Why Your On-Call AI Agent Needs a Guardian
AI on-call agents need a supervisory layer before they touch production. Here is the design pattern, the code, and the failure modes it prevents.
Join the DZone community and get the full member experience.
Join For FreeIt's 2 am. PagerDuty fires. You're half-awake, moving fast, and you restart the wrong service. It happens. You're human.
Now imagine the same scenario, except the thing moving fast isn't you. It's an AI agent. One that doesn't second-guess itself, doesn't notice the environment variable says PROD, and doesn't slow down.
That's where we're headed with AI on-call agents. The potential is real. So is the risk. The question I kept hitting while building a research prototype for agentic incident response: who watches the agent?
That's what a guardian agent is — not a buzzword, but a design pattern. A layer that sits between your autonomous agent and production with one job: make sure the agent does what it's supposed to, and nothing else.
Three Ways Unsupervised Agents Break Things
Current AI on-call agents follow a familiar pattern: detect → diagnose → remediate. Tools like incident.io's AI SRE and AWS's DevOps Agent are already doing parts of this. Detection and diagnosis are relatively safe. Remediation is where it gets dangerous.
Once an agent can act — restart a pod, roll back a deployment, open a firewall rule — three failure modes show up consistently in research on autonomous systems:
- Wrong action, right environment. Agent identifies a service is down, restarts a healthy dependency instead, causes a cascade.
- Right action, wrong environment. Agent targets prod when it should have hit staging. No audit trail. Nobody knows until morning.
- Escalation loops. Metric spikes. Agent acts. Metric spikes again. Agent acts again, until it's exhausted the playbook and left the system in an unplanned state.
Humans hit all three too. But humans have friction — you pause, you re-read, you notice something feels off. Agents don't. A guardian agent restores that friction deliberately.
What a Guardian Agent Does
A guardian intercepts every action before it executes. Four responsibilities:
- Intent validation – Does this action match the incident context?
- Scope enforcement – Is the environment, service, and blast radius within approved bounds?
- Audit logging – Every proposed action, approved or blocked, logged with full reasoning.
- Human escalation – High-risk actions get paged to a human, not auto-approved.
The guardian doesn't triage or diagnose. It answers one question: should this action run right now?
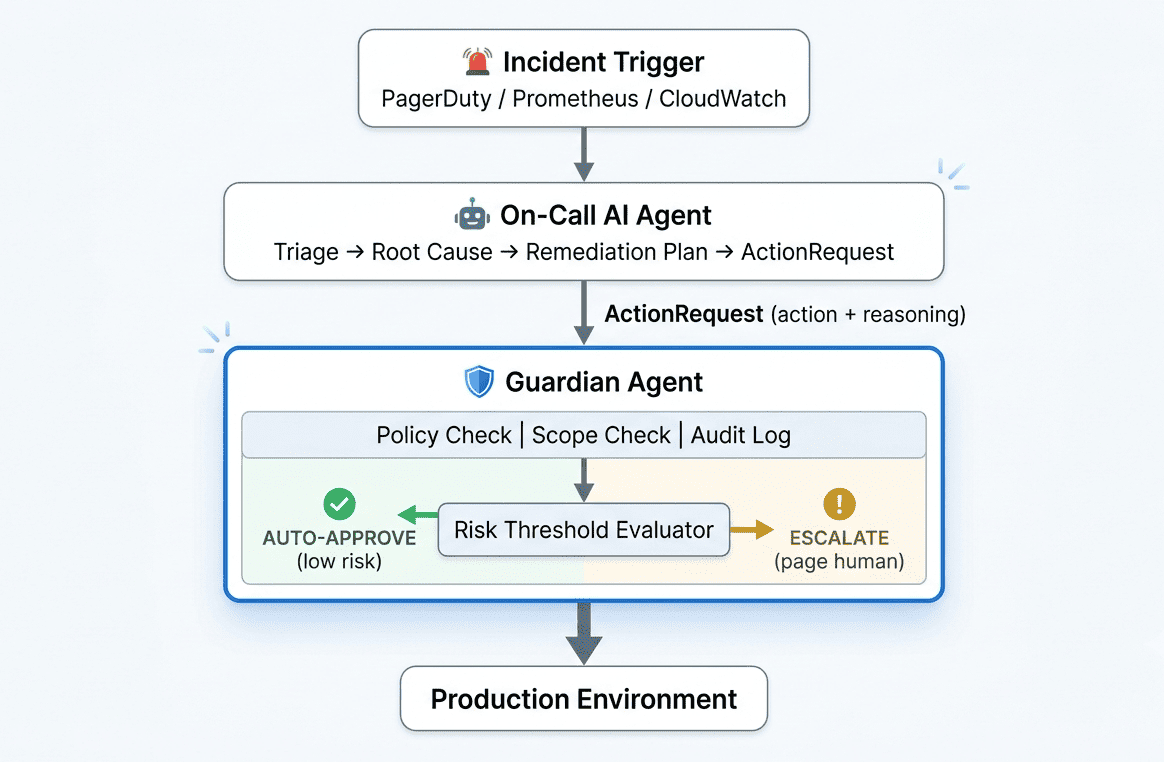
The Architecture
The on-call agent never calls production APIs directly. Every intended action gets wrapped into a structured ActionRequest and submitted to the guardian first.
The ActionRequest Pattern
from dataclasses import dataclass
from enum import Enum
class RiskLevel(Enum):
LOW = "low" # Auto-approve
MEDIUM = "medium" # Auto-approve + log
HIGH = "high" # Page human first
CRITICAL = "critical" # Block, immediate escalation
@dataclass
class ActionRequest:
action_type: str # "restart_service", "rollback", "scale_up"
target_service: str # "payments-api"
target_environment: str # "prod", "staging"
parameters: dict
agent_reasoning: str # why the agent thinks this is correct
incident_id: str
proposed_blast_radius: str # "single pod", "entire fleet"
The agent_reasoning field matters more than it looks. Forcing the agent to articulate its intent gives the guardian better evaluation context, and gives your team something readable in the postmortem.
The Policy Engine
The current prototype uses a score-based risk evaluator. Rather than a flat action list, it weighs multiple signals together: action type, blast radius, time of day, and recent deploy velocity. Each factor adds to a score, and the score maps to a risk level. It is not perfect, but it is a lot closer to how risk actually works in production than a hardcoded if/else.
class GuardianAgent:
def __init__(self, policy_config: dict):
self.policies = policy_config
self.audit_log = AuditLogger()
def evaluate(self, request: ActionRequest) -> GuardianDecision:
self.audit_log.record("proposed", request)
if request.action_type not in self.policies["allowed_actions"]:
return self._block(request, "Action type not in approved list")
if request.target_environment == "prod":
risk = self._assess_risk(request)
if risk in [RiskLevel.HIGH, RiskLevel.CRITICAL]:
return self._escalate_to_human(request, risk)
if request.proposed_blast_radius == "entire fleet":
return self._escalate_to_human(request, RiskLevel.HIGH)
return self._approve(request)
def _assess_risk(self, request: ActionRequest) -> RiskLevel:
score = 0
# Action type weight
action_scores = {
"rollback": 3, "scale_down": 3, "firewall_change": 3,
"restart_service": 2, "scale_up": 1, "clear_cache": 1
}
score += action_scores.get(request.action_type, 2)
# Blast radius weight
if request.proposed_blast_radius == "entire fleet":
score += 3
elif request.proposed_blast_radius == "multiple pods":
score += 2
# Time-of-day weight (peak hours = higher risk)
current_hour = datetime.utcnow().hour
if 8 <= current_hour <= 18:
score += 1 # Business hours: more eyes on it
else:
score += 2 # Off-hours: harder to recover fast
# Recent deploy activity (change velocity = higher blast risk)
recent_deploys = self.cmdb.deploys_in_last_hour(request.target_service)
if recent_deploys > 2:
score += 2
# Map score to risk level
if score >= 7:
return RiskLevel.CRITICAL
elif score >= 5:
return RiskLevel.HIGH
elif score >= 3:
return RiskLevel.MEDIUM
return RiskLevel.LOW
def _escalate_to_human(self, request, risk) -> GuardianDecision:
self.audit_log.record("escalated", request, risk=risk)
pagerduty.page(
message=f"Guardian blocked {request.action_type} on "
f"{request.target_service}. Reason: {request.agent_reasoning}",
incident_id=request.incident_id
)
return GuardianDecision(approved=False, reason="escalated_to_human")The guardian doesn't diagnose. It only knows risk boundaries. Keeping diagnosis and governance in separate agents is what makes the system auditable. Even approved actions get logged. If something goes wrong, the audit log is all you have.
How Each Risk Gets Addressed
Wrong action, right environment. The allowed action list blocks anything outside the playbook. restart_healthy_dependency can't be approved if it was never defined as a valid action. Simple, but effective. It also forces the on-call agent to work within an explicit vocabulary of actions rather than freeform tool calls — a constraint that turned out to be useful during testing.
Right action, wrong environment. The scope check evaluates target_environment on every request. Any prod action above medium risk requires human approval. The environment is part of the request object — the agent can't silently target prod without it being evaluated.
Escalation loops. This one needs more than a flag check. The guardian tracks action count and action type per incident ID. If the same action has been attempted more than N times without the triggering metric recovering, the guardian blocks further attempts and pages a human. The agent can't loop itself into a disaster, but tuning the N threshold is genuinely tricky and something I'd want real incident data to calibrate against.
What This Doesn't Solve
The guardian is only as good as your policies. Wrong risk thresholds produce wrong decisions — that's a human authoring problem, not a technical one.
It also can't evaluate semantic correctness. It confirms the action is approved, in-scope, and within blast radius limits. Whether restarting that specific service at that specific moment is actually right — that's still judgment, and judgment still needs humans.
Last: an audit log nobody reads is just storage costs.
Where This Goes
Gartner flagged guardian agents as an emerging category in early 2026, specifically for AI systems that need governance layers as they gain autonomy. Academic research is arriving at the same conclusion from the safety side: a 2025 arXiv survey on multi-agent security found that "security must be embedded in multi-agent architecture through defense-in-depth: controlling agent privileges, validating communications, and sandboxing execution of high-risk actions," which is essentially the guardian pattern described independently.
The risk evaluator will get more sophisticated from here — CMDB-driven service criticality, deploy frequency weighting, time-of-day context. The policy engine will get more expressive.
But the core separation stays: the on-call agent decides what to do. The guardian decides whether to let it. Don't collapse those two into one.
Note: This architecture was developed as a personal research project, not affiliated with any employer.
No production systems were harmed. Building something similar or wrestling with the policy authoring problem? Drop it in the comments.
Opinions expressed by DZone contributors are their own.
Comments