Vibe Coding With GitHub Copilot: Optimizing API Performance in Fintech Microservices
Can GitHub Copilot optimize fintech APIs? We test its performance, help, vibe coding flow, real-world impact, and limits.
Join the DZone community and get the full member experience.
Join For FreeIn fintech, APIs power everything. Starting from payments to trading to real-time customer experiences, the API takes care of everything. Performance isn't optional, but it's critical for user trust and business success.
As a fintech API and cloud optimization expert, I constantly face the challenge of balancing quick development with high performance. When Microsoft announced GitHub Copilot for free, I asked myself a real-world question: Can GitHub Copilot go beyond writing boilerplate code and help optimize fintech Microservice APIs?
Through a practical exercise on building and optimizing a real-world fintech microservice, we evaluate how GitHub Copilot accelerates development where expert judgment remains crucial. I used GitHub Copilot to:
- Build a high-throughput, stateless transaction API in Flask.
- Identify bottlenecks through load testing under realistic traffic.
- Apply AI-suggested performance improvements such as caching and concurrency enhancements.
- Compare Copilot's output with manual, industry-grade optimizations based on fintech best practices.
Along the way, I will also highlight the strengths and limitations of AI-assisted coding, particularly in high-demand environments of fintech systems.
Prerequisite Setup
If you're new to Flask or need help setting up your development environment, check out my previous DZone article, where I walk through the full setup, installation, and basic app creation using GitHub Copilot.
Once your Flask app environment is ready, continue here to focus on performance optimization for fintech-grade microservices.
Step 1: Setting Up a Fintech Transaction API With GitHub Copilot
1. Create a New Flask Microservice Project
(Setup instructions remain the same: create virtual environment, install Flask, enable Copilot.)
2. Let GitHub Copilot Generate the Transaction Processing Endpoint
In the VSCode project, open routes.py (this is the file where the application's API routes would be generated by Copilot), type the comment below, and press enter. Then, we will see the API generated, which will be used for performance optimization.
# Create a Flask API endpoint /process_transaction to process financial transactions. Accept account_id, amount, currency, transaction_type, timestamp.
# Validate required fields, return success response with transaction details.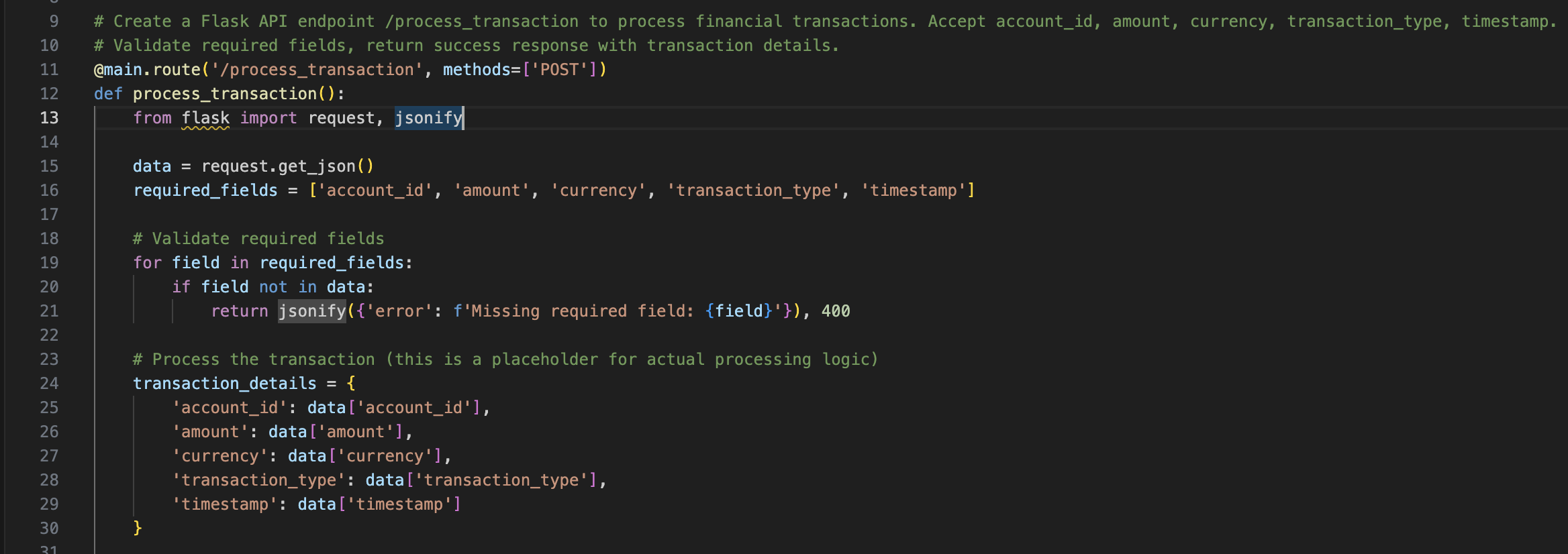
Fintech realism: Handling transaction-specific fields properly.
Step 2: Load Testing the Fintech API
1. Run the App
Let's first begin with building and running the application locally by starting the Flask application.
source venv/bin/activate
export FLASK_APP="app:create_app"
flask runOnce the application is up and running, open another terminal in VSCode, where we will be triggering the load testing to analyze what is happening when 1000 transactions are requested concurrently.
2. Create a Realistic Payload File (transaction_data.json)
Create a payload and place it under the project root directory. A sample JSON is shown below.
{
"account_id": "ACC987654",
"amount": 150.00,
"currency": "USD",
"transaction_type": "debit",
"timestamp": "2025-04-25T10:30:00Z"
}3. Simulate Load With Apache Benchmark
Open a new terminal parallel to the one that is running the Flask app. To evaluate how well the API handles multiple concurrent transaction requests, I have used Apache Benchmark (ab), a lightweight tool for simple load testing. The following command simulates 1000 transaction requests with 50 concurrent users against the /process_transaction endpoint.
ab -n 1000 -c 50 -p transaction_data.json -T application/json http://127.0.0.1:5000/process_transaction
Running 1000 transaction requests at a concurrency level of 50 gave me the following results:
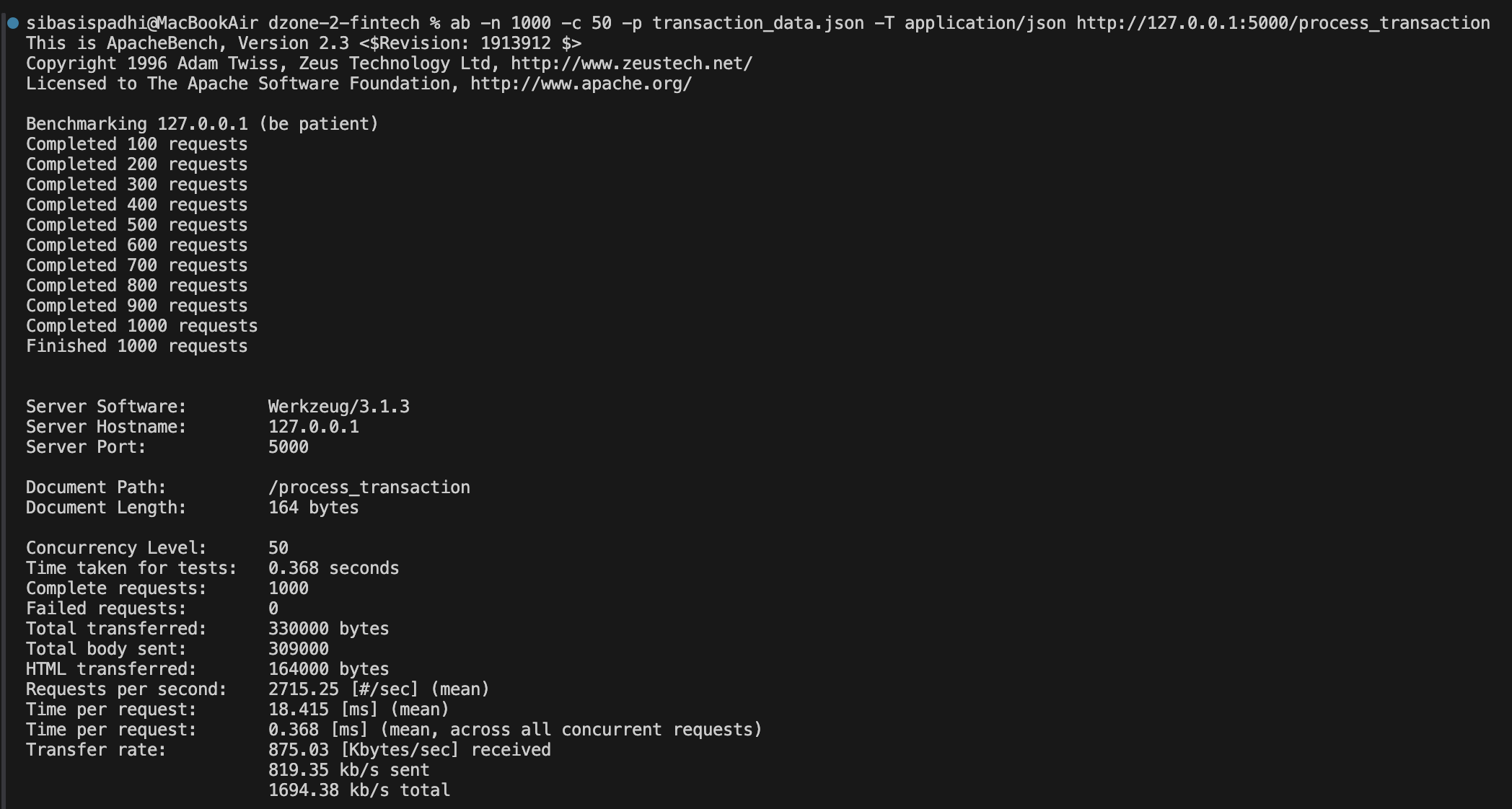
- Requests per second: ~2715
- Mean time per request: ~18 ms
- 99th percentile latency: ~45 ms
- No failed requests observed.
- No major CPU spikes at this basic processing level.
This shows that, in a local development environment, even a basic Flask server can handle a high transaction rate, efficiently for simple payloads. However, in real fintech environments, API performance is lower due to additional layers like database read-write, encryption, network latencies, and compliance checks.
APIs in a production environment would likely require further optimization, e.g., asynchronous handling, horizontal scaling, and caching layers to sustain similar throughput under real-world conditions.
Step 3: Optimizing the Transaction API Using Copilot
1. Adding Caching to Improve Performance
Adding caching is the standard approach that everyone, and even I, would take to improve the performance, but that is a standard approach we can use. Copilot would suggest using flask-caching to improve the performance. I left it to readers to try this option.
However, we want to check for a production-ready application; when we prompt Copilot, what does it suggest?
2. Improving Concurrency With Gunicorn
Prompted Copilot: # How to improve concurrency for production deployment, and press enter. We will see that the copilot suggests using Gunicorn, which is great!
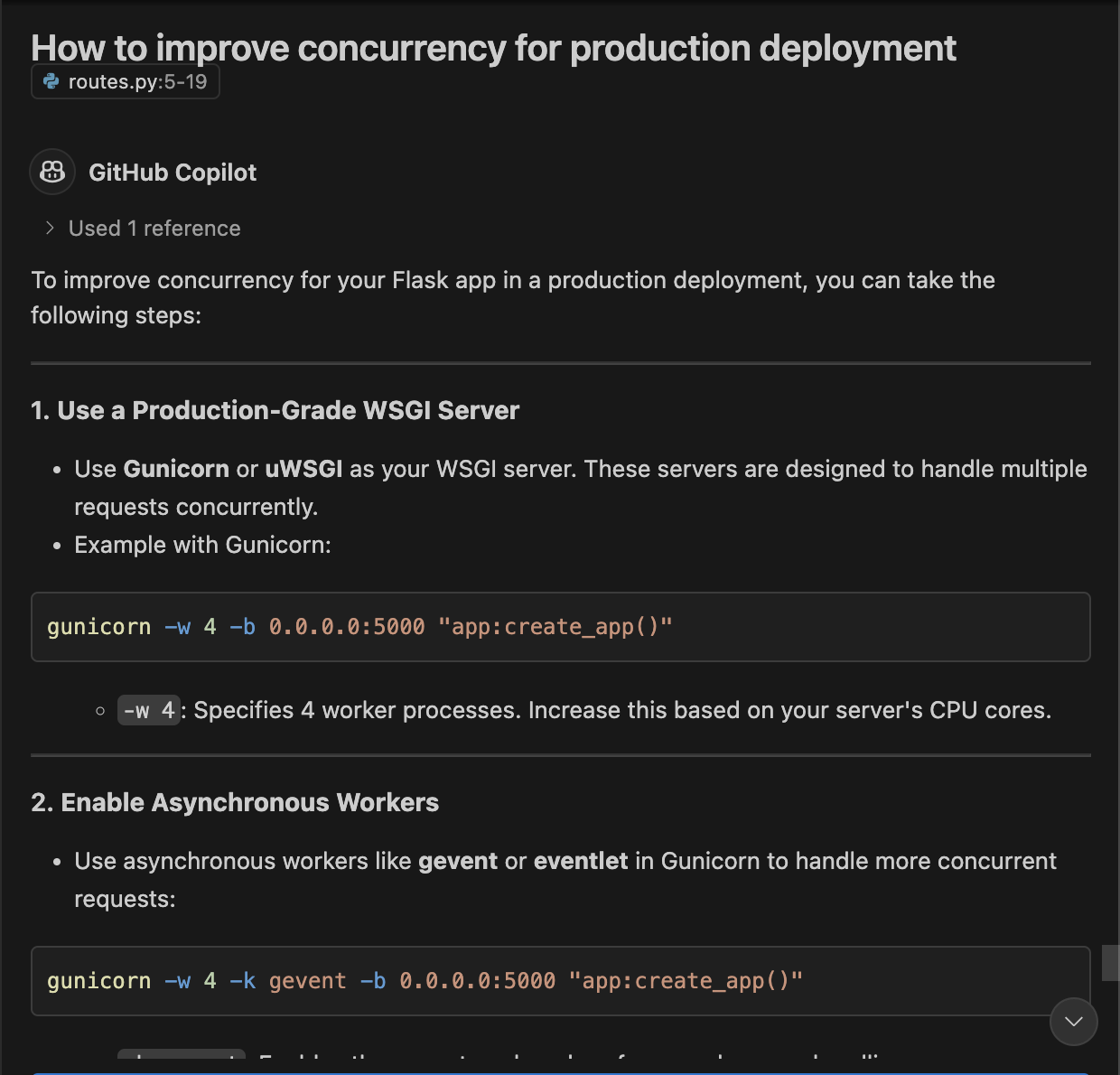
Now, let's stop or close the Flask terminal, which was still running. In a fresh terminal, let's install gunicorn and start the server.
pip install gunicorn
gunicorn -w 4 -b 127.0.0.1:5000 app:appWe see that Copilot suggested a production-ready concurrency model (Gunicorn with workers) directly in the flow. The result: Handled far more concurrent requests smoothly and reduced processing time significantly.
Running 1000 transaction requests in Gunicorn at a concurrency level of 50 resulted in:
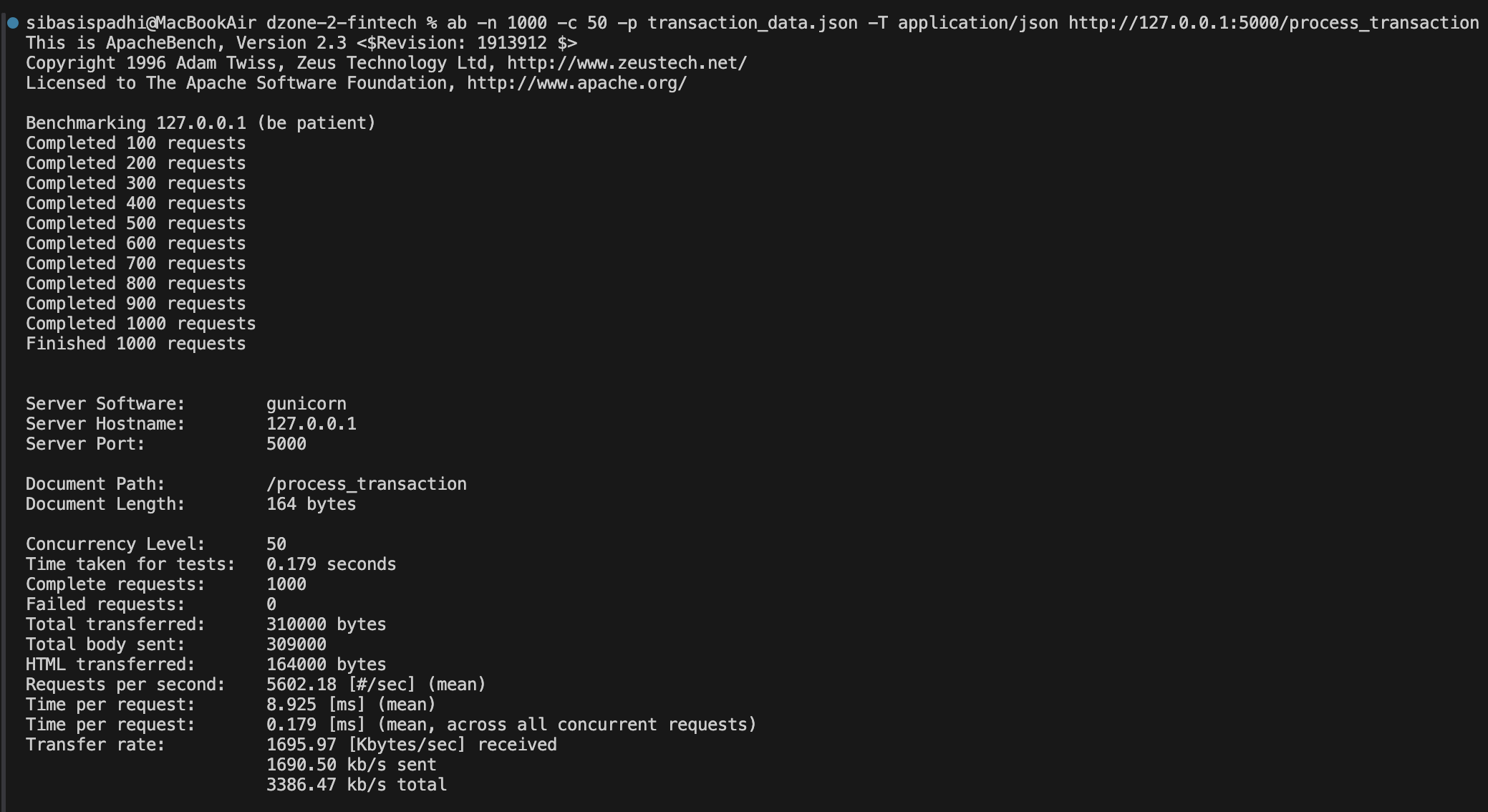
- Requests per second: ~5602
- Mean time per request: ~8.9 ms
- 99th percentile latency: ~15 ms
- Failed requests: 0
We observe that: Requests/sec more than doubled compared to Flask Dev Server. Latency dropped from ~45ms to ~15ms. Server stability remained excellent.
Step 4: Final Performance Benchmark
Copilot-assisted caching and concurrency setups improved real-world throughput significantly under load.
| Metric | flask dev server (before) | gunicorn optimized (After) |
|---|---|---|
|
Requests/sec
|
~2715
|
~5602
|
|
99th Percentile Latency
|
~45 ms
|
~15 ms
|
|
CPU Usage
|
Low to Moderate (locally)
|
Optimized across workers
|
Key Learnings (From API Tuning)
Let me summarize the key learnings we saw and researched with Copilot's assistance, and when manual expertise was needed.
| area | copilot assistance | manual expertise needed |
|---|---|---|
|
Initial API Setup
|
Generated fully
|
None
|
|
Transaction Field Handling
|
Basic validation hints
|
Stronger validation
|
|
Caching Layer
|
Flask-Caching suggested
|
Redis in production (by most experts)
|
|
Concurrency Setup
|
Gunicorn suggestion
|
Worker/memory tuning
|
|
Security/Fraud Detection
|
None
|
Must design separately
|
Conclusion
Building high-performance APIs for fintech isn't just about functionality. It's about speed, reliability, and scale. GitHub Copilot accelerated initial development and suggested meaningful performance optimizations, such as caching and concurrency improvements. However, tuning for production readiness, scaling decisions, and security still require human expertise.
The real advantage lies in vibe coding: Staying in flow, building fast, and applying best practices quickly. But by leaving critical architecture and risk assessment to experienced developers.
While the optimizations showed minimal impact under a simple local setup initially, running the app behind Gunicorn demonstrated clear advantages. In production-grade fintech systems, such optimizations become essential to meet scalability, latency, and resilience requirements.
Are you curious to see how AI-assisted development continues to evolve for fintech-grade performance? Stay tuned, we're just getting started.
Opinions expressed by DZone contributors are their own.
Comments