Next-Gen Data Pipes With Spark, Kafka, and K8s: Part 2
This detailed guide reviews the Kafka-K8s combination, shares codebases for building new-age data pipes, and looks at various cloud environment implementations.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
In our previous article, we discussed two emerging options for building new-age data pipes using stream processing. One option leverages Apache Spark for stream processing and the other makes use of a Kafka-Kubernetes combination of any cloud platform for distributed computing. The first approach is reasonably popular, and a lot has already been written about it. However, the second option is catching up in the market as that is far less complex to set up and easier to maintain. Also, data-on-the-cloud is a natural outcome of the technological drivers that are prevailing in the market. So, this article will focus on the second approach to see how it can be implemented in different cloud environments.
Kafka-K8s Streaming Approach in Cloud
In this approach, if the number of partitions in the Kafka topic matches with the replication factor of the pods in the Kubernetes cluster, then the pods together form a consumer group and ensure all the advantages of distributed computing. It can be well depicted through the below equation:
No. of partitions in a topic of Kafka cluster = No. of replication factors for a pod in K8s cluster
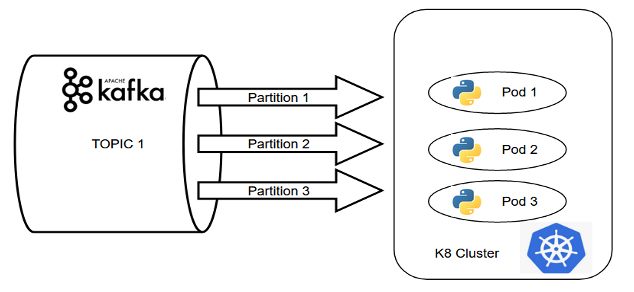
The two most important components of this concept are i) the data streaming service and ii) the container management tool. In the open-source world, Apache Kafka and Kubernetes can easily be leveraged, but as the cloud comes into the picture, the technology stack gets changed with various cloud-managed services for different cloud vendors. In AWS, for data streaming services, Kinesis or MSK can be used. For container management tools, ECS or EKS can be utilized. For newly developed solutions, a Kinesis and ECS combination is better whereas MSK and EKS is a combination best for the solution that is migrated from on-premise deployment. Comparisons between these two technology stacks are as follows:
| Topic | ECS + Kinesis | EKS + MSK |
| Complexity | Easy to use | Relatively complex |
| Provisioning | Easy provisioning | Relatively complex |
| Migration | Not very easy to migrate. Need specific migration scripts for migrating on-premises Kafka configuration to Kinesis and the same applies to base Kubernetes to ECS migration. | Since EKS and MSK are services wrapped over Kubernetes and Kafka, migration would be easy. |
| Scalability | Serverless architecture, and hence scalability is not the user’s headache. | Need to specifically design for scalability. |
| Vendor lock-in | Yes, built on Amazon’s proprietary technology. | No, purely built on open-source technology. |
| Video streaming | Supported | Not supported |
| Native Kafka-K8s compatibility | No native support as ECS and Kinesis are based on Amazon’s proprietary technology. | Ensure native library support as Kubernetes and Kafka cluster can be built in AWS by using these services. |
In Azure, data streaming service options are different. There are many ways by which a Kafka cluster can be implemented on top of the cloud. They are as follows:
- EventHub — Purely serverless azure service for message streaming.
- Kafka on HDInsight — Kafka cluster can be created using HDInsight.
- Kafka on AKS — Containerized Kafka cluster on top of AKS.
- Confluent Cloud — A confluent Kafka service can be used for KSQL and Kafka Stream.
A comparison between all the options is well depicted in the following table:
| Topic | Event Hub | Kafka on AKS | Confluent Cloud | HDInsight |
| Complexity | Easy to use | Relatively complex, K8s knowledge is required. | Easy setup steps | Easy setup |
| Provisioning | Easy | Relatively complex | Easy | Easy |
| Migration | Not very easy to migrate. Migrating on-premises Kafka to the event hub requires additional steps. | Since using Kafka on top of existing AKS cluster, need to set up adapters. | Relatively easy | Easy steps |
| Scalability | Highly scalable | Highly scalable | Highly scalable | Highly scalable |
As far as a container management tool is concerned, Azure offers AKS (Azure Kubernetes Service), which ensures all the benefits of the Kubernetes
In GCP, container engine and container registry are used as container management tools and there are also a few options by which a Kafka cluster can be created and used as a streaming component. The options are as follows:
- Confluent Cloud — It provides fully managed Apache Kafka as a service.
- Pub-Sub — Messaging and ingestion for event-driven systems and stream analytics.
Implementation of Kafka-K8s Streaming Approach
In the past, managing IT infrastructure was a hard job as it had to be managed manually, but now, through IaC (infrastructure as code), this can be handled very easily using config files. The two most popular IaC software tools are Terraform and Ansible, though different cloud vendors have different services for IaC. Let’s look at the example of the CloudFormation template which helps to implement the Kafka-K8s approach by using EKS and MSK services in AWS. A step-by-step guide on the basis of this is shown in the diagram:
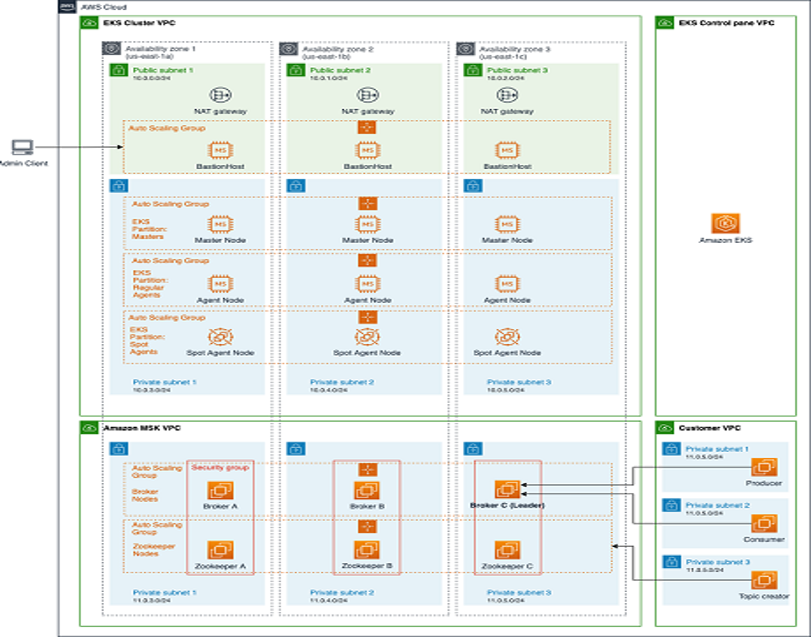
Step One
Create an EKS cluster with the help of the CloudFormation template defined either in JSON or YAML. The following config templates can be used to create an Amazon EKS cluster named Demo.
YAML template (on the basis of Figure 2):
EKSCluster:
Type: AWS::EKS::Cluster
Properties:
Name: Demo
Version: "1.20"
RoleArn: " arn:aws:iam::012345678910:role/eks-service-role-XXXX "
ResourcesVpcConfig:
SecurityGroupIds:
- sg-xxxx
SubnetIds:
- Public Subnet 1 – 10.0.0.024
- Public Subnet 2 – 10.0.1.024
- Public Subnet 3 – 10.0.2.024
EndpointPublicAccess: false
EndpointPrivateAccess: true
PublicAccessCidrs: [ "x.x.x.x/xx"]
Logging:
ClusterLogging:
EnabledTypes:
- Type: api
- Type: audit
Tags:
- Key: "key"
Value: "val"
Step Two
After the creation of the EKS cluster, pods need to be deployed through CI/CD pipeline using k8.yml and ConfigMap.yml files. The following samples of the configuration files create an application pod in the Demo EKS cluster.
configmap.yml
kind: ConfigMap
apiVersion: v1
metadata:
name: SAMPLE_MAP_CONFIG
namespace: SAMPLE_NAMESPACE
data:
CONFIG_FILE: SAMPLE_APP_CONFIG
k8.yml
kind: Deployment
apiVersion: apps/v1beta2
metadata:
name: SAMPLE_METADATA
namespace: SAMPLE_NAMESPACE
labels:
app: SAMPLE_LABEL
spec:
replicas: <no. of replicas of pod>
selector:
matchLabels:
app: SAMPLE_LABEL
template:
metadata:
labels:
app: SAMPLE_LABEL
spec:
containers:
- name: SAMPLE_CONTAINER
image: SAMPLE_IMAGE
imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
env:
- name: SAMPLE_ENV1
valueFrom:
secretKeyRef:
name: SAMPLE_SECRET_KEY1
key: SAMPLE_KEY1
envFrom:
- configMapRef:
name: SAMPLE_MAP_CONFIG
volumeMounts:
- name: SAMPLE_VOLUME
mountPath: SAMPLE_MOUNT_PATH
subPath: SAMPLE_APP_CONFIG
volumes:
- name: SAMPLE_VOLUME
secret:
secretName: SAMPLE_SECRET1
items:
- key: SAMPLE_KEY1
path: SAMPLE_PATH1
nodeSelector:
TNTRole: luxkube
Step Three
The next step is to set up a Kafka cluster by using MSK and a template on the basis of Figure 2. It is as follows:
{
"Description": "MSK Cluster with all properties",
"Resources": {
"TestCluster": {
"Type": "AWS::MSK::Cluster",
"Properties": {
"ClusterName": "SAMPLE_KAFKA_CLUSTER_NAME",
"KafkaVersion": "SAMPLE_VERSION",
"NumberOfBrokerNodes": “SAMPLE_NUMBER_OF_BROKER”,
"EnhancedMonitoring": "PER_BROKER",
"EncryptionInfo": {
"EncryptionAtRest": {
"DataVolumeKMSKeyId": "SAMPLE_MASTER_KEY"
},
"EncryptionInTransit": {
"ClientBroker": "SAMPLE_BROKER", [Ex. TLS]
"InCluster": true
}
},
"OpenMonitoring": {
"Prometheus": {
"JmxExporter": {
"EnabledInBroker": "true"
}
"NodeExporter": {
"EnabledInBroker": "true"
}
}
},
"ConfigurationInfo": {
"Arn": "<Configuration ARN>",
"Revision": 1
},
"ClientAuthentication": {
# For TLS
"Tls": {
"CertificateAuthorityArnList": [
"ARN"
]
}
},
"Tags": {
"Environment": "SAMPLE_ENVIRONMENT_NAME",
"Owner": "SAMPLE_OWNER"
},
"BrokerNodeGroupInfo": {
"BrokerAZDistribution": "DEFAULT",
"InstanceType": "kafka.m5.large",
"SecurityGroups": [
"ReplaceWithSecurityGroupId"
],
"StorageInfo": {
"EBSStorageInfo": {
"VolumeSize": <data volume size>
}
},
"ClientSubnets": [
"Subnet1-11.0.3.0/24",
"Subnet2-11.0.4.0/24",
"Subnet3-11.0.5.0/24"
]
}
}
}
}
}
Step Four
The next step is to create as many partitions in the Kafka topic as the replication factor of the EKS pod by using the following command:
$ bin/kafka-topics.sh --create –zookeeper <zookeeper connection string>
--partitions <no. of partition> --replication-factor <no. of replicas>
--topic <topic name>
For example, if the replication factor of the pod in EKS cluster is three, then in the above command, the number of partitions will be three. It ensures absolute parallel processing, as there will be 1:1 mapping between the partition of the topic and the number of replicas of the pod.
Conclusion
This Kafka-Kubernetes combination ensures all the benefits of parallel processing and cluster computing, and it becomes more effective when it merges with cloud computing. The speed layer of the Lambda Architecture is entirely based on stream computing, whereas in Kappa Architecture, the stream-based transformation component is the only processing layer. So, in both cases, this Kafka-Kubernetes combination can be used, and it also adds the benefits of the cloud when deployed in any cloud vendors like AWS, Azure, GCP, etc.
Opinions expressed by DZone contributors are their own.
Comments