Pagination in GraphQL: Efficiently Retrieve and Manipulate Data
Learn how to implement efficient pagination in your GraphQL schemas and resolvers, allowing for streamlined data retrieval and manipulation in your APIs.
Join the DZone community and get the full member experience.
Join For FreeIn our previous blog post titled "Pagination 101: why it matters and how to do it right in your API," we explored the importance of pagination and its implementation in APIs. Today, we delve into the realm of GraphQL and its powerful capabilities for efficient data retrieval and manipulation through pagination. We have become quite passionate about GraphQL lately as we now support designing and publishing GraphQL APIs in v2 of Martini and rendering content from a GraphQL API in an application, dashboard, or report created with Bellini.
Building upon the foundational knowledge from our previous blog, we will now focus on how pagination is handled, specifically in GraphQL APIs. GraphQL, with its flexible query language and runtime, provides developers with a versatile toolset to streamline pagination and optimize data fetching.
In the ever-evolving world of API development, pagination plays a crucial role in managing and retrieving large datasets. With GraphQL emerging as a popular query language and runtime, it brings forth a powerful solution for pagination challenges. In this article, we will explore how pagination is seamlessly handled in GraphQL APIs, leveraging its unique features and advanced techniques to efficiently retrieve and manipulate data.
Before diving into the specifics of GraphQL pagination, let's briefly grasp the concept of pagination in APIs. Pagination enables the retrieval of data in smaller, manageable chunks rather than fetching the entire dataset at once. It enhances performance, reduces network overhead, and provides a better user experience when dealing with vast amounts of information.
GraphQL, known for its declarative nature and flexible data-fetching capabilities, has gained popularity among developers. It serves as a modern alternative to traditional REST APIs, empowering clients to request precisely the data they need, eliminating over-fetching and under-fetching issues. This inherent flexibility makes GraphQL an ideal candidate for implementing efficient pagination strategies.
Using GraphQL for pagination brings several significant advantages over other approaches. Firstly, GraphQL allows clients to specify the exact shape and structure of the response, reducing unnecessary data transfers. Additionally, GraphQL's introspection capabilities enable clients to retrieve metadata about available pagination options, making it easier to navigate through large datasets. Lastly, GraphQL's strong typing system ensures a clear contract between the server and the client, facilitating seamless integration of pagination mechanisms.
Pagination Techniques in GraphQL
Embracing the Power of Relay’s Connection Model
Relay's Connection model stands out as a powerful technique for pagination in GraphQL. It introduces a standardized approach that ensures consistency and interoperability across different GraphQL implementations, revolutionizing the way we handle pagination. By understanding and implementing the Relay specification, you can unlock the benefits of this widely adopted pagination model.
The Relay specification defines a set of conventions and guidelines for implementing pagination, providing a well-defined structure that both clients and servers can adhere to. These conventions enable clients to navigate through paginated data seamlessly. By embracing the Relay specification, you establish a consistent and predictable pagination pattern.
At the core of Relay's Connection model are three key concepts: edges, nodes, and connections. Edges represent individual items within a paginated set. Each edge contains a reference to the corresponding node, which holds the actual data of the item. Connections establish the relationship between the edges, enabling efficient traversal and retrieval of paginated data.
Implementing Relay pagination in your GraphQL schemas and resolvers involves defining the necessary types, arguments, and return values in your GraphQL schema. By following the Relay conventions, you ensure that your pagination structure aligns with the expected format on the client side. This consistency simplifies the consumption of your GraphQL API and promotes better integration with Relay-aware tools and libraries.
In practice, resolving and fetching paginated data using Relay's Connection model requires adhering to the specified structure. By implementing pagination-aware resolvers and leveraging techniques such as cursor-based pagination or limit-offset pagination, you can efficiently retrieve the appropriate subset of data requested by clients. This approach not only enhances performance but also provides a consistent and intuitive experience for consumers of your GraphQL API.
B. Leveraging the Efficiency of Cursor-Based Pagination
Cursor-based pagination is a popular technique in GraphQL for efficient data traversal and retrieval. Unlike offset-based pagination, which relies on the notion of "limit" and "offset" values, cursor-based pagination employs opaque cursor values to navigate through the dataset. Let's dive into the key aspects of cursor-based pagination and explore how it can enhance your GraphQL APIs.
