ORMs: Heroes or Villains Inside the Architecture?
In the information age, with new technologies, frameworks, and programming languages, there is an aspect of technology that never changes.
Join the DZone community and get the full member experience.
Join For Free
In the information age, with new technologies, frameworks, and programming languages, there is an aspect of technology that never changes. All applications need a storage integration related to their system; either SQL or NoSQL, to point out that there is a different paradigm among the development team and the database team. To make developer life easier, new frameworks emerged that convert between the application layer and the database, which includes the famous ORM. Indeed, contemporary challenges appear such as how to handle different paradigms that are in software development and how to make a regular development without impacting on the database.
When there is a discussion about an application, the first step is to clean some approaches that include design and architecture: architecture is the software process that handles flexibility, scalability, usability, security, and other points that looks more to the business perspective directly. Some architecture samples:
- Serverless Architecture: Serverless architectures are application designs that incorporate third-party “Backend as a Service” (BaaS) services and include custom code run in managed, ephemeral containers on a “Functions as a Service” (FaaS) platform.
- Event-Driven Architecture: It is a software architecture pattern promoting the production, detection, consumption of, and reaction to events.
- Microservices Architecture: It is a variant of the service-oriented architecture (SOA) style that structures an application as a collection of loosely coupled services. In a microservices architecture, services are fine-grained and the protocols are lightweight.
The design has a low-level duty that supervises the code, such as what each module is going to do, the class's scope, the functions proposal, and so on.
- SOLID: The five design principles intended to make software designs more understandable, flexible, and maintainable.
- Design Patterns: They are ideal solutions to common problems in software design. Each pattern is like a blueprint that you can customize to solve a particular design problem in your code.
Design and architecture have broad concepts and points of views. The application is becoming more involved with several integrations with several systems. To solve the most common software engineering issue, there is an ancient Roman strategy: divide and conquer. This path is a good strategy because it breaks the complexity into small pieces. Furthermore, it allows scalability to have more people working on the goal.
The first view is the physical one. The tier has three parts: a view tier (the client request), logic tier (the server), and the data tier (where the data is stored). Within the server tier, there are several layers to split responsibility and to get cohesion such as Model-View-Controller. Going more in-depth on the bridge between database tier and logic tier to follow the best practices, there is a layer to communicate among data. In the logic tier in the Java world, there is the Data Acess Object that provides an abstract interface to some databases.

The challenge here is that there are several paradigms to both developers and DBAs, with specific standards such as OOP, functional programming to developers, and relational, key-value, and graph-to-data managers. Thereby, from a software perspective, it needs a converter between the data paradigm and software paradigm.
The hardcoding takes a long time and is sometimes a waste and is a repetitive work that might generate an error because of the human factor. To make this interpretation process more comfortable and also reduce the number of bugs, several exchange frameworks were born.
This abstraction usually has a high price to pay on the database performance. The problem is too much focus on the domain and the developer forgets the database formation; remember, it's still not an OOP database. There are two ways to do the software/database translation:
The first one is the active record. The most fabulous archive here is the simplicity to connect model and database. An entity extends from a model class that has several database connections. Once all database operations are atomic, that means it needs a commit on a transaction to each method operation, if the system requires three thousand actions atomically, by default, its results on the same number of an unnecessary amount of instead of one. Furthermore, the model has a high coupling with the database technology once it extends the model.
A Java implementation of ActiveRecord is ActiveJDBC that, given a Person class, extends from the Model.
public class Person extends Model {}
Person person = new Person("Ada","Lovelace");
person.saveIt();
Person ada = Person.findFirst("name = ?", "Ada");
String name = ada.get("name");
ada.delete();
List<Person> people = Person.where("name = 'Ada'");The last translator is the mapper, and the goal is to map the entities with annotation, and the operation is outside the class. It brings advantages, such as a more natural way to keep the high cohesion in the class, and explicit database control, but it increases the complexity of the code.
Several mapper implementations include them to a relational database, that is the ORM. In the Java world, the specification is the JPA.
@Entity
public class Person {
@Id
private String name;
@Column
private String lastName;
}
EntityManager manager = getEntityManager();
manager.getTransaction().begin();
Person person = new Person("Ada","Lovelace");
manager.persist(person);
manager.getTransaction().commit();
List<Person> people = manager.createQuery("SELECT p from Person where p.name = @name")
.setParameter("name", "Ada").getResultList();There is an essential fact about the database and these converters. No matter how robust the converters are, there is an Object-relational impedance mismatch factor. In other words, there is a blank between two paradigms such as encapsulation, accessibility, interface, inheritance, and polymorphism, which has support on OOP but not in a relational database.
To solve the data integrity issue, the rich model can handle it: an object hides data to expose their behaviors, and there are also other good practices such as Builder pattern, fluent API, DSL, and so on.
In an architecture view, there is the Clean Architecture book that explicitly some concepts: Split what matters, in other words, business from the infrastructure code. An infrastructure code is where all the I/O components go: the UI, database, frameworks, devices, etc. It's the most volatile layer. It has some pros:
- A rich model has a business focus.
- The repository layer will abstract the database interaction; therefore, the client does not need to know where this data comes from, such as NoSQL, SQL, REST, and so on.
- The repositories implementation became a layer that will have a layer with both the repository implementation and data structure database oriented.
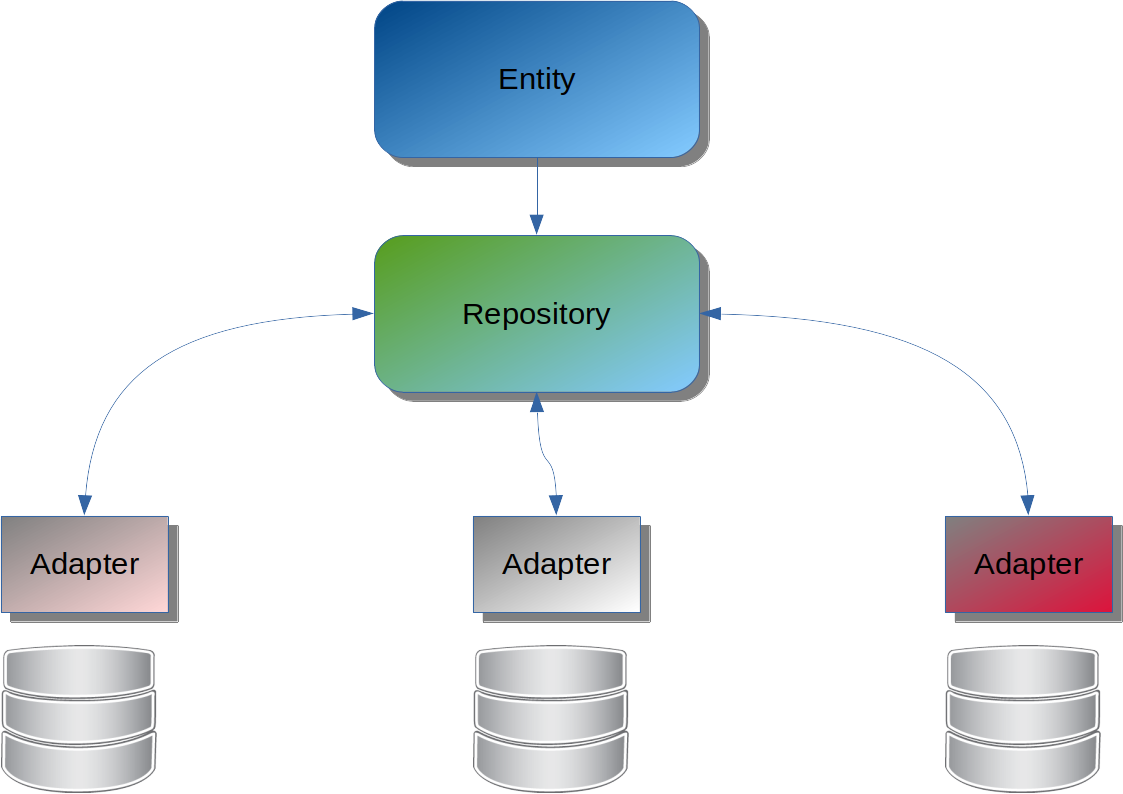
This repository layer is a good strategy, where it fits an adapter class to a database. It allows both a rich model to software development and a specific model/structure oriented to the storage technology target and with no impact on both. Furthermore, it smooth to change this adapter layer to another one without effects in the code, so we also can call him a peace layer because that is a win-win way to both developer and DBA. It has damaged the simplicity because of increase one more layer to the developer side.
This post covered the benefits and disadvantage of use converters between the developed world and the persistence world such as NoSQL and SQL. In an architecture view, it is essential to check the trade-off to each choice, such as the simplicity of ActiveRecord issues in performance degradation. A mapper grows the complexity, but it brings more benefits to a database once the developer creates the model to the database and once the developer doesn't use the automatic generation and prioritize the normalization model process. On the architecture scope, an abstraction layer to split the rich model entity from the database structure has several benefits, such as a better experience on OOP and a data-driven design at the same time; however, it grows the application with one more layer.
Opinions expressed by DZone contributors are their own.
Comments