The New Testing Pattern: Standardizing Regression for Cloud Migrations
Migrating legacy monolithic systems to the cloud is risky. Here is a proven pattern for automating regression testing at scale by replaying production traffic.
Join the DZone community and get the full member experience.
Join For Free“Cloud Lift” (migrating on-premises systems to the cloud) is often sold as a simple infrastructure change. In reality, for large-scale administrative systems, it is a high-risk operation. When you move a system handling millions of transactions — such as unemployment insurance or tax processing — you cannot afford a single calculation error or performance regression.
The challenge lies in validating that the new system behaves exactly like the old one across thousands of business scenarios. Manual testing is too slow, and unit tests often miss the holistic impact of infrastructure changes.
Based on a recent case study involving the migration of a massive employment insurance system (400 functions, 1,000 tables), this article outlines a new testing pattern. By standardizing input/output comparison and automating the replay of production data, engineering teams can compress months of testing into weeks.
The Problem: The Scale of Legacy
Legacy systems are often characterized by:
- Complex logic: Business rules accumulated over decades (e.g., changing tax laws)
- Massive data: Millions of daily transactions
- High stakes: Incorrect data can lead to financial loss or legal failure
In the case study, the system processed 900,000 transactions daily. Manually creating test cases for every permutation of this logic was impossible within the project timeline. The team needed a way to verify that the new (cloud) environment produced the exact same output as the current (on-premises) environment, given the exact same input.
The Solution: The New Testing Architecture
The core concept is to treat the system as a black box. We don’t test the code; we test the behavior.
We implemented a Traffic Replay Architecture that captures inputs from the production system and replays them against the cloud environment.
The Workflow
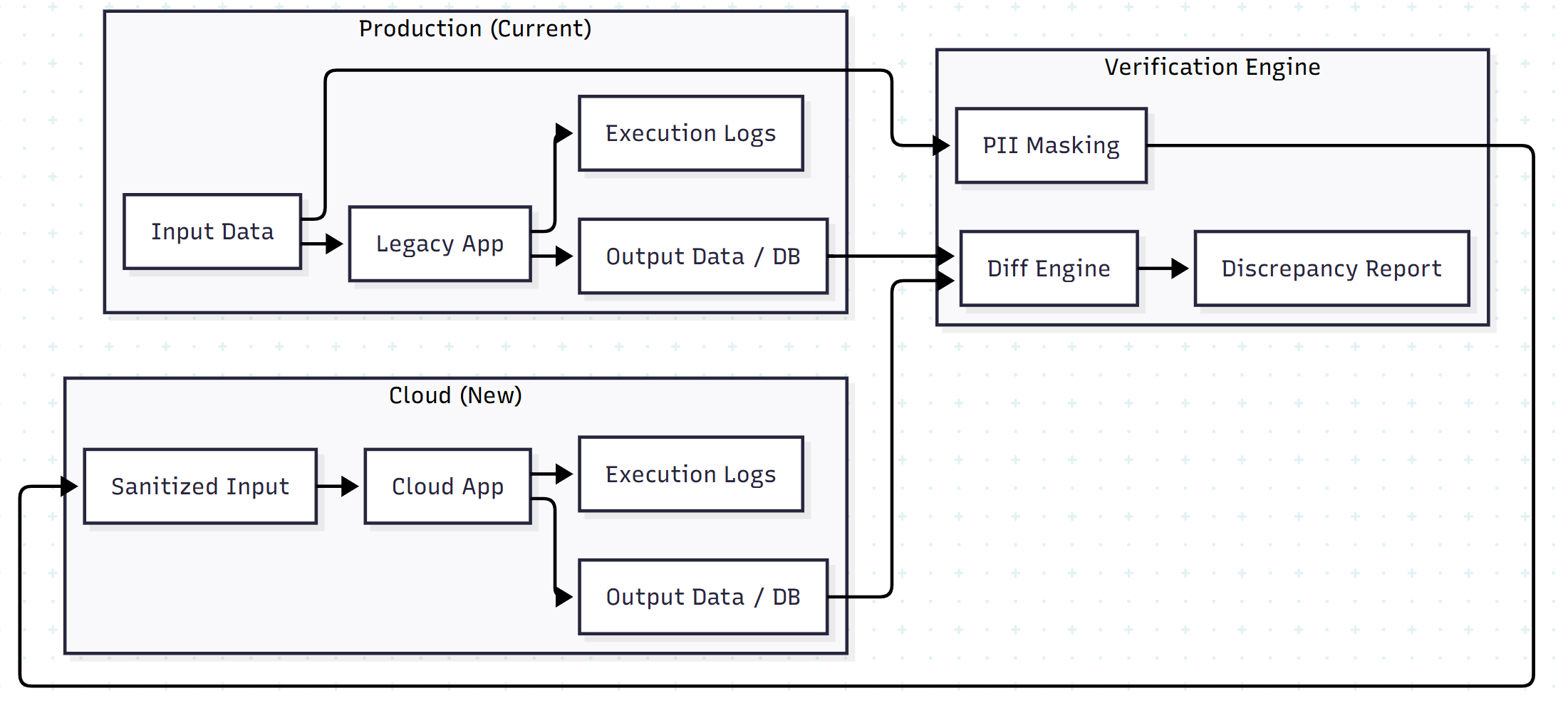
Step 1: Data Capture and Sanitization
We capture three artifacts from the current production run:
- Input data: The raw request or batch file
- Output data: The resulting files or database state
- Database snapshot: The state of the database before processing
Crucial step: Before moving this data to a test environment, it passes through a masking pipeline to anonymize personally identifiable information (PII), ensuring compliance with data privacy regulations.
Step 2: The Replay Engine (HTTP Simulation)
Instead of relying on custom scripts for every batch job, we standardized the execution model by treating legacy batch processes as HTTP request/response interactions.
By building a wrapper that simulates HTTP calls, we could “replay” the sanitized input against the cloud environment. This allowed us to reuse the same testing harness for all 400 functions, regardless of their internal logic.
Step 3: The “Diff” Engine
The heart of this pattern is the comparison logic. We don’t just check for “success” status codes; we perform a deep inspection of the data.
Comparison targets:
- Binary diff: Are the output files identical bit-for-bit?
- DB diff: Did the database rows update in exactly the same way?
- Performance diff: Did the cloud transaction take longer than the on-premises transaction?
Handling Non-Determinism
A common challenge in this pattern is non-deterministic data:
- Timestamps: The
update_timecolumn will always differ - Sequence IDs: Auto-incrementing keys may diverge if parallel processing order changes
To address this, the diff engine must be schema-aware. We configure it to ignore specific columns (such as updated_at or session_id) while strictly enforcing business-critical columns (such as payment_amount or tax_rate).
Conceptual Python Diff Logic
import pandas as pd
def compare_datasets(current_df, new_df, ignore_cols):
# Drop non-deterministic columns
current_clean = current_df.drop(columns=ignore_cols)
new_clean = new_df.drop(columns=ignore_cols)
# Compare
diff = pd.concat([current_clean, new_clean]).drop_duplicates(keep=False)
if diff.empty:
return "MATCH"
else:
return f"MISMATCH: {len(diff)} rows differ."
# Usage
ignore_list = ['timestamp', 'log_id', 'server_name']
status = compare_datasets(df_on_prem, df_cloud, ignore_list)Results: Speed and Quality
Implementing this standardized testing pattern yielded dramatic results:
- Velocity: The team verified 400 functions and 1,000 tables in just two weeks — a process previously estimated to take months with manual testing
- Coverage: By replaying actual production data, edge cases no QA engineer would think to write (e.g., specific combinations of user history) were automatically tested
- Confidence: The performance diff identified infrastructure bottlenecks (such as database latency) before the system went live
Conclusion
When modernizing large-scale systems, standardization is speed. By moving away from bespoke testing scripts for each function and adopting a generic current-vs-new comparison framework, teams can validate complex migrations with mathematical certainty.
Key takeaways:
- Don’t write test cases — steal them. Use production traffic as your test suite.
- Standardize execution. Treat batch jobs as generic inputs and outputs (like HTTP) to simplify tooling.
- Automate the diff. Human eyes can’t catch a one-cent difference in a million rows. Code can.
Opinions expressed by DZone contributors are their own.
Comments