At its core, cursor-based pagination relies on the use of cursors to represent a specific position or marker within a dataset. These cursors are opaque strings that encode information about the position of an item in the collection. By utilizing cursors, you can accurately and efficiently navigate through paginated data without the need for additional computations or reliance on fixed numerical offsets.
The primary advantage of cursor-based pagination is its ability to maintain stable and reliable pagination results, even when the underlying data changes. Since cursors are tied to specific data points, they provide a consistent reference for traversing the dataset, irrespective of insertions, deletions, or modifications. This ensures a stable and predictable pagination experience for clients consuming your GraphQL API.
Implementing cursor-based pagination in GraphQL involves a few essential components. First, you need to define a cursor type in your GraphQL schema to represent the cursor values. This can be a scalar type such as a string or a custom cursor type tailored to your specific use case.
Next, you need to modify your GraphQL query or resolver to accept a cursor argument, representing the position from which to fetch the subsequent set of data. By utilizing the cursor information provided, you can efficiently retrieve the relevant subset of data for the client.
To showcase the implementation of cursor-based pagination, let's consider an example where we have a "users" collection. In the GraphQL schema, we define a "User" type with various fields. To implement cursor-based pagination, we would introduce a "users" query that accepts a "after" cursor argument. Using the cursor value, we can determine the starting point for fetching the next set of users. The response would include the paginated data along with a new cursor, representing the position for the subsequent page.
Here's an example of how the implementation might look in a GraphQL resolver:
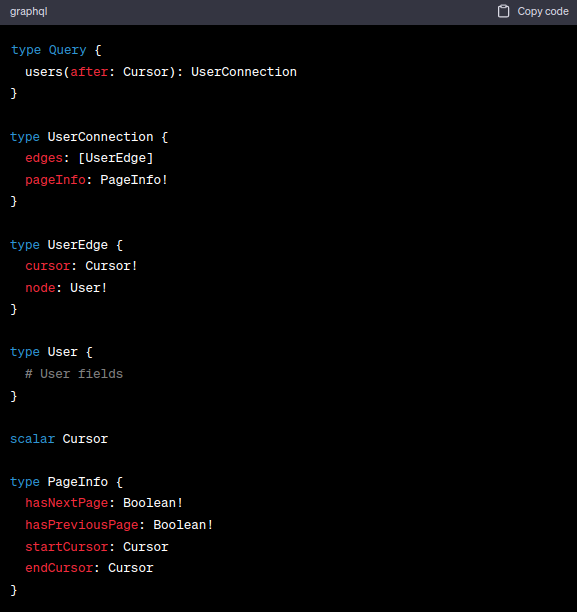
C. Harnessing the Flexibility of Offset-Based Pagination:
Offset-based pagination is a common approach in GraphQL for paginating data by utilizing "limit" and "offset" parameters. This technique involves specifying the number of items to retrieve per page (limit) and the starting position or index of the data subset (offset). Let's delve into the key aspects of offset-based pagination and explore its considerations and trade-offs in GraphQL APIs.
At its core, offset-based pagination relies on the use of numerical values to determine the subset of data to retrieve. The "limit" parameter defines the number of items to fetch in each page, while the "offset" parameter determines the starting position or index of the data subset. By manipulating these parameters, clients can navigate through the paginated data and retrieve the desired portions.
It's important to note that while offset-based pagination offers simplicity and straightforward implementation, it comes with certain considerations and trade-offs. One significant consideration is the impact of large offsets on performance and scalability. As the offset value increases, retrieving data from earlier positions becomes increasingly expensive, potentially resulting in slower response times and increased resource consumption.
Another consideration is the stability of the data subset when changes occur in the dataset. If new items are inserted or existing items are deleted within the dataset, the offsets associated with subsequent pages might become inconsistent or invalid. This can lead to inconsistencies in pagination results and may require additional handling or synchronization mechanisms to maintain the stability and integrity of pagination.
Additionally, offset-based pagination might not be suitable for scenarios where the dataset is highly dynamic or subject to frequent modifications. For example, if items are frequently added or removed from the dataset, the corresponding offsets may change, leading to unpredictable or unreliable pagination results.
Despite these considerations, offset-based pagination can still be an effective choice for certain use cases, especially when the dataset is relatively stable and the performance implications of large offsets are manageable. It provides a straightforward and intuitive pagination mechanism that is easy for clients to understand and implement.
D. Exploring Alternative Pagination Techniques:
In addition to Relay's Connection model, cursor-based pagination, and offset-based pagination, there are other pagination techniques available in GraphQL that offer alternative approaches and cater to specific use cases. Let's take a glimpse into these techniques, their advantages, and where they can be applied effectively.
One notable alternative is keyset pagination, which relies on using unique keys or identifiers to determine the subset of data to fetch. Instead of relying on numerical offsets, keyset pagination leverages the ordering and uniqueness of keys to navigate through the dataset. This approach is particularly useful when working with datasets that have natural ordering or when pagination needs to be performed based on specific criteria, such as alphabetical ordering or numerical ranges.
Time-based pagination is another technique that revolves around using time-related criteria to paginate data. It is commonly employed when dealing with time-series data or events. By utilizing timestamps or chronological information, time-based pagination allows clients to fetch data based on a specific time window or interval. This technique enables efficient retrieval of data within a particular timeframe and is often employed in applications such as social media feeds, event streams, or news articles.
Implementing Pagination in GraphQL Schemas
Crafting Well-Designed Schemas for Pagination:
When implementing pagination in GraphQL schemas, careful consideration of schema design is crucial. In this section, we will explore important factors to consider and address concerns related to data modeling and defining connections or edges in the schema. By adopting best practices in schema design, you can create efficient and intuitive pagination experiences in your GraphQL APIs.
Schema Design Considerations
Schema design plays a vital role in pagination implementation. It is essential to strike a balance between providing flexibility to clients and ensuring a consistent and predictable structure. Here are some key considerations:
- The granularity of types: Determine the appropriate level of granularity for your types. Avoid creating overly fine-grained types, as this can result in numerous small requests for each item. Conversely, excessively large types might lead to heavy payloads. Find the right balance based on your use case.
- Query complexity: Be mindful of the complexity of your pagination queries. Large or deeply nested queries can impact performance and response times. Consider breaking down complex queries into smaller, more focused ones to improve efficiency.
- Pagination limits: Determine suitable default and maximum limits for the number of items returned per page. This helps strike a balance between providing adequate data for clients and preventing excessive resource consumption.
Addressing Data Modeling Concerns
When implementing pagination, data modeling and defining connections or edges are crucial steps. Consider the following aspects:
- Identifying connections and edges: Identify logical connections within your data. Determine how items are related and define connections and edges accordingly. This helps establish the structure required for pagination.
- Cursor generation: When using cursor-based pagination, determine the appropriate strategy for generating unique cursors. Consider using properties that provide stability, such as timestamp-based values or unique identifiers, to ensure consistent sorting and reliable pagination results.
- Sorting and filtering: Decide on the supported sorting options for paginated data. Define arguments in your pagination queries to allow clients to specify sorting criteria. Additionally, consider incorporating filtering options to allow clients to retrieve specific subsets of data.
Establishing Pagination Arguments and Return Types:
To successfully implement pagination in GraphQL schemas, it is essential to define appropriate pagination arguments and return types. In this section, we will explore how to define pagination arguments, such as "first," "last," "after," and "before," and discuss the return types for paginated queries or connections.
Defining Pagination Arguments
Pagination arguments enable clients to specify the desired subset of data to retrieve. Here are common pagination arguments used in GraphQL:
- "first" and "last": These arguments determine the number of items to fetch from the beginning or end of the list, respectively. Clients can use these arguments to retrieve a specific number of items without needing to specify an exact offset.
- "after" and "before": These cursor-based arguments allow clients to request the items that appear after or before a given cursor value. Cursors provide a reliable way to navigate through paginated data without relying on numerical offsets.
When defining these arguments in your GraphQL schemas, ensure that they have appropriate types, such as positive integers for "first" and "last" or cursor values for "after" and "before." Additionally, consider including default values or specifying them as nullable to provide flexibility to clients.
Specifying Return Types
Return types in paginated queries or connections should accurately represent the paginated data and provide relevant metadata for navigation. Here are the key components of return types for pagination:
- "edges": The "edges" field represents the actual items in the paginated data set. Each edge contains the item's data and a cursor representing its position. The "edges" field is typically an array of objects with defined types.
- "nodes": The "nodes" field provides a convenient way to access the actual data items directly without the cursor information. It is often an array of the same type as the "edges" field.
- "pageInfo": The "pageInfo" field contains metadata about the pagination, such as whether there are more pages ("hasNextPage" or "hasPreviousPage") and the cursors indicating the start ("startCursor") and end ("endCursor") of the current page.
When defining the return types, ensure that they accurately reflect the structure described above. Consider creating custom types for "edges" and "pageInfo" to provide a clear and consistent structure for paginated responses.
Bringing Pagination to Life: Code Examples for Implementation
In this section, we will walk through step-by-step code examples to illustrate the implementation of pagination in GraphQL schemas. We will cover how to handle pagination arguments in resolvers and fetch the appropriate data. By following these examples, you will gain practical insights into effectively implementing pagination in your GraphQL APIs.
Implementing Pagination in GraphQL Schemas
To implement pagination in GraphQL schemas, you need to define the necessary types, fields, and arguments. Let's consider an example where we have a "User" type and want to paginate the list of users.
First, define the necessary types:
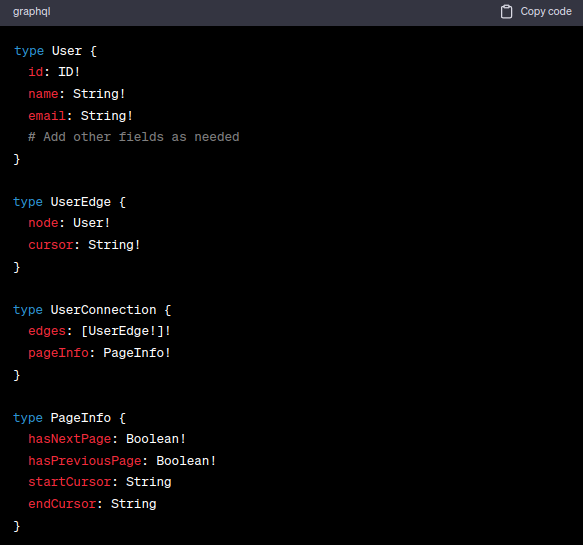
Next, add the pagination arguments to the relevant queries:

Handling Pagination Arguments in Resolvers
In your resolver functions, you need to handle the pagination arguments and fetch the appropriate data based on the requested subset. Here's an example resolver implementation for the "users" query:
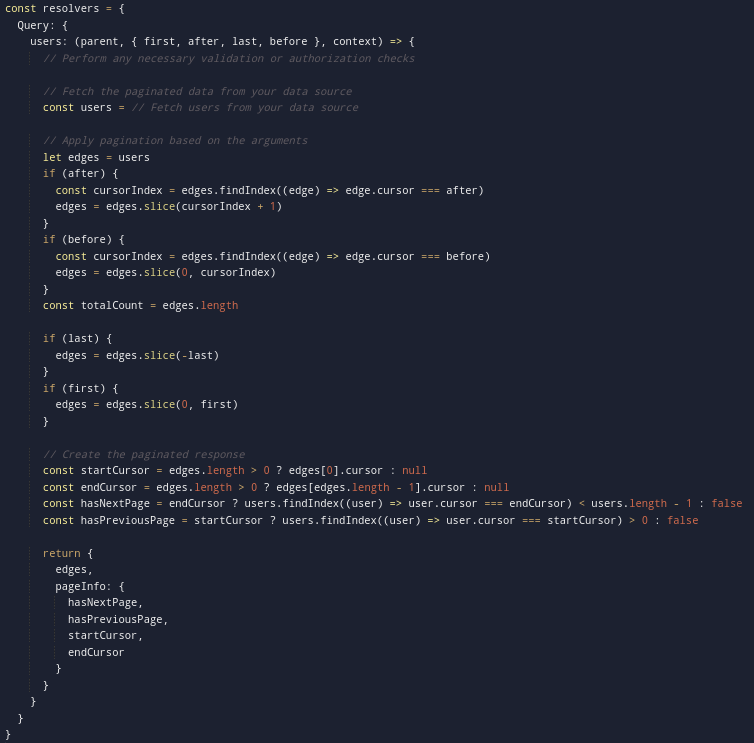
By implementing the above resolver logic, you can handle pagination arguments such as "first," "after," "last," and "before" to retrieve the appropriate subset of data from your data source. The resolver constructs the paginated response, including the "edges" array containing the actual data and the "pageInfo" object with metadata for navigation.
With these code examples, you now have a foundation for implementing pagination in your GraphQL schemas and effectively handling pagination arguments in your resolver functions. As you continue to build your GraphQL APIs, you can adapt and refine these examples to suit your specific data models and requirements.
