Ordering in Event-Sourced Systems
Ordering is extremely important in Event-Sourced Systems. Let's find out how what guarantees Event Store can provide in terms of ordering!
Join the DZone community and get the full member experience.
Join For FreeIn a utopian world, Event Store will write events to the disk in the same order they have happened in real life. However, computers are not so good at observing things by themselves (yet); we (still) must tell them what to do. Hence, we must provide a way to deterministically order events inside the Event Store.
A naive approach would be to attach a timestamp to each and every event and use it for ordering. The reason for its naiveness lies in the difficulty of synchronizing clocks across different machines in a distributed system. As a consequence, we mustn't rely on timestamps for ordering.
Since we also cannot impose ordering of events sent by different Event Store clients among them, the only thing left is to accept the ordering of received events by the Event Store. In other words, the order in which Event Store receives events is going to be the order of events written to the disk. This means that two events could have happened in one order in reality, but they are written in a different order on the disk. And this is acceptable as long as these two events are not related (not in conflict).
Each and every Event Store must provide a mechanism to detect conflicts between appends* (append conflict) and a way to resolve the append conflict. One of the solutions to this challenge is the Dynamic Consistency Boundary.
To give an example, events for two different bank accounts are not related and could be written in one order that differs from the order that happened in reality. However, if they are related to the same bank account, they must be written in the exact same order (see Diagram 1). In the diagram, two clients want to withdraw money from the green bank account. In order to maintain consistency, the Event Store must detect this situation as a conflicting one.
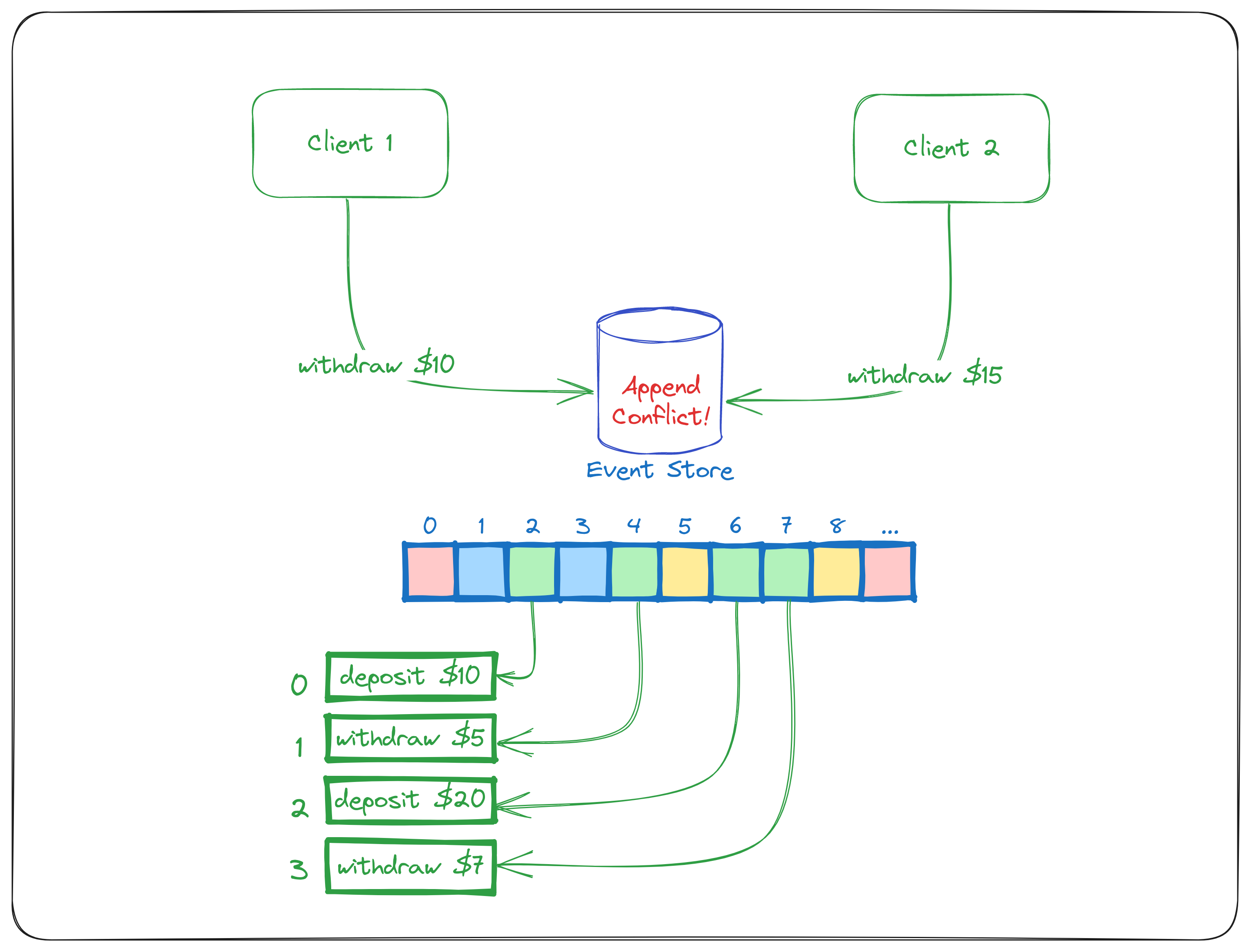
Once event transactions** are received, the Event Store will accept the receiving order as THE order, detect the conflicting transactions, resolve append conflicts, and write them to disc. Voila! The Event Store determined the order, and from this point on, whenever we read events from the Event Store, they are always going to be read in the same order.
When there is only one replica of the Event Store in the system, the order of events on that instance is the total order of events in general.
Clustered Event Store
Of course, surviving in the wild with a single replica of the Event Store is maybe too brave. Therefore, Event Store must be clustered. Each node in the Event Store cluster must have a copy of all events - events are replicated across the cluster. In cases when some nodes in the cluster are down, others can serve events. What does this mean for ordering? Are we able to preserve the total order of events on all nodes in a cluster?
The short answer is yes! Luckily for us, there are protocols that resolve this kind of issue. They are called Consensus Protocols; one typical representative is RAFT. Usually, protocols that guarantee the total order have a single node that acts as the leader of the cluster, and it replicates data across the cluster. This means that all appends must go through the leader. Essentially, we are back to the previous scenario, where we had only one replica of the Event Store, and the total order was guaranteed. Now, this single replica (the leader) replicates events to other nodes, and we have the total order on all nodes (see Diagram 2). You may ask, what happens if the leader fails? And that is a completely valid question; luckily (again), this situation is covered by the very same protocols; in most cases, there is an election that results in a new leader.
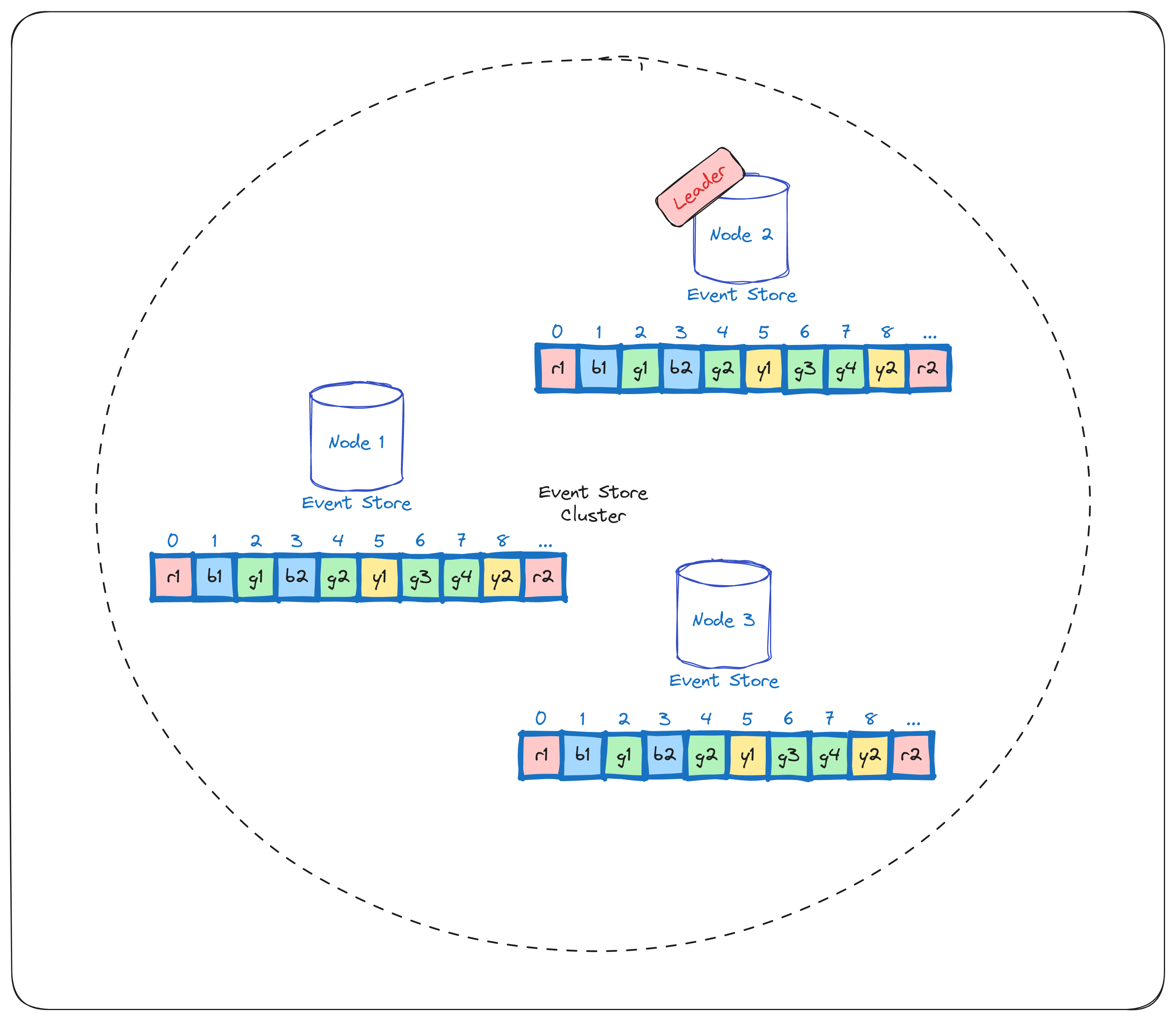
Another valid question would be, isn't the leader a bottleneck? The answer is yes; the leader is the bottleneck. However, unlike previous situations, we are not so lucky; we just have to accept this fact.
Although the leader is the bottleneck for appends, it is not the bottleneck for reads required for (re-)building View Models. I'll leave it up to You to answer why that is. (Hint question: do we need to reach the consensus while reading events for View Models?)
Recap
The total order of events in event-sourced systems provides ease with designing and reasoning about systems. In a single-replica Event Store deployment, the total order is not difficult to achieve. The easiest way to provide the total order of events in a clustered Event Store is to use single-leader Consensus Protocols. However, this approach comes with a price; the leader is the bottleneck for append operations.
* Append is an Event Store operation that accepts events and stores them durably on disk in an append-only fashion.
** An Event Transaction is a single append operation with one or more events that are stored in an ACID manner.
Published at DZone with permission of Milan Savic. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments