Package by Component and Architecturally-aligned Testing
Join the DZone community and get the full member experience.
Join For Freei've seen and had lots of discussion about "package by layer" vs "package by feature" over the past couple of weeks. they both have their benefits but there's a hybrid approach i now use that i call "package by component". to recap...
package by layer
let's assume that we're building a web application based upon the web-mvc pattern. packaging code by layer is typically the default approach because, after all, that's what the books, tutorials and framework samples tell us to do. here we're organising code by grouping things of the same type.
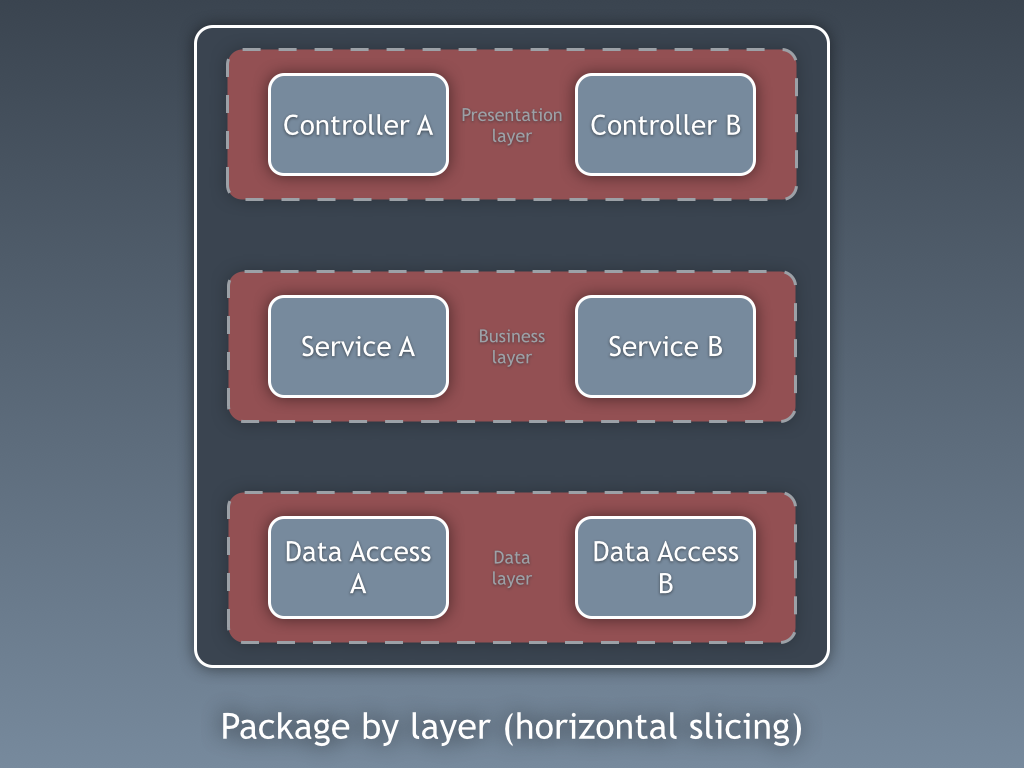
there's one top-level package for controllers, one for services (e.g. "business logic") and one for data access. layers are the primary organisation mechanism for the code. terms such as "separation of concerns" are thrown around to justify this approach and generally layered architectures are thought of as a "good thing". need to switch out the data access mechanism? no problem, everything is in one place. each layer can also be tested in isolation to the others around it, using appropriate mocking techniques, etc. the problem with layered architectures is that they often turn into a big ball of mud because, in java anyway, you need to mark your classes as public for much of this to work.
package by feature
instead of organising code by horizontal slice, package by feature seeks to do the opposite by organising code by vertical slice.
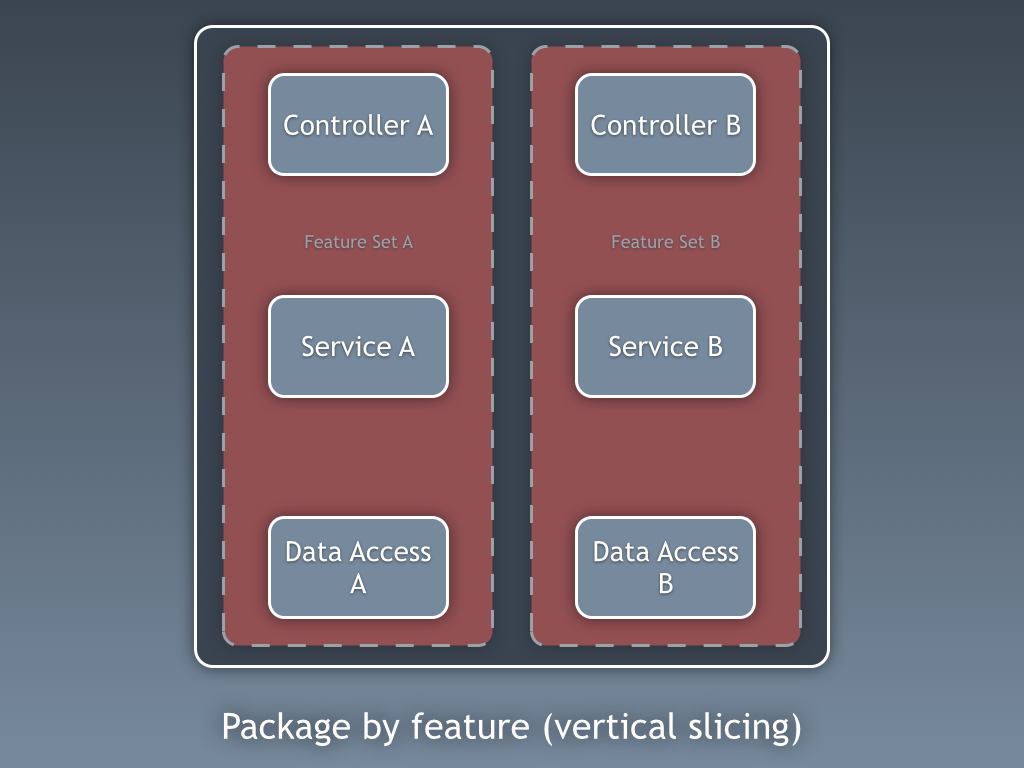
now everything related to a single feature (or feature set) resides in a single place. you can still have a layered architecture, but the layers reside inside the feature packages. in other words, layering is the secondary organisation mechanism. the often cited benefit is that it's "easier to navigate the codebase when you want to make a change to a feature", but this is a minor thing given the power of modern ides.
what you can do now though is hide feature specific classes and keep them out of sight from the rest of the codebase. for example, if you need any feature specific view models, you can create these as package-protected classes. the big question though is what happens when that new feature set c needs to access data from features a and b? again, in java, you'll need to start making classes publicly accessible from outside of the packages and the big ball of mud will again emerge.
package by layer and package by feature both have their advantages and disadvantages. to quote jason gorman from schools of package architecture - an illustration , which was written seven years ago.
to round off, then, i would urge you to be mindful of leaning to far towards either school of package architecture. don't just mindlessly put socks in the sock draw and pants in the pants draw, but don't be 100% driven by package coupling and cohesion to make those decisions, either. the real skill is finding the right balance, and creating packages that make stuff easier to find but are as cohesive and loosely coupled as you can make them at the same time.
package by component
this is a hybrid approach with increased modularity and an architecturally-evident coding style as the primary goals.
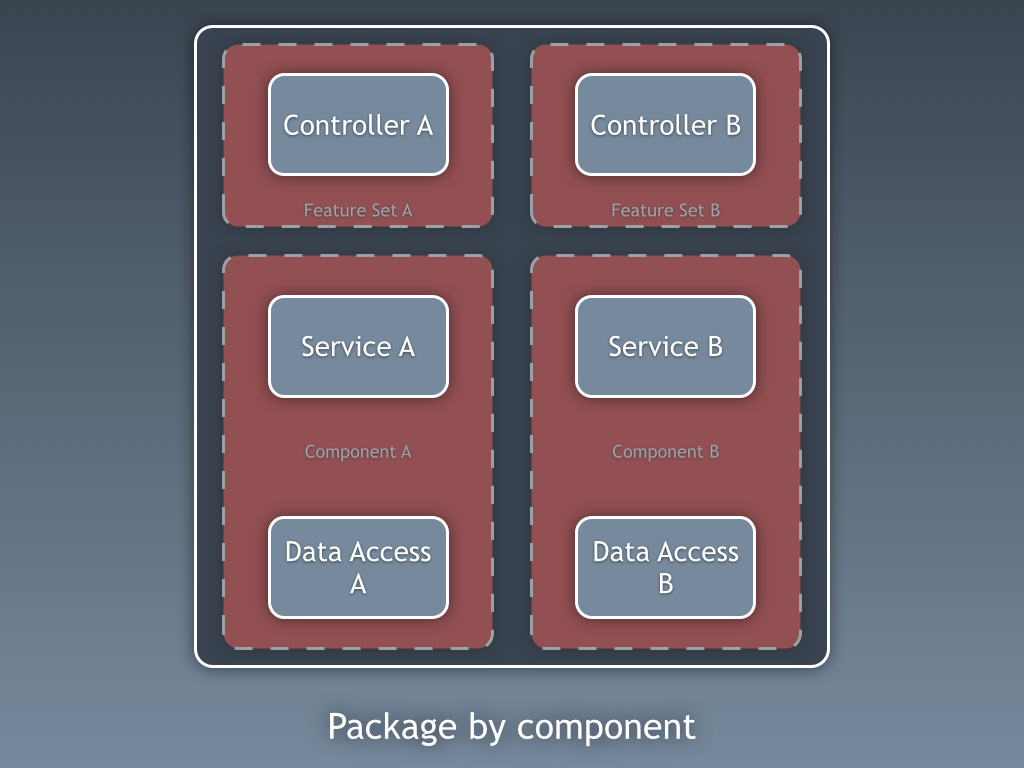
the basic premise here is that i want my codebase to be made up of a number of coarse-grained components, with some sort of presentation layer (web ui, desktop ui, api, standalone app, etc) built on top. a "component" in this sense is a combination of the business and data access logic related to a specific thing (e.g. domain concept, bounded context, etc). as i've described before , i give these components a public interface and package-protected implementation details, which includes the data access code. if that new feature set c needs to access data related to a and b, it is forced to go through the public interface of components a and b. no direct access to the data access layer is allowed, and you can enforce this if you use java's access modifiers properly. again, "architectural layering" is a secondary organisation mechanism. for this to work, you have to stop using the public keyword by default . this structure raises some interesting questions about testing, not least about how we mock-out the data access code to create quick-running "unit tests".
architecturally-aligned testing
the short answer is don't bother, unless you really need to. i've spoken about and written about this before, but architecture and testing are related. instead of the typical testing triangle (lots of "unit" tests, fewer slower running "integration" tests and even fewer slower ui tests), consider this.
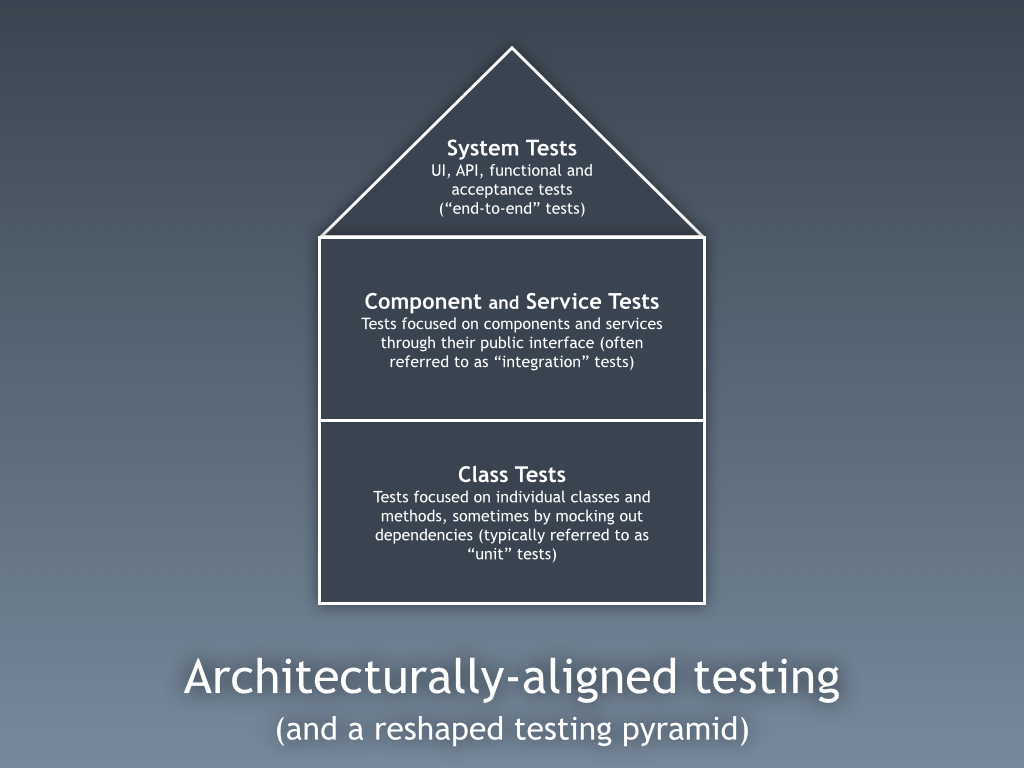
i'm trying to make a conscious effort to not use the term "unit testing" because everybody has a different view of how big a "unit" is. instead, i've adopted a strategy where some classes can and should be tested in isolation. this includes things like domain classes, utility classes, web controllers (with mocked components), etc. then there are some things that are easiest to test as components, through the public interface. if i have a component that stores data in a mysql database, i want to test everything from the public interface right back to the mysql database. these are typically called "integration tests", but again, this term means different things to different people. of course, treating the component as a black box is easier if i have control over everything it touches. if you have a component that is sending asynchronous messages or using an external, third-party service, you'll probably still need to consider adding dependency injection points (e.g. ports and adapters) to adequately test the component, but this is the exception not the rule. all of this still applies if you are building a microservices style of architecture. you'll probably have some low-level class tests, hopefully a bunch of service tests where you're testing your microservices though their public interface, and some system tests that run scenarios end-to-end. oh, and you can still write all of this in a test-first, tdd style if that's how you work.
i'm using this strategy for some systems that i'm building and it seems to work really well. i have a relatively simple, clean and (to be honest) boring codebase with understandable dependencies, minimal test-induced design damage and a manageable quantity of test code. this strategy also bridges the model-code gap , where the resulting code actually reflects the architectural intent. in other words, we often draw "components" on a whiteboard when having architecture discussions, but those components are hard to find in the resulting codebase. packaging code by layer is a major reason why this mismatch between the diagram and the code exists. those of you who are familiar with my c4 model will probably have noticed the use of the terms "class" and "component". this is no coincidence. architecture and testing are more related than perhaps we've admitted in the past.
Published at DZone with permission of Simon Brown. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments