Throttling Made Easy: Back Pressure in Akka Streams
Learn how to use Akka Streams as a built-in protocol to attain overflow and underflow in fast data systems.
Join the DZone community and get the full member experience.
Join For FreeBig data is the buzzword all over lately, but fast data is also gaining traction. If you are into data streaming, then you know it can be tedious if not done right and may result in data leaks/OutOfMemory exceptions. If you are building a service or product today, users are willing to pay lots of money to those who provide content with latency of just milliseconds.
Akka Streams
Akka Streams are a streaming module that is part of the Akka toolkit, designed to work with huge data streams to achieve concurrency in a non-blocking way by leveraging Akka toolkit's power without defining actor behaviors and methods explicitly. They also help to conceal the abstraction by ignoring what is going under the hood and help you focus on the logic needed for business.
Akka Streams are compatible with handling almost all data sources and types out there with its open-source module Alpakka.
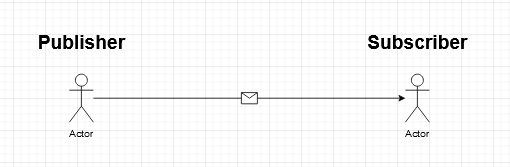
When you think of a stream, you picture a starting point from where the stream begins and an ending point where the stream ends. I want you to think about Akka streams the same way. Your role is to transform and analyze what happens in between.
- Publisher: Starting point of the stream
- Subscriber: Ending point of the stream
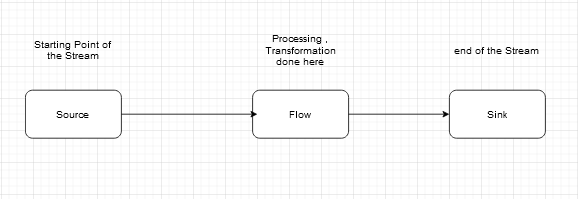
Akka Streams use operators as detailed below to ingest, process, transform, and store the data:
- Source: An operator with exactly one output, emitting data elements whenever downstream operators are ready to receive them.
- Flow: An operator with exactly one input and output, which connects its upstream and downstream by transforming the data elements flowing through it.
- Sink: An operator with exactly one input requesting and accepting data elements.
Let’s write some code and break it into what’s happening:
x
import akka.stream.scaladsl.{Source, Flow, sink}
val source = Source(1 to 1000)
val multiply = Flow[Int].map(x => x * 10)
val sink = Sink.foreach[Int](println)
Apply the methods of Source and Flow as follows (Sink don't have an “apply” method):
xxxxxxxxxx
//Source
def apply[T](iterable: Iterable[T]): Source[T, NotUsed]
//Flow
def apply[T]: Flow[T, T, NotUsed]
Here, our source emits values from 1 to 1,000 in order and is transformed at the Flow operator by a map function printed to the console/terminal at the Sink. This is quiet a small computation and will not result in latency issues or back pressure.
We can tie the operations with Akka's rich library:
x
source.via(multiply).to(sink).run()
You have created a graph here which is runnable.
A Flow that has both ends “attached” to a Source and Sink respectively is ready to be run() and is called a RunnableGraph.
How is this happening without you configuring and telling the program how to run the graph?
Even after constructing the RunnableGraph by connecting all the Source, Sink, and different operators, no data will flow through it.
This is where materialization comes into action!
Stream Materialization
When constructing flows and graphs in Akka Streams, think of them as preparing a blueprint/execution plan. Stream materialization is the process of taking a stream description and allocating all the necessary resources it needs in order to run. This means starting up Actors to power the processing and do much more under the hood depending on what the stream needs.
After running (materializing) the RunnableGraph, we get back the materialized value of specified type. Every stream operator can produce a materialized value, and it is your responsibility to combine them to a new type. Akka has .toMat to indicate that we want to transform the materialized value of the Source and Sink, and you have the convenient function (Keep.right/left/both/none) to say that we are only interested in the materialized value of the sink.
If you are using Akka classic actors, you need to manually initialize the materializer and make it an implicit.
implicit val actorMaterializer = ActorMaterializer()
But to Akka Typed, this is deprecated as it is implicitly imported into the scope.
Note: The “apply” method in the object ActorMaterializer is deprecated (since 2.6.0). Use the system wide materializer with stream attributes or configuration settings to change defaults.
Required import:
xxxxxxxxxx
import akka.stream.scaladsl.Keep
//keep right
source.via(multiply).toMat(sink)(Keep.right).run()
//keep left
source.via(multiply).toMat(sink)(Keep.left).run()
//keep both
source.via(multiply).toMat(sink)(Keep.both).run()
//keep none
source.via(multiply).toMat(sink)(Keep.none).run()
You can use .viaMat to apply this on Flow. Example:
xxxxxxxxxx
//keep right
source.viaMat(multiply)(Keep.right).to(sink).run()
//keep left
source.viaMat(multiply)(Keep.left).to(sink).run()
//keep both
source.viaMat(multiply)(Keep.both).to(sink).run()
//keep none
source.viaMat(multiply)(Keep.none).to(sink).run()
By default, Akka streams keep/return the left value (Source) of the materialized value.
Code snippet:
import akka.actor.typed.scaladsl.Behaviors
import akka.actor.typed.ActorSystem
import akka.stream.scaladsl.{Flow, Sink, Source}
object backPressure extends App {
implicit val system: ActorSystem[Nothing] = ActorSystem(Behaviors.empty,"backPressure-example")
val source = Source(1 to 10)
val multiply = Flow[Int].map(x => x* 10)
val sink = Sink.foreach[Int] (println)
source.via(multiply).to(sink).run()
}
Let’s talk about the magic that happens under the hood now.
Back Pressure
Let’s say the source is producing data quickly enough and Sink is consuming the data slowly with a one-second delay.
xxxxxxxxxx
val source = Source(1 to 1000)
val multiply = Flow[Int].map(x => x* 10)
val sink = Sink.foreach[Int] {
Thread.sleep(1000)
(println)
}
Here, when the source is sending the data to the Sink via Flow, the Sink tries to consume the data and buffer it first. When the flow exceeds the limit, the Sink sends the signal back to the Flow to slow down. Flow will attempt slow down the data ingestion. If it fails to do so, then it signals the Source to slow down. A ll this happens under the hood.
The stream max input buffer size is 16.
The Sink will buffer incoming data until the buffer size is exhausted and send the signal to the upstream to slow down.
Here, all the computation is happening on a single actor or thread.
We have a way to break this down and run the operations on different threads/Actors.
async
It’s as simple as adding the term explicitly after the end of each operator as such using the .async method. Being run asynchronously means that an operator, after handing out an element to its downstream consumer, is able to immediately process the next message.
xxxxxxxxxx
source.via(multiply).async
.to(sink).async
.run()
The order is always guaranteed but not sequential due to being asynchronous. Example:
xxxxxxxxxx
Source(1 to 3)
.map { i =>
println(s"A: $i"); i
}
.async
.map { i =>
println(s"B: $i"); i
}
.async
.map { i =>
println(s"C: $i"); i
}
.async
.runWith(Sink.ignore)
The output will be:
xxxxxxxxxx
A: 1
A: 2
B: 1
A: 3
B: 2
C: 1
B: 3
C: 2
C: 3
A: 1 , A: 2, A: 3 will always printed in order but other terms like B: 1 might be outputted in between due to its asynchronous nature.
Note that the order is not A:1, B:1, C:1, A:2, B:2, C:2,, which would correspond to the normal fused synchronous execution model of Flows where an element completely passes through the processing pipeline before the next element enters the flow. The next element is processed by an asynchronous operator as soon as it emits the previous one.
Akka Streams use a windowed, batching back pressure strategy internally. It is windowed because as opposed to a stop-and-wait protocol, multiple elements might be in-flight concurrently with requests for elements. It is also batching because a new element is not immediately requested once an element has been drained from the window buffer but multiple elements are requested after multiple elements have been drained. This batching strategy reduces the communication cost of propagating the backpressure signal through the asynchronous boundary.
Conclusion
Akka Streams are a proficient way to deal with data streams and can handle complexity to help you focus on the business to achive targets. Akka Streams comes with a built-in rich library and operators which are built on top of Akka Actors. The resulting asynchronousity and concurrency handles most of the jobs under the hood.
Learn more about Akka Streams at the official page: Akka Streams.
GraphDSL, custom graphs, and more coming soon... Thanks for reading and for the support.
Opinions expressed by DZone contributors are their own.
Comments