Then the technology stack is very important here to achieve your results and knowledge will come by cases because no one will tell you how to use it efficiently other than yourself. If you don't have a problem case that happened to your system, you will never efficiently utilize it. But if you have problems in your system, this is actually healthy because it will let you learn from what you have faced in the previous problem. So even though I don't recommend to have SRE from day one when you still in MVP phase, you don't have a product yet.
Yousef (35:59): Build the product and whenever the product is ready and you know that is actually going to go live, then think about the SRE as a thinking and as a culture as well in the team. Because if you start it from scratch as a culture, you will be able to build a reliable system from now on. But don't say I don't, I'm still in the MVP phase. Okay, I will build an SRE team now. They will come, okay, they will try to do some stuff but they don't have history to give you, let's say reasonable results at that time. You need to invest in the DevOps area at this time because this is the most critical part, how to go quickly to the market.
Yousef (35:48): And once it looks like it's happening, guys, we are in the right way. Now we look at the SRE side, how you can achieve the SRE culture across the organization even if you have a small team, if you have a small tools, it's still valuable. And it will give you the small minor changes because if you read about starting from the architecture as well and you engage from the architecture point of view from the other software development life cycle, you can tell them, "Guys you are doing this wrong. We should have done this. Okay, we need to do service benchmark for these APIs." You may find some surprising results on some microservices that you never even came to your mind that it could happen unless you have a problem on production. At least this is my experience that I faced and not sure if this is right or wrong, but at the end of the day, SRE is a culture like DevOps. Doesn't have exact steps to follow but it has some guidelines, some principles, some practical use cases that you need to take and customize it for your own company.
Anthony (37:33): Awesome. Well, Yousef, I'd love to stay and talk some more. Maybe what we'll do is we'll have a panel. We've spoken about it with some of our previous guests who work in the site reliability engineering space. And it probably would be good to get people together and do a bit of a Q and A as part of a special episode. But I would like to thank you for your time today. It's been really appreciated. I hope that people find value from your experience and the fact that it is possible to incorporate the Google-like SRE with minor modifications for an individual business as part of your ongoing operations, and you've done it. That's a great achievement but yeah, again, thank you very much. And yeah, hope you have a nice day.
Yousef (38:31): You, too. Thank you very much. Thank you, guys. Thank you for your time.
Annerieke (38:35): Thank you so much for listening. We hope you enjoyed it. If you'd like more information about StackState, you can visit stackstate.com, and you can also find a written transcript of this episode on our website. So if you prefer to read through what they've said, definitely head over there and also make sure to subscribe if you'd like to receive a notification whenever we launch a new episode. So, until next time...
Useful Links
Published at DZone with permission of Annerieke Kortier. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments