Implementing Locks in a Distributed Environment
Getting started with lock implementation in a distributed environment, using services such as Kafka, Cassandra, Transformer, and Rules Engine.
Join the DZone community and get the full member experience.
Join For FreeAs we know, locks are generally used to monitor and control access to shared resources by multiple threads simultaneously. They basically protect data integrity and atomicity in concurrent applications, i.e., only one thread at a time can acquire a lock on a shared resource, which otherwise is not accessible. But a lock in a distributed environment is more than just a mutex in a multi-threaded application. It is more complicated because the lock now has to be acquired across all the nodes, whereas any of the nodes in the cluster or the network can fail.
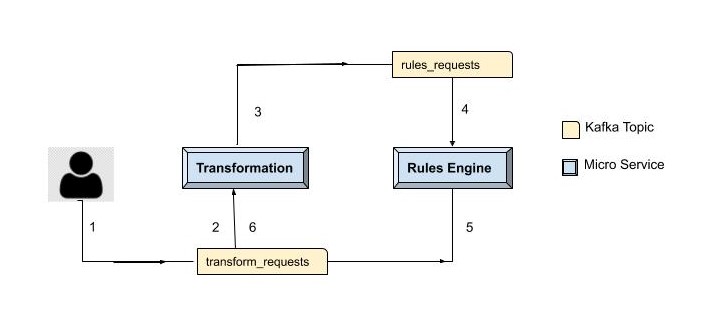
Here is the user story that we're going to consider to explain scenarios in the rest of this article. The application takes data in the user’s preferred format and converts it into a standardized format, like PDF, that can be uploaded to a government portal. There are two different micro-services of the application which do these things: Transformer and Rules Engine. We use Cassandra for persistence and Kafka as a message queue. Also, please note that the user request, once accepted, returns immediately. Once the PDF is generated, the user is notified about it asynchronously. This is achieved in a sequence of steps as follows:
- The user request is put into a message queue.
- Once the Transformer service picks up the user request, it transforms the user uploaded file into a format that Rules Engine can understand.
- Now the data is taken through Rules Engine, which updates the data points.
- Finally, the data is transformed into a PDF, and the user is notified.
Firstly, let us understand why we need to fetch locks at all in a distributed environment. The following are the use-cases we have used distributed locks for:
- Efficiency: This is to make sure that the same expensive computation does not happen multiple times. For example: suppose the user has uploaded a file for processing. As there is a heavier load on the system due to an increase in requests or because the current file is too large to be processed, it might take a while to generate the PDF. If the user becomes restless waiting to be notified, he may upload the file again for processing (now adding more load to the system unnecessarily). This can be avoided by taking a lock on the checksum of the file before processing it.
- Correctness: This is to avoid data corruption in the application. When we use locks, two concurrent/parallel processes do not mess up the underlying data. If two processes operate on the underlying data set simultaneously, without acquiring the lock, there is a high chance that the data might get corrupted. For example: Let's say we have got the sales transactions and the line item data from the user. The tax amount at the transaction level is calculated as the sum of tax already levied at the transaction level and any additional taxes at the line level. If rules are executed for the same transaction in 2 different nodes in parallel, there is a very good probability that the tax amount gets incremented twice for the line items. This can be avoided if we take a lock at the transaction level.
Please note that locks are often not seen as a good idea. The blocking operations increase the contention for the underlying resources, thereby limiting the system's computational capacity. Also, trying to lock in a distributed environment is supposed to be much more difficult and dangerous for the following reasons:
- What happens to the lock when a node which has acquired it has crashed without releasing it?
- How do we deal with cases of network partitioning?
These would bring in the additional dimension of consensus into the picture. We will get into the idea of distributed consensus in a while.
For all the above reasons, we should avoid these locks if any alternative solutions exist. Here are two possible approaches that can be used in the application:
- Optimistic Locking: The resources are not actually locked in this case. We check if the resource is updated by someone else before committing the transaction. If the data is stale, the transaction will be rolled back, and an error is thrown to the user indicating that. In contrary to this, pessimistic locking is when you take an exclusive lock so that no one else can modify the resource. For example, select-for-update locks in databases or Java locks. Hibernate provides support for optimistic locking.
- Usage of partitions in Kafka: As mentioned earlier, we have always kept the user requests in Kafka before processing them. It is done this way because availability is one of the core architectural principles of application. We did not want the application to crash when the load increases multiple folds during peak usage periods. Kafka stores messages published for a topic into multiple partitions internally. Also, it guarantees that messages from a given partition are always served to consumers in the same order as they are published. Leveraging this information, we can publish all requests that we don’t want to process in parallel (and hence use locks) to the same partition. This can be done by specifying a partition-key while publishing the message to Kafka. Messages with the same key will be published to the same partition. Now that the messages are taken up sequentially from the partition, we don’t need locks anymore.
There might still be cases where we prefer to take a distributed lock as they do not fit into the above scenarios. Distributed consensus comes into the picture when we talk about distributed locks. Distributed consensus can be defined as the process of getting all nodes in a cluster to agree on some specific value based on their votes. All nodes must agree upon the same value, and it must be a value submitted by at least one of the nodes. When a particular node is said to acquire a distributed lock in a cluster, the rest of the nodes in the cluster have to agree that the lock has been taken up by it. There are multiple consensus algorithms like Paxos, Raft, ZAB, Pacifica, and so on. I have given some links to explain these algorithms towards the end of the blog for those interested in it. Here are the two most general ways of implementing the consensus systems:
- Symmetric/leader-less: Here, all servers participating in the consensus have equal roles. So the client can connect to any one of the servers in this case. Example: Paxos.
- Asymmetric/leader-based: Here, at any given time, one server acts as the leader apart from those participating in the consensus. The rest of the servers accept the leader’s decisions. Here, clients can only communicate with the leader. Example: Raft, ZAB.
Lock Implementation
For decades, distributed consensus has become synonymous with Paxos. But now, there are different implementations, as discussed above. Raft overcomes some of the drawbacks of the traditional Paxos. For each of the algorithms mentioned above, there are different implementations. For example, Cassandra implemented Paxos for their lightweight transactions. Kafka internally uses Pacifica, whereas Zookeeper and Hazelcast use ZAB and Raft, respectively. Here is the generic interface of the distributed lock in our application:
xxxxxxxxxx
package common.concurrent.lock;
import java.util.concurrent.TimeUnit;
/**
* Provides interface for the distributed lock implementations based on Zookeeper and Hazelcast.
* @author pgullapalli
*/
public interface DistributedLock {
/**
* Acquires the lock. If the lock is not available, the current thread until the lock has been acquired.
* The distributed lock acquired by a thread has to be released by same thread only.
**/
void lock();
/**
* This is a non-blocking version of lock() method; it attempts to acquire the lock immediately, return true if locking succeeds.
* The distributed lock acquired by a thread has to be released by same thread only.
**/
boolean tryLock();
/**
* Acquires the lock. Blocks until the lock is available or timeout is expired.
* The distributed lock acquired by a thread has to be released by same thread only.
**/
boolean tryLock(long timeout, TimeUnit unit);
/**
* Checks if current thread has already acquire the lock.
* @return
*/
boolean isLocked();
/**
* Releases the lock. This method has to be called by same thread as which has acquired the lock.
*/
void release();
}
public interface DistributedLocker {
/**
* This method only fetches the lock object but does not explicitly lock. Lock has to be acquired and released.
* specifically
* @param key Fetch the lock object based on the key provided.
* @return Implementation of DistributedLock object
*/
DistributedLock getLock(String key);
}
For our application, here are the options that we have explored for implementing distributed locks:
a) InterProcessSemaphoreMutex from Zookeeper: Curator open-sourced by Netflix, a high-level API built on top of Zookeeper, which provides many recipes, and handles the complexity of managing connections and retrying operations to the underlying ZooKeeper ensemble. InterProcessSemaphoreMutex, a recipe from Curator Framework, is a re-entrant mutex that works across JVMs. It uses Zookeeper to hold the lock. All processes across JVMs that use the same lock path will achieve an inter-process critical section. Further, this mutex is “fair” – each user will get the mutex in the order requested (from Zookeeper’s point of view).
xxxxxxxxxx
package common.concurrent.lock.impl;
import common.concurrent.lock.DistributedLock;
import common.concurrent.lock.DistributedLocker;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessLock;
import org.apache.curator.framework.recipes.locks.InterProcessSemaphoreMutex;
import org.apache.curator.retry.ExponentialBackoffRetry;
import java.util.concurrent.TimeUnit;
public class ZKBasedDistributedLocker implements DistributedLocker {
private final CuratorFramework curatorClient;
private final String basePath;
public ZKBasedDistributedLocker(){
curatorClient = CuratorFrameworkFactory.newClient("localhost:2181",
new ExponentialBackoffRetry(1000, 3));
basePath = new StringBuilder("/config/sample-app/distributed-locks/").toString();
}
public DistributedLock getLock(String key) {
String lock = new StringBuilder(basePath).append(key).toString();
return new ZKLock(new InterProcessSemaphoreMutex(curatorClient, lock));
}
private class ZKLock implements DistributedLock {
private final InterProcessLock lock;
public ZKLock(InterProcessLock lock){
this.lock = lock;
}
public void lock() {
try {
lock.acquire();
} catch (Exception e) {
throw new RuntimeException("Error while acquiring lock", e);
}
}
public boolean tryLock() {
return tryLock(10, TimeUnit.MILLISECONDS);
}
public boolean tryLock(long timeout, TimeUnit unit) {
try {
return lock.acquire(timeout, unit);
} catch (Exception e) {
throw new RuntimeException("Error while acquiring lock", e);
}
}
public boolean isLocked() {
return lock.isAcquiredInThisProcess();
}
public void release() {
try {
lock.release();
} catch (Exception e) {
throw new RuntimeException("Error while releasing lock", e);
}
}
}
}
As Zookeeper is commonly used in many distributed systems, using this option does not need any additional frameworks for locking. One observation, however, is that the performance degraded as the number of locks increased. This is because all the locks are actually created as znodes internally. As the number of znodes started increasing, we even started facing problems while listing/deleting the locks folder in Zookeeper. So for cases where we take fewer locks, Zookeeper is a good fit. As many services of an application might depend on Zookeeper, any problem with Zookeeper might impact them. Few such use-cases are Microservices registering themselves for Service Discovery, Services using Kafka, which depends on Zookeeper, for leader election.
b) Lightweight Transactions from Cassandra: It is easy to achieve strong consistency in master based distributed systems. However, it also means that there is a compromise on the system's availability if the master is down. Cassandra is a master-less system and trades-off availability over consistency. It falls under the AP category of the CAP theorem, and hence is highly available and eventually consistent by default. Eventually consistent implies the read-after-write of a value may not yield the latest value written. But, we can achieve strong consistency in Cassandra by specifying the consistency level for the query as QUORUM. This quorum means that a write transaction would succeed only after writing it to a majority of servers. We can implement a lock in Cassandra as follows:
- create table lock_requests(resource_id text,lock_status text, created_on timestamp, primary key(resource_id));
- Thread which tries to acquire a lock checks if there exists an entry in locks table with specified key: select * from lock_requests where resource_id = ‘ABC’;
- If lock does not exist, now we say that the lock is acquired after inserting an entry into locks: insert into lock_requests(resource_id,lock_status,created_on) values(‘ABC’, ‘Locked’, toTimestamp(now()))
Please note that there is always a possibility of a race condition among threads between steps 2 and 3 if we do these as separate steps from the application. But if the database itself can check for row existence before insertion, the race condition can be avoided. This is referred to as linearizable consistency (i.e., Serial isolation level in ACID terms). Lightweight transactions do the same. So here is how steps 2 and 3 above can be combined:
insert into lock_requests(resource_id,lock_status,created_on) values('ABC', 'Locked', toTimestamp(now())) if not exists;
If the lock exists, the above write fails, and hence the lock is not acquired. The next problem is what happens if the service that acquired the lock has not released it. The server might have crashed, or the code might have thrown an exception. The lock will never get released. For such cases, we can define time-to-live (TTL) for the row. This means the lock row will automatically expire after the prescribed number of seconds. Here is how we can achieve it by defining TTL for every record of the row:
xxxxxxxxxx
create table lock_requests(resource_id text,lock_status text, created_on timestamp, primary key(resource_id)) with gc_grace_seconds=86400 and default_time_to_live=600;
Now the lock will automatically expire in 10 mins. This setting can be overridden for every row by defining TTL for all the columns. TTL might not help if we don’t have a rough estimate of how much time a computation (that is surrounded by the lock) can take.
xxxxxxxxxx
package common.concurrent.lock.impl;
import com.datastax.oss.driver.api.core.CqlSession;
import com.datastax.oss.driver.api.core.cql.BoundStatement;
import com.datastax.oss.driver.api.core.cql.PreparedStatement;
import com.datastax.oss.driver.api.core.cql.ResultSet;
import com.datastax.oss.driver.api.core.cql.Row;
import common.concurrent.lock.DistributedLock;
import common.concurrent.lock.DistributedLocker;
import org.apache.commons.lang3.time.StopWatch;
import java.net.InetSocketAddress;
import java.time.Instant;
import java.util.concurrent.TimeUnit;
public class CassandraDistributedLocker implements DistributedLocker {
private final CqlSession session;
private final PreparedStatement selectStatement, insertStatement, deleteStatement;
public CassandraDistributedLocker(){
session = CqlSession.builder()
.addContactPoint(new InetSocketAddress("127.0.0.1", 9042))
.withKeyspace("sample").build();
selectStatement = session.prepare(
"select * from lock_requests where resource_id=?");
insertStatement = session.prepare(
"insert into lock_requests(resource_id,lock_status,created_on) values(?,?,?) if not exists");
deleteStatement = session.prepare(
"delete from lock_requests where resource_id=? if exists");
}
public DistributedLock getLock(String key) {
return new CassandraLock(key);
}
private class CassandraLock implements DistributedLock{
private final String key;
public CassandraLock(String key) {
this.key = key;
}
public void lock() {
insertLock();
}
private boolean insertLock() {
BoundStatement boundStatement = insertStatement.bind()
.setString(0, key)
.setString(1, "LOCKED")
.setInstant(2, Instant.now());
ResultSet resultSet = session.execute(boundStatement);
return resultSet.wasApplied();// this is equivalent to row.getBool("applied")
}
public boolean tryLock() {
return tryLock(10, TimeUnit.MILLISECONDS);
}
public boolean tryLock(long timeout, TimeUnit unit) {
try {
boolean locked = false;
StopWatch stopWatch = StopWatch.createStarted();
while(stopWatch.getTime(TimeUnit.SECONDS) < timeout) {
if(insertLock()) {
locked = true;
break;
}
}
return locked;
} catch (Exception e) {
throw new RuntimeException("Error while acquiring lock", e);
}
}
public boolean isLocked() {
BoundStatement boundStatement = selectStatement.bind().setString(0, key);
ResultSet resultSet = session.execute(boundStatement);
Row row = resultSet.one();
return row != null ? "LOCKED".equals(row.getString("lock_status")) : false;
}
public void release() {
try {
BoundStatement boundStatement = deleteStatement.bind().setString(0, key);
session.execute(boundStatement);
} catch (Exception e){
throw new RuntimeException("Error while releasing lock", e);
}
}
}
}
Cassandra internally uses a modified version of Paxos for lightweight transactions implementation. It does 4 extra round-trips to achieve this linearizability. That sounds like a high cost – perhaps too high if you have the rare case of an application that requires every operation to be linearizable. But for most applications, only a tiny minority of operations require linearizability, which is a good tool to add to the strong/eventual consistency we’ve provided so far.
Of course, this solution is viable only if the application is already using Cassandra for persistence. We have also seen LWTs timing out under heavy loads, so it is better to exercise these locks with caution. One good thing about these locks is that no constraint exists that the lock has to be released by the one who acquired it. This might come in handy if we have such scenarios where one microservice takes a lock initially, and the other service releases it after the workflow completion asynchronously.
c) Distributed locks with Hazelcast: Hazelcast IMDG provides distributed versions of fundamental Java collections and synchronizers. The beauty of the Hazelcast API is that they are pretty simple to understand as they implement Java API itself. For Ex: com.hazelcast.map.IMap extends java.util.Map. So there is a lesser learning curve here. The distributed map implementation has a method to lock a specific key. If the lock is not available, the current thread is blocked until the lock has been released. We can get a lock on the key even if it is not present in the map. If the key does not exist in the map, any thread apart from the lock owner will get blocked if it tries to put the locked key in the map.
xxxxxxxxxx
package common.concurrent.lock.impl;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IMap;
import common.concurrent.lock.DistributedLock;
import common.concurrent.lock.DistributedLocker;
import java.util.concurrent.TimeUnit;
public class HzMapBasedDistributedLocker implements DistributedLocker {
private IMap txLockMap;
public HzMapBasedDistributedLocker(){
HazelcastInstance hazelcastInstance = Hazelcast.newHazelcastInstance();
txLockMap = hazelcastInstance.getMap("txLockMap");
}
public DistributedLock getLock(String lockKey) {
return new HzMapBasedLock(lockKey);
}
private class HzMapBasedLock implements DistributedLock{
private final String key;
public HzMapBasedLock(String key) {
this.key = key;
}
public void lock() {
txLockMap.lock(key);
}
public boolean tryLock() {
return txLockMap.tryLock(key);
}
public boolean tryLock(long timeout, TimeUnit unit) {
try {
return txLockMap.tryLock(key, timeout, unit);
} catch (Exception e) {
throw new RuntimeException("Error while acquiring lock", e);
}
}
public boolean isLocked() {
return txLockMap.isLocked(key);
}
public void release() {
try {
txLockMap.unlock(key);
} catch (Exception e){
throw new RuntimeException("Error while releasing lock", e);
}
}
}
}
Please note that Hazelcast IMDG implementation too falls under the AP category of the CAP system. However, strong consistency (even in failure/exceptional cases) is a fundamental requirement for any tasks that require distributed coordination. Hence, there are cases where the existing locks based on map implementation will fail. To address these issues, Hazelcast later came up with the CPSubsystem implementation. CPSubsystem has got a new distributed lock implementation on top of Raft consensus. The CPSubsystem lives alongside AP data structures of the Hazelcast IMDG cluster. CPSubsystem maintains linearizability in all cases, including client and server failures, network partitions, and prevent split-brain situations. In fact, Hazelcast claims that they are the one and only solution which offers a linearizable and distributed lock implementation.
x
package common.concurrent.lock.impl;
import com.hazelcast.config.Config;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.cp.lock.FencedLock;
import common.concurrent.lock.DistributedLock;
import common.concurrent.lock.DistributedLocker;
import java.util.concurrent.TimeUnit;
public class HzLockBasedDistributedLocker implements DistributedLocker {
private HazelcastInstance hazelcastInstance;
public HzLockBasedDistributedLocker(int cpMemberCount){
Config config = new Config();
config.getCPSubsystemConfig().setCPMemberCount(3);
config.getCPSubsystemConfig().setGroupSize(3);
hazelcastInstance = Hazelcast.newHazelcastInstance(config);
}
public DistributedLock getLock(String key) {
return wrapHzLock(key);
}
private DistributedLock wrapHzLock(String key){
return new HzLock(key);
}
private class HzLock implements DistributedLock {
private final FencedLock lock;
public HzLock(String key) {
this.lock = hazelcastInstance.getCPSubsystem().getLock(key);
}
public void lock() {
lock.lock();
}
public boolean tryLock() {
return lock.tryLock();
}
public boolean tryLock(long timeout, TimeUnit unit) {
try {
return lock.tryLock(timeout, unit);
} catch (Exception e) {
throw new RuntimeException("Error while acquiring lock", e);
}
}
public boolean isLocked() {
return lock.isLocked();
}
public void release() {
try {
lock.unlock();
//((DistributedObject) lock).destroy();
} catch (Exception e){
throw new RuntimeException("Error while releasing lock", e);
}
}
}
}
The above code looks pretty clean and simple. The problem is that locks never expire on their own in Hazelcast unless they are explicitly destroyed. If not destroyed and are often created, we may end up with out-of-memory exceptions over a period of time. The following from Hazelcast documentation clarifies the same:
xxxxxxxxxx
Locks are not automatically removed. If a lock is not used anymore, Hazelcast does not automatically perform garbage collection in the lock. This can lead to an OutOfMemoryError. If you create locks on the fly, make sure they are destroyed.
Although the fix looks trivial, i.e., uncomment the destroy line in the above code, the problem here is that a lock once destroyed can not be recreated in the same CP Group unless restarted. So, if you need to reuse the locks that were once released, we can not destroy them. In such cases, it is better to use map-based implementation itself. Based on the specific use-case, one can go with either of the implementations. Hazelcast may address the issue soon.
There are other frameworks like Redis, which offer distributed locks, that I have not explained here. I have listed them in the resources section. One final point to keep in mind is that it is always better to use these locks with caution. If any alternate solution does not require locks, it is better to go with that.
Additional Resources
Published at DZone with permission of Prasanth Gullapalli. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments