Optimizing String Comparisons in Go
Join the DZone community and get the full member experience.
Join For FreeWant your Go programs to run faster? Optimizing string comparisons in Go can improve your application’s response time and help scalability. Comparing two strings to see if they’re equal takes processing power, but not all comparisons are the same. In a previous article, we looked at How to compare strings in Go and did some benchmarking. We’re going to expand on that here.
It may seem like a small thing, but as all great optimizers know, it’s the little things that add up. Let’s dig in.
Measuring Case Sensitive Compares
First, let’s measure two types of string comparisons.
Method 1: Using Comparison Operators
xxxxxxxxxx
if a == b { return true
}else { return false
}
Method 2: Using Strings.Compare
xxxxxxxxxx
if strings.Compare(a, b) == 0 { return true
}
return false
So we know the first method is a bit easier. We don’t need to bring in any packages from the standard library, and it’s a bit less code. Fair enough, but which one is faster? Let’s find out.
Initially, we’re going to set up a single app with a test file. We’re going to use the Benchmarking utility from the Go test tools.
compare.go
xxxxxxxxxx
package main
import (
"strings"
)
func main() {
}
// operator compare
func compareOperators(a string, b string) bool { if a == b {
return true
}else {
return false
}
}
// strings compare
func compareString(a string, b string) bool { if strings.Compare(a, b) == 0 {
return true
}
return false
}
And we’ll create a set of tests for it:
compare_test.go
xxxxxxxxxx
package main
import (
"testing"
)
func BenchmarkCompareOperators(b *testing.B) {
for n := 0; n < b.N; n++ {
compareOperators("This is a string", "This is a strinG")
}
}
func BenchmarkCompareString(b *testing.B) {
for n := 0; n < b.N; n++ {
compareString("This is a string", "This is a strinG")
}
}
For the string samples, I will change the last character to make sure the methods parse the entire string.
Some Notes if you’ve never done this:
- We are using the Go testing package
- By naming it compare_test.go Go knows to look for tests here.
- Instead of tests, we insert benchmarks. Each func must be preceded by Benchmark
- We will run our tests with bench flag
To run our benchmarks, use this command:
xxxxxxxxxx
go test -bench=.
Here are my results:

So using standard comparison operators is faster than using the method from the Strings package. 7.39 nanoseconds vs. 2.92.
Running the test several times shows similar results:
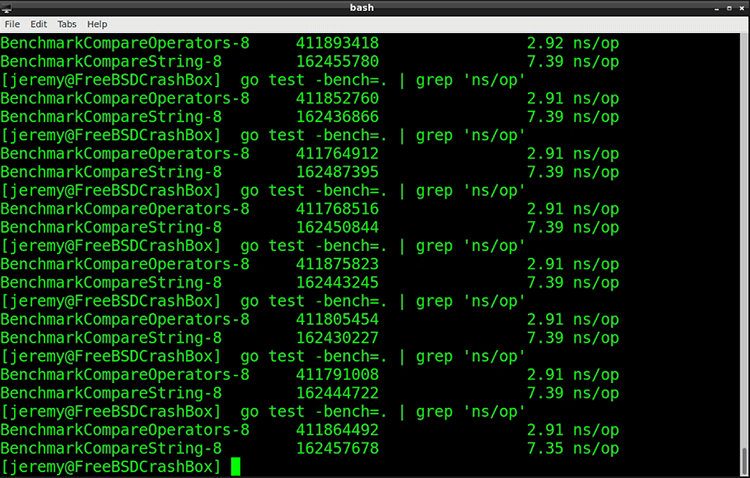
So, it’s clearly faster. 5ms can make a big difference at a large enough scale.
Verdict: Basic string comparison is faster than strings package comparison for case sensitive string compares.
Measuring Case Insensitive Compares
Let’s change it up. Generally, when I’m doing a string compare, I want to see if the test in the string matches, no matter which characters are capitalized. This adds some complexity to our operation.
xxxxxxxxxx
sampleString := "This is a sample string"
compareString := "this is a sample string"
With a standard compare, these two strings are not equal because the T is capitalized.
However, we are now looking for the text, and don’t care how it’s capitalized. So let’s change our functions to reflect this:
xxxxxxxxxx
// operator compare
func compareOperators(a string, b string) bool {
if strings.ToLower(a) == strings.ToLower(b) {
return true
}
return false
}
// strings compare
func compareString(a string, b string) bool {
if strings.Compare(strings.ToLower(a), strings.ToLower(b)) == 0 {
return true
}
return false
}
Now before each comparison, we make both strings lowercase. We’re adding in some extra cycles to be sure. Let’s benchmark them.
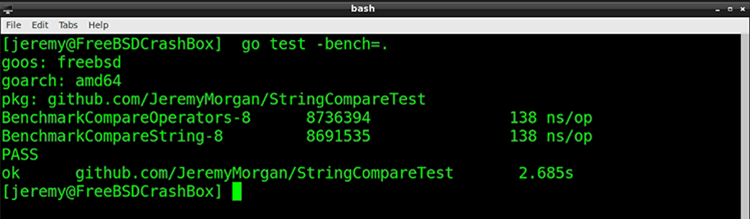
They appear to be the same. I run it a few times to be sure:
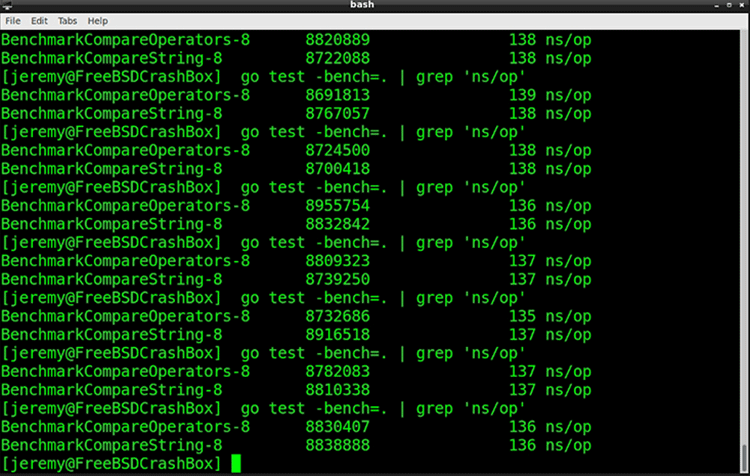
Yep, they’re the same. But why?
One reason is, we’ve added the Strings.ToLower action to every execution. This is a performance hit. Remember strings are simple runes, and the ToLower() method loops through the rune, making every character lowercase, then performs a comparison. This extra time washes out any big differences between the actions.
Introducing EqualFold
In our last article, we looked at EqualFold as another way of doing case insensitive compares. We determined Equalfold was the fastest of the three methods. Let’s see if this set of benchmark reflects that.
Add this to compare.go
xxxxxxxxxx
// EqualFold compare
func compareEF(a string, b string) bool {
if strings.EqualFold(sampleString, compareString) {
return true
}else {
return false
}
}
And add the following test to compare_test.go
xxxxxxxxxx
func BenchmarkEqualFold(b *testing.B) {
for n := 0; n < b.N; n++ {
compareEF("This is a string", "This is a strinG")
}
}
So lets now run a benchmark on these three methods:

Wow! EqualFold is considerably faster. I run it several times with the same results.
Why is it faster? BecauseEqualfold also parses the rune character by character, but it “drops off early” when it finds a different character.
Verdict: EqualFold (Strings Package) comparison is faster for case sensitive string compares.
Let’s Ramp Up Our testing
Ok, so we know these benchmarks show significant differences between the methods. Let’s add in some more complexity, shall we?
In the last article, we added in this 200,000 line word list to make comparisons. We’ll change our methods to open up this file and run string comparisons till we find a match.

In this file, I added the name we’re searching for at the end of the file, so we know the test will loop through 199,000 words before matching.
Change your methods to look like this:
compare.go
xxxxxxxxxx
// operator compare
func compareOperators(a string) bool {
file, err := os.Open("names.txt")
result := false;
if err != nil {
log.Fatalf("failed opening file: %s", err)
}
scanner := bufio.NewScanner(file)
scanner.Split(bufio.ScanLines)
for scanner.Scan() {
if strings.ToLower(a) == strings.ToLower(scanner.Text()) {
result = true
}else {
result = false
}
}
file.Close()
return result
}
// strings compare
func compareString(a string) bool {
file, err := os.Open("names.txt")
result := false;
if err != nil {
log.Fatalf("failed opening file: %s", err)
}
scanner := bufio.NewScanner(file)
scanner.Split(bufio.ScanLines)
for scanner.Scan() {
if strings.Compare(strings.ToLower(a), strings.ToLower(scanner.Text())) == 0 {
result = true
}else {
result = false
}
}
file.Close()
return result
}
// EqualFold compare
func compareEF(a string) bool {
file, err := os.Open("names.txt")
result := false;
if err != nil {
log.Fatalf("failed opening file: %s", err)
}
scanner := bufio.NewScanner(file)
scanner.Split(bufio.ScanLines)
for scanner.Scan() {
if strings.EqualFold(a, scanner.Text()) {
result = true
}else {
result = false
}
}
file.Close()
return result
}
Yes, each of these are now going to:
- Open a text file
- Parse it line by line
- Look for the search phrase
Let’s change our tests now, so the funcs only take one parameter:
compare_test.go
xxxxxxxxxx
func BenchmarkCompareOperators(b *testing.B) {
for n := 0; n < b.N; n++ {
compareOperators("Immanuel1234")
}
}
func BenchmarkCompareString(b *testing.B) {
for n := 0; n < b.N; n++ {
compareString("Immanuel1234")
}
}
func BenchmarkEqualFold(b *testing.B) {
for n := 0; n < b.N; n++ {
compareEF("Immanuel1234")
}
}
So now, we can expect the test to take longer, so there will be fewer iterations from the benchmarking tool. Let’s run it:
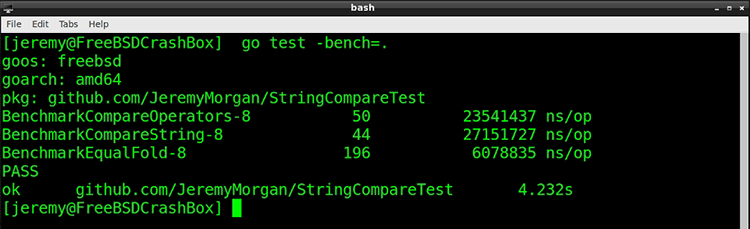
And EqualFold still comes out on top, by quite a bit.
Adding to the complexity of this test is good and bad.
Good: Reading in text and doing sequential tests is more “real life” simulation Good: We can force more diverse testing with different strings Bad: We introduce several factors (file reading, etc.) that could skew our results.
Verdict: EqualFold (Strings Package) comparison is STILL faster for case sensitive string compares.
But Wait, There’s More!!
Is there any way we can make this comparison even faster? Of course. I decided to try counting the characters of the string. If the character count is different, it’s not the same string, so we can “duck out early” on the comparison altogether.
But we still need to include EqualFold in case the strings are equal length but different characters. The added check of the count makes the operation more expensive, so would it be faster? Let’s find out.
compare.go
xxxxxxxxxx
func compareByCount(a string) bool {
file, err := os.Open("names.txt")
result := false;
if err != nil {
log.Fatalf("failed opening file: %s", err)
}
scanner := bufio.NewScanner(file)
scanner.Split(bufio.ScanLines)
for scanner.Scan() {
if len(a) == len(scanner.Text()) && strings.EqualFold(a, scanner.Text()){
result = true
}else {
result = false
}
}
file.Close()
return result
}
compare_test.go
xxxxxxxxxx
func BenchmarkCompareByCount(b *testing.B){
for n := 0; n < b.N; n++ {
compareByCount("Immanuel1234")
}
}
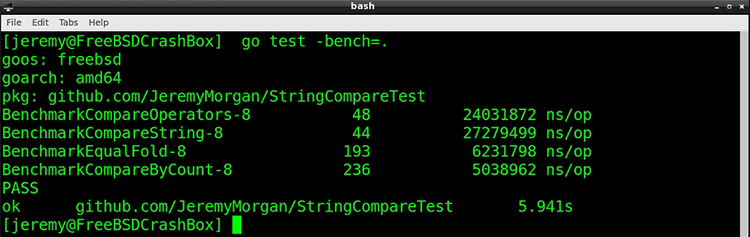
And it is indeed faster! Every little bit counts.
Verdict: Do a character count with your EqualFold comparison for even more speed
Summary
In this article, we looked at a few different string comparison methods and which one is faster. Bottom line: Use a basic comparison for case sensitive comparisons, and character count + EqualFold for case insensitive comparisons.
I love doing tests like this, and you’ll find small changes add up pretty nice when you’re doing optimization. Stay tuned for more articles where we look at optimizations like this.
What do you think? Let me know!
Published at DZone with permission of Jeremy Morgan. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments