Operationalization of Machine Learning Models: Part 1
This article looks at operationalization of Machine Learning models.
Join the DZone community and get the full member experience.
Join For FreeMachine Learning in enterprises is complex and involves many steps. Below is a complete lifecycle of a Data Science project as described by the Team Data Science Process (TDSP), which is a popular approach to structure data science projects. 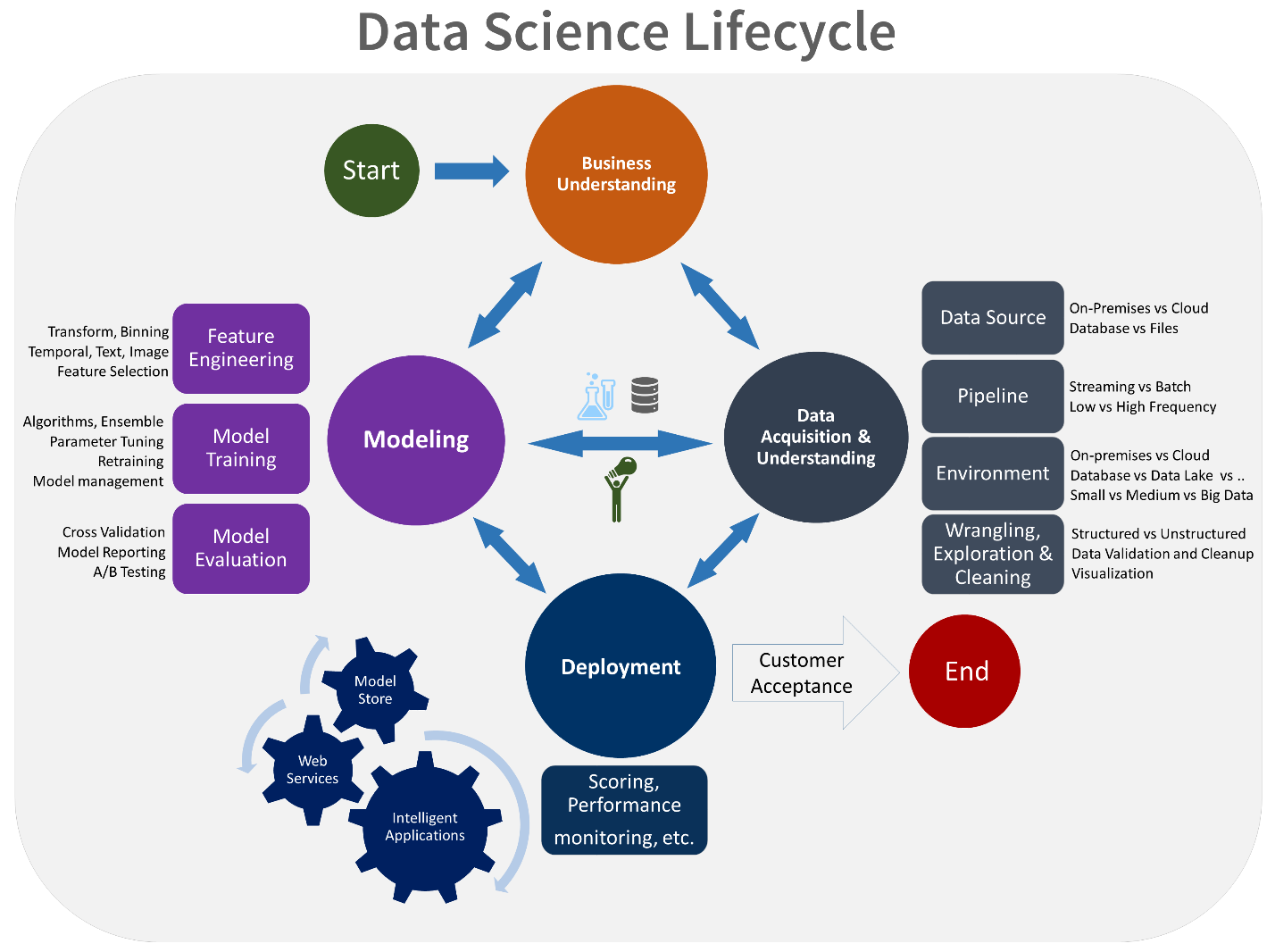
As you can see, the three key pillars of the data science project lifecycle are below.
- Data (collection, cleaning, transformation)
- Model (Model creation, evaluation)
- Operationalization (deployment, monitoring, retraining)
One of the most critical but often overlooked aspects of the Machine Learning process is operationalization of Machine Learning models. Operationalization (o16n) refers to the deployment of models to be consumed by business applications to predict the target class or target value of a classification/regression problem. Machine Learning models have no tangible business benefits until they're operationalized.
Operationalization of Machine Learning models includes the below areas.
- Deployment of Model
- Model Scoring/Serving
- Collect metrics/failures
- Monitor Model Performance
- Analyze results and errors
- Retrain Model
In this article, we will discuss some considerations and best practices for each of the above areas.
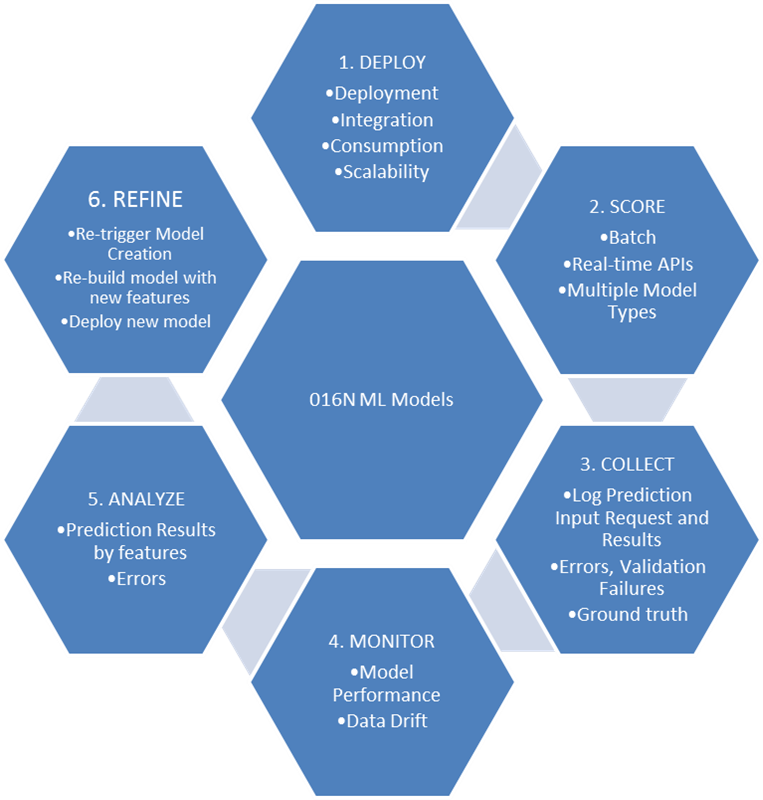
Fig: Operationalization (O16N) of Machine Learning Models in Enterprise
Deployment of Models
For model deployment, it is generally recommended to keep model training and deployment infrastructure separate. Model training environments would typically distribute clusters with a higher configuration as the model is trained on larger historical data. A model scoring/serving environment can be sized based on concurrent requests and response times required. The package deployed should include the entire data pipeline, which includes cleaning and transforming the data from the source before feeding it to ML models. For example, during training, null values in certain columns would have been imputed with mean. It is required to store these values as part of the model package so that new incoming records for prediction are imputed with the same value if a particular field is empty. Also, proper validations have to be done on the incoming data to ensure no new value is seen for categorical value or a column not having any null values during training has null values during prediction. All data validation issues have to be logged, and a mechanism to notify model monitoring is required.
A model scoring engine should support containerization using Docker or Kubernetes, as its lightweight, portable, and scalable. For business application teams to easily integrate a prediction engine, support for an interface like Swagger UI will help in easy testing and provide up-to-date documentation.
Model Scoring
Use cases in enterprises may demand support for both batch and real-time predictions. Use cases like Loan Loss Mitigation for banks where all loan accounts are predicted for going default based on past payment history may require batch predictions while use cases like fraud or loan approval may need real-time prediction. REST APIs with support for a single record, batch of records, or a CSV file would be desirable to meet requirements of multiple applications and use cases. The scoring engine should support models from different frameworks like scikit-learn, TensorFlow, deep learning, and multiple models like Random Forest, Gradient Boosting Trees, Linear Models, neural network architectures, as well as custom models. Supporting different model frameworks and models for scoring is a challenge. The adoption of standards like PMML (Predictive Model Markup Language), PFA (portable format for analytics) and ONNX (Open Neural Network Exchange) can help in standardizing the model format, but they add some restrictions. An alternative is to enable support for native APIs of each model, but this can be time-consuming to build. A model agnostic scoring engine can help greatly in easy operationalization of models for an enterprise.
In part 2 of the article, we will discuss other areas of focus with regard to operationalization of Machine Learning models.
Opinions expressed by DZone contributors are their own.
Comments