Optimizing Pgbench for CockroachDB Part 1
I originally wrote an article on pgbench and CockroachDB in October of 2021. Today, we're going to return to the topic and discuss a few improvements.
Join the DZone community and get the full member experience.
Join For FreeI'm passionate about my job and I document all of my CockroachDB shenanigans. You can find them in my profile.
Motivation
The previous article left a lot to be desired and I've been meaning to get back to it. Today, we're going to improve on the original article by demonstrating what can be done to improve the performance of pgbench with CockroachDB. Typically, when customers begin their CockroachDB journey, they are faced with a learning curve having no prior knowledge of CockroachDB and many times, the biggest hurdle is database isolation. CockroachDB operates in serializable isolation by default. There are no plans to change the status quo. We advise our customers to practice defensible programming and change their applications to work around the errors and retries instead of reducing isolation. We're going to treat pgbench like a legacy application and demonstrate the problems and how we can work around them and modernize them for CockroachDB.
High-Level Steps
- Provision a CockroachDB cluster
- Install pgbench
- Set the environment variables
- Initialize the benchmark
- Run an arbitrary workload
Step-by-Step Instructions
Deploy a CockroachDB Cluster
I've designed this tutorial to be reproduce-able, in fact, I have a Docker environment you may use to try or use the serverless tier, the same way as I did in the original article.
Install Pgbench
pgbench comes bundled with postgresql binary. If you have it installed, you already have access to pgbench. You may confirm you have it installed by running
pgbench --version
pgbench (PostgreSQL) 15.1
Otherwise, use your OS's package manager to install
brew install postgresql@15
echo 'export PATH="/opt/homebrew/opt/postgresql@15/bin:$PATH"' >> ~/.zshrc
source ~/.zshrc
pgbench --versionPgbench continues to behave differently from one version to another. I was pleasantly surprised by the quality of life improvements in version 15.1 in regard to retries. That said, if you choose to follow this article, please use version 15.1 at minimum. The docker-compose environment I'm using comes preinstalled with the correct version of pgbench.
Set Environment Variables for Convenience and Readability
export PGHOST=hostname
export PGUSER=sqluser
export PGPASSWORD=sqlpassword
export PGPORT=26257
export PGDATABASE=databasename
export SCALE=100Initialize the Benchmark
You may need to create the database before proceeding
psql -c "CREATE DATABASE IF NOT EXISTS example;"
pgbench \
--initialize \
--host=${PGHOST} \
--username=${PGUSER} \
--port=${PGPORT} \
--no-vacuum \
--scale=${SCALE} \
--foreign-keys \
${PGDATABASE}dropping old tables...
creating tables...
NOTICE: storage parameter "fillfactor" is ignored
NOTICE: storage parameter "fillfactor" is ignored
NOTICE: storage parameter "fillfactor" is ignored
generating data (client-side)...
10000000 of 10000000 tuples (100%) done (elapsed 273.30 s, remaining 0.00 s)
creating primary keys...
creating foreign keys...
done in 533.70 s (drop tables 0.01 s, create tables 0.09 s, client-side generate 301.27 s, primary keys 223.42 s, foreign keys 8.92 s).We created 10M rows in the pgbench_accounts table
root@lb:26000/example> show tables;
schema_name | table_name | type | owner | estimated_row_count | locality
--------------+------------------+-------+-------+---------------------+-----------
public | pgbench_accounts | table | root | 10000000 | NULL
public | pgbench_branches | table | root | 100 | NULL
public | pgbench_history | table | root | 0 | NULL
public | pgbench_tellers | table | root | 1000 | NULLThere's an option to generate data server-side, which promises to be faster. Unfortunately, it does not work with Cockroach today. The command would look like so:
pgbench \
--initialize \
--init-steps=dtGpf \
--host=${PGHOST} \
--username=${PGUSER} \
--port=${PGPORT} \
--no-vacuum \
--scale=${SCALE} \
--foreign-keys \
${PGDATABASE}The error I received
dropping old tables...
creating tables...
NOTICE: storage parameter "fillfactor" is ignored
NOTICE: storage parameter "fillfactor" is ignored
NOTICE: storage parameter "fillfactor" is ignored
generating data (server-side)...
pgbench: error: query failed: ERROR: unsupported binary operator: <decimal> + <int> (desired <int>)
pgbench: detail: Query was: insert into pgbench_tellers(tid,bid,tbalance) select tid, (tid - 1) / 10 + 1, 0 from generate_series(1, 100) as tidThe error is a known CockroachDB issue where / operator returns a DECIMAL instead of INT. The workaround is as easy as changing it to // but in our case, it requires pgbench recompilation which may not be feasible.
Run an Arbitrary Workload
I am going to run a sample workload from the pgbench docs, titled tpcb-like which is described as:
The default built-in transaction script (also invoked with -b tpcb-like) issues seven commands per transaction over randomly chosen aid, tid, bid and delta. The scenario is inspired by the TPC-B benchmark, but is not actually TPC-B, hence the name.
You can learn about the TPC-B workload here. In summary:
TPC-B can be looked at as a database stress test, characterized by:
- Significant disk input/output
- Moderate system and application execution time
- Transaction integrity
TPC-B measures throughput in terms of how many transactions per second a system can perform. Because there are substantial differences between the two benchmarks (OLTP vs. database stress test), TPC-B results cannot be compared to TPC-A.
Instead of calling it with a flag, I'm going to wrap it in a script and name it tpcb-original.sql.
\set aid random(1, 100000 * :scale)
\set bid random(1, 1 * :scale)
\set tid random(1, 10 * :scale)
\set delta random(-5000, 5000)
BEGIN;
UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
UPDATE pgbench_tellers SET tbalance = tbalance + :delta WHERE tid = :tid;
UPDATE pgbench_branches SET bbalance = bbalance + :delta WHERE bid = :bid;
INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
END;We can now call it with the -f or --file flags:
pgbench \
--host=${PGHOST} \
--no-vacuum \
--file=tpcb-original.sql@1 \
--client=8 \
--jobs=8 \
--username=${PGUSER} \
--port=${PGPORT} \
-T 60 \
-P 5 \
${PGDATABASE}pgbench (15.1 (Debian 15.1-1.pgdg110+1), server 13.0.0)
progress: 5.0 s, 67.4 tps, lat 44.966 ms stddev 62.789, 89 failed
progress: 10.0 s, 69.4 tps, lat 52.722 ms stddev 99.456, 64 failed
progress: 15.0 s, 64.0 tps, lat 52.988 ms stddev 82.548, 91 failed
progress: 20.0 s, 62.4 tps, lat 53.824 ms stddev 99.057, 88 failed
progress: 25.0 s, 68.0 tps, lat 56.015 ms stddev 104.816, 75 failed
progress: 30.0 s, 63.2 tps, lat 49.316 ms stddev 71.320, 95 failed
progress: 35.0 s, 61.4 tps, lat 50.977 ms stddev 87.213, 89 failed
progress: 40.0 s, 63.0 tps, lat 51.263 ms stddev 84.816, 77 failed
progress: 45.0 s, 57.2 tps, lat 56.409 ms stddev 107.578, 60 failed
progress: 50.0 s, 56.8 tps, lat 66.433 ms stddev 117.206, 59 failed
progress: 55.0 s, 57.2 tps, lat 48.444 ms stddev 75.435, 73 failed
progress: 60.0 s, 57.6 tps, lat 60.030 ms stddev 132.582, 50 failed
transaction type: tpcb-original.sql
scaling factor: 1
query mode: simple
number of clients: 8
number of threads: 8
maximum number of tries: 1
duration: 60 s
number of transactions actually processed: 3744
number of failed transactions: 910 (19.553%)
latency average = 53.883 ms
latency stddev = 96.487 ms
initial connection time = 5.369 ms
tps = 62.280893 (without initial connection time)We can actually see the new changes in this release as we can see a new column reported with the number of failed transactions. I want to know what those errors are and luckily, there are new flags available to help diagnose them.
The first flag we're going to look at is --failures-detailed, according to the documentation, tells what type of error was encountered.
If you want to group failures by basic types in per-transaction and aggregation logs, as well as in the main and per-script reports, use the --failures-detailed option. If you also want to distinguish all errors and failures (errors without retrying) by type including which limit for retries was exceeded and how much it was exceeded by for the serialization/deadlock failures, use the --verbose-errors option.
pgbench \
--host=${PGHOST} \
--no-vacuum \
--file=tpcb-original.sql@1 \
--client=8 \
--jobs=8 \
--username=${PGUSER} \
--port=${PGPORT} \
-T 60 \
-P 5 \
--failures-detailed \
${PGDATABASE}The output is almost identical to the previous run except that there's now a printout of the error type breakdown.
pgbench (15.1 (Debian 15.1-1.pgdg110+1), server 13.0.0)
progress: 5.0 s, 67.6 tps, lat 53.902 ms stddev 88.922, 77 failed
progress: 10.0 s, 65.2 tps, lat 53.563 ms stddev 112.669, 71 failed
progress: 15.0 s, 63.8 tps, lat 58.647 ms stddev 120.207, 63 failed
progress: 20.0 s, 60.8 tps, lat 57.994 ms stddev 93.959, 79 failed
progress: 25.0 s, 60.0 tps, lat 60.510 ms stddev 106.972, 66 failed
progress: 30.0 s, 60.0 tps, lat 64.018 ms stddev 134.952, 65 failed
progress: 35.0 s, 58.8 tps, lat 56.540 ms stddev 124.230, 63 failed
progress: 40.0 s, 55.4 tps, lat 61.082 ms stddev 118.396, 67 failed
progress: 45.0 s, 54.2 tps, lat 63.425 ms stddev 136.734, 63 failed
progress: 50.0 s, 54.4 tps, lat 51.040 ms stddev 93.799, 61 failed
progress: 55.0 s, 53.8 tps, lat 58.612 ms stddev 111.643, 49 failed
progress: 60.0 s, 52.0 tps, lat 68.291 ms stddev 162.096, 49 failed
transaction type: tpcb-original.sql
scaling factor: 1
query mode: simple
number of clients: 8
number of threads: 8
maximum number of tries: 1
duration: 60 s
number of transactions actually processed: 3537
number of failed transactions: 773 (17.935%)
number of serialization failures: 773 (17.935%)
number of deadlock failures: 0 (0.000%)
latency average = 59.180 ms
latency stddev = 118.538 ms
initial connection time = 4.954 ms
tps = 58.809107 (without initial connection time)This however does not completely help us, we'd like to see the actual error. This is where the --verbose-errors flag will help.
pgbench \
--host=${PGHOST} \
--no-vacuum \
--file=tpcb-original.sql@1 \
--client=8 \
--jobs=8 \
--username=${PGUSER} \
--port=${PGPORT} \
-T 60 \
-P 5 \
--failures-detailed \
--verbose-errors \
${PGDATABASE}Please note that based on your selected scale, number of clients and jobs, you may see a lot of errors printed to the standard output. I'm going to paste a snippet of the output below:
pgbench: client 0 got an error in command 8 (SQL) of script 0; ERROR: restart transaction: TransactionRetryWithProtoRefreshError: WriteTooOldError: write for key /Table/109/5/1/0 at timestamp 1671745430.647963376,1 too old; wrote at 1671745430.647963376,2: "sql txn" meta={id=89ac4f55 key=/Table/108/5/86171/0 pri=0.03358629 epo=0 ts=1671745430.647963376,2 min=1671745430.381413084,0 seq=2} lock=true stat=PENDING rts=1671745430.647963376,1 wto=false gul=1671745430.881413084,0
HINT: See: https://www.cockroachlabs.com/docs/v22.2/transaction-retry-error-reference.html
pgbench: client 6 got an error in command 7 (SQL) of script 0; ERROR: restart transaction: TransactionRetryWithProtoRefreshError: WriteTooOldError: write for key /Table/107/5/1/0 at timestamp 1671745430.647963376,2 too old; wrote at 1671745430.647963376,3: "sql txn" meta={id=925b9e95 key=/Table/108/5/29407/0 pri=0.04748963 epo=0 ts=1671745430.647963376,3 min=1671745430.178895167,0 seq=1} lock=true stat=PENDING rts=1671745430.647963376,2 wto=false gul=1671745430.678895167,0
HINT: See: https://www.cockroachlabs.com/docs/v22.2/transaction-retry-error-reference.html
transaction type: tpcb-original.sql
scaling factor: 1
query mode: simple
number of clients: 8
number of threads: 8
maximum number of tries: 1
duration: 60 s
number of transactions actually processed: 3321
number of failed transactions: 793 (19.276%)
number of serialization failures: 793 (19.276%)
number of deadlock failures: 0 (0.000%)
latency average = 58.854 ms
latency stddev = 116.682 ms
initial connection time = 4.846 ms
tps = 55.253480 (without initial connection time)We see WriteTooOldError error which is indicative of the type of errors our customers encounter working with serializable isolation. You may read more about it here.
TLDR:
The RETRY_WRITE_TOO_OLD error occurs when a transaction A tries to write to a row R, but another transaction B that was supposed to be serialized after A (i.e., had been assigned a higher timestamp), has already written to that row R, and has already committed. This is a common error when you have too much contention in your workload.
Action:
Retry transaction A as described in client-side retry handling. Design your schema and queries to reduce contention. For more information about how contention occurs and how to avoid it, see Transaction Contention. In particular, if you are able to send all of the statements in your transaction in a single batch, CockroachDB can usually automatically retry the entire transaction for you.
We can actually diagnose some of these errors in our graphs, I'm still trying to understand the significance of some of these metrics but generally, they should match the output in pgbench.
Our SQL metrics graph has a lot of useful information, the graph titled Transactions shows the number of explicit transactions started, committed, rolled back and aborted.
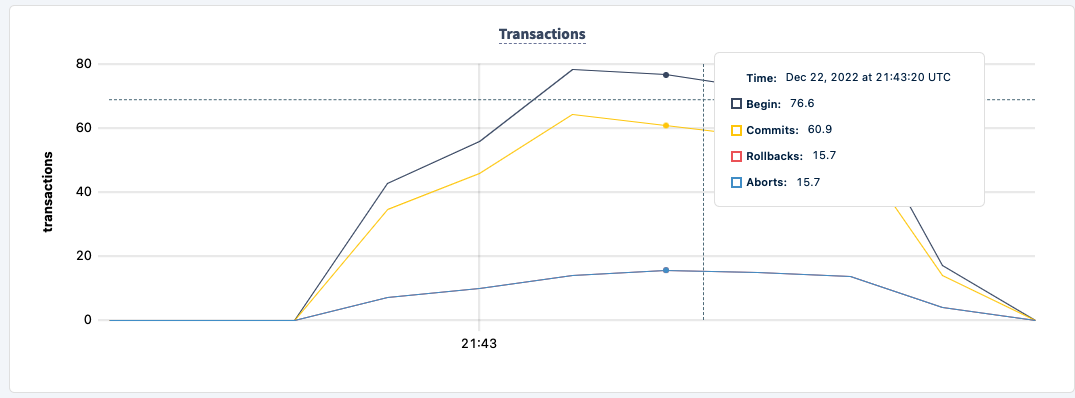
Right beneath it is the Transaction Restarts graph and it shows the type of error it is, in our case WriteTooOld, which matches the pgbench output.
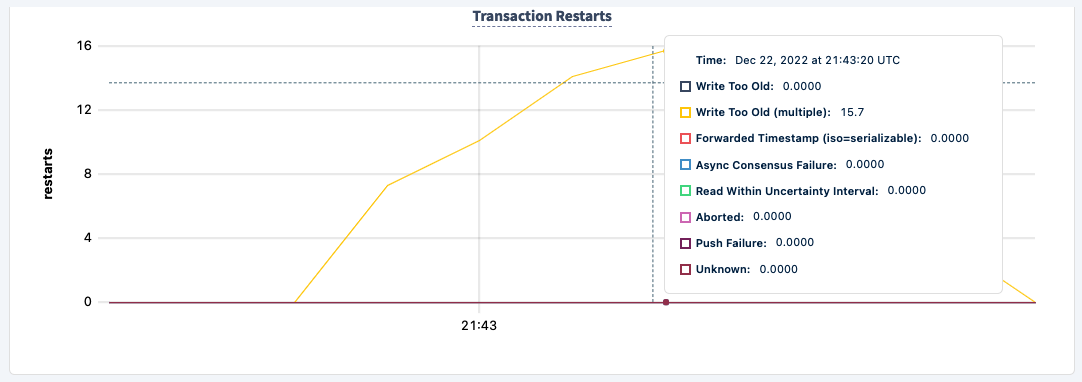
Finally, you can build your own charts using our metrics endpoint, these are some of the metrics I've used to create it.

cr.node.txn.restarts.writetoooldmulti should align with the total number of retried transactions.
So this is a bit vague and frankly, it's taken me three years to finally grasp the full scope of the suggested actions. All of which I am going to discuss in another article.
The very first thing our docs suggest is to retry the transaction. Prior to pgbench 15, it was almost impossible to do that easily aside from rewriting the entire transaction. Luckily in pgbench 15, there's a new flag --max-tries which we can test. For the history lesson on retries and pgbench, see this PostgreSQL mailing list thread and here are the release notes and the associated commit.
pgbench \
--host=${PGHOST} \
--no-vacuum \
--file=tpcb-original.sql@1 \
--client=8 \
--jobs=8 \
--username=${PGUSER} \
--port=${PGPORT} \
-T 60 \
-P 5 \
--failures-detailed \
--max-tries=10 \
${PGDATABASE}I am going to remove the --verbose-errors flag and set the max number of retries to 10 for each failed transaction.
pgbench (15.1 (Debian 15.1-1.pgdg110+1), server 13.0.0)
progress: 5.0 s, 67.4 tps, lat 85.255 ms stddev 231.402, 0 failed, 25 retried, 46 retries
progress: 10.0 s, 62.0 tps, lat 122.934 ms stddev 487.495, 1 failed, 23 retried, 55 retries
progress: 15.0 s, 62.0 tps, lat 107.072 ms stddev 305.696, 1 failed, 22 retried, 56 retries
progress: 20.0 s, 61.6 tps, lat 119.062 ms stddev 417.415, 1 failed, 21 retried, 64 retries
progress: 25.0 s, 58.0 tps, lat 125.793 ms stddev 430.424, 1 failed, 24 retried, 58 retries
progress: 30.0 s, 58.6 tps, lat 140.971 ms stddev 617.675, 0 failed, 16 retried, 46 retries
progress: 35.0 s, 58.6 tps, lat 81.551 ms stddev 286.200, 0 failed, 12 retried, 27 retries
progress: 40.0 s, 58.2 tps, lat 140.664 ms stddev 650.855, 2 failed, 22 retried, 62 retries
progress: 45.0 s, 56.0 tps, lat 131.902 ms stddev 471.914, 0 failed, 18 retried, 47 retries
progress: 50.0 s, 55.6 tps, lat 128.803 ms stddev 489.761, 1 failed, 19 retried, 51 retries
progress: 55.0 s, 53.6 tps, lat 151.977 ms stddev 542.671, 0 failed, 20 retried, 50 retries
progress: 60.0 s, 52.4 tps, lat 141.545 ms stddev 564.669, 0 failed, 18 retried, 37 retries
transaction type: tpcb-original.sql
scaling factor: 1
query mode: simple
number of clients: 8
number of threads: 8
maximum number of tries: 10
duration: 60 s
number of transactions actually processed: 3527
number of failed transactions: 7 (0.198%)
number of serialization failures: 7 (0.198%)
number of deadlock failures: 0 (0.000%)
number of transactions retried: 244 (6.904%)
total number of retries: 607
latency average = 124.266 ms
latency stddev = 478.738 ms
initial connection time = 6.491 ms
tps = 58.637923 (without initial connection time)Unfortunately, we did not avoid the retry errors but given the new flag, we were able to retry the failed transactions and gain back some of the lost performance; with every retry, we lose throughput. This is critical when you work with CockroachDB and any other database operating in serializable isolation. In prior versions of pgbench, it was almost impossible to make CockroachDB perform well, see this thread.
As my next attempt, let's run with the prepared protocol.
pgbench \
--host=${PGHOST} \
--no-vacuum \
--file=tpcb-original.sql@1 \
--client=8 \
--jobs=8 \
--username=${PGUSER} \
--port=${PGPORT} \
-T 60 \
-P 5 \
--failures-detailed \
--max-tries=10 \
--protocol=prepared \
${PGDATABASE}pgbench (15.1 (Debian 15.1-1.pgdg110+1), server 13.0.0)
progress: 5.0 s, 50.0 tps, lat 132.328 ms stddev 416.383, 0 failed, 18 retried, 35 retries
progress: 10.0 s, 67.6 tps, lat 122.414 ms stddev 441.751, 0 failed, 24 retried, 56 retries
progress: 15.0 s, 65.2 tps, lat 118.577 ms stddev 334.954, 0 failed, 28 retried, 57 retries
progress: 20.0 s, 64.0 tps, lat 129.559 ms stddev 376.413, 0 failed, 31 retried, 71 retries
progress: 25.0 s, 61.8 tps, lat 122.356 ms stddev 372.969, 0 failed, 29 retried, 56 retries
progress: 30.0 s, 62.4 tps, lat 106.271 ms stddev 406.478, 1 failed, 16 retried, 43 retries
progress: 35.0 s, 57.6 tps, lat 122.098 ms stddev 438.269, 0 failed, 16 retried, 36 retries
progress: 40.0 s, 56.2 tps, lat 174.903 ms stddev 727.915, 0 failed, 22 retried, 57 retries
progress: 45.0 s, 53.0 tps, lat 146.768 ms stddev 515.078, 0 failed, 19 retried, 43 retries
progress: 50.0 s, 56.4 tps, lat 109.192 ms stddev 397.583, 0 failed, 19 retried, 31 retries
progress: 55.0 s, 51.8 tps, lat 147.378 ms stddev 595.257, 0 failed, 18 retried, 43 retries
progress: 60.0 s, 51.8 tps, lat 157.949 ms stddev 657.722, 1 failed, 16 retried, 51 retries
transaction type: tpcb-original.sql
scaling factor: 1
query mode: prepared
number of clients: 8
number of threads: 8
maximum number of tries: 10
duration: 60 s
number of transactions actually processed: 3495
number of failed transactions: 2 (0.057%)
number of serialization failures: 2 (0.057%)
number of deadlock failures: 0 (0.000%)
number of transactions retried: 261 (7.464%)
total number of retries: 588
latency average = 132.740 ms
latency stddev = 483.151 ms
initial connection time = 6.533 ms
tps = 58.149559 (without initial connection time)The prepared protocol didn't make a difference.
Throughout the entire article, I've used the tpcb-like workload with the five statements representing the explicit business transaction. I also chose to use foreign key constraints. If I were to forgo tpcb-like and opt for the simple-update and select-only workloads or remove the foreign key constraints, the performance would likely be better. That's a trade-off for the application developer, whether you choose correctness or speed. I am going to stop here and cover other workarounds in a follow-up article.
Opinions expressed by DZone contributors are their own.
Comments