Best Practices and Considerations for Pagination in GraphQL
Limiting Query Depth and Complexity
When implementing pagination in GraphQL, it's crucial to consider its impact on query depth and complexity. As the number of paginated items increases, the depth and complexity of the queries can grow substantially, potentially leading to performance issues. To address this, it's essential to follow best practices for limiting query complexity and optimizing performance.
Understanding the impact: Pagination introduces the possibility of retrieving a large amount of data in a single query, especially when combined with nested fields or additional filters. This can result in deeper and more complex queries, leading to increased response times and potential strain on your server. By acknowledging this impact, you can proactively mitigate performance issues.
Recommendations for query limitations: To ensure optimal performance, consider implementing the following recommendations:
- Limit the depth: Encourage clients to paginate responsibly by limiting the depth of their queries. This can be achieved by setting a reasonable maximum depth for nested fields and discouraging deeply nested paginated queries.
- Use field-level complexity analysis: Employ field-level complexity analysis to assign complexity values to your schema's fields. This approach helps enforce query complexity limits and encourages clients to make efficient use of pagination by selecting only the necessary fields.
- Implement pagination strategies: Explore pagination strategies, such as Relay's Connection model or cursor-based pagination, which inherently limit query depth and complexity. These strategies provide standardized approaches for pagination and simplify the process for clients while maintaining performance.
- Caching and data fetching optimization: Leverage caching mechanisms at both the server and client levels to minimize redundant data fetching. Caching responses for paginated queries can significantly improve performance by reducing the need for repeated data retrieval.
- Consider server-side implementations: Evaluate server-side optimizations, such as implementing data pagination at the database level or utilizing efficient indexing techniques. These optimizations can improve query performance by reducing the amount of data processed and retrieved from the underlying data source.
Caching and Performance Optimization
To further enhance the performance of paginated queries in GraphQL, caching strategies and optimization techniques play a crucial role. By implementing effective caching mechanisms and leveraging optimization techniques, you can minimize unnecessary data retrieval and improve overall response times.
Caching Strategies
Caching plays a vital role in reducing the load on your server and improving response times for paginated queries. Consider the following caching strategies:
- Result-level caching: Cache the results of paginated queries based on the specific combination of input arguments. This allows subsequent requests with the same arguments to be served from the cache, eliminating the need for redundant data retrieval.
- Cursor-based caching: Implement caching at the cursor level to store the paginated data along with the corresponding cursor values. This enables efficient caching and retrieval of subsets of data based on cursor-based pagination, reducing the workload on your server.
- Client-side caching: Encourage client-side caching by leveraging technologies like Apollo Client or Relay, which provide built-in caching capabilities. With client-side caching, repeated paginated queries can be served from the local cache, minimizing network requests and improving performance.
Performance Optimization Techniques
In addition to caching, consider the following techniques to optimize the performance of paginated queries:
- Cursor-based pagination: As mentioned earlier, cursor-based pagination offers not only efficient traversal of data but also caching benefits. By using cursors, you can retrieve data efficiently while maintaining the ability to cache and fetch subsequent pages seamlessly.
- Result batching: Implement result batching techniques to minimize the number of round trips between the client and server. By batching multiple paginated queries into a single request, you can reduce network overhead and improve overall query performance.
- Optimized database queries: Evaluate and optimize the database queries powering your paginated GraphQL APIs. Ensure that appropriate indexes are in place and consider performance-oriented techniques such as query optimization and data denormalization, depending on your specific data model and requirements.
Error Handling and Error Extensions
Error handling is a critical aspect of any GraphQL implementation, and paginated queries are no exception. When dealing with pagination in GraphQL, it is important to consider error-handling strategies and provide meaningful error information to clients. Additionally, leveraging error extensions can enhance the error reporting process by providing detailed insights into pagination-related errors.
Error Handling Considerations
When implementing pagination in GraphQL, it's essential to address the following error handling considerations:
- Invalid pagination arguments: Handle cases where clients provide invalid pagination arguments, such as negative values or invalid cursors. Respond with appropriate error messages that guide clients to correct their requests.
- Resource limitations: Account for scenarios where pagination exceeds resource limitations, such as reaching the end of a dataset or requesting a page beyond the available data. Inform clients about these limitations and provide relevant information to help them adjust their queries accordingly.
- Server errors: Handle server errors that may occur during the pagination process, such as issues with the underlying data source or network connectivity problems. Return meaningful error messages that indicate the nature of the error and guide clients on appropriate actions.
- Error extensions for detailed error reporting: To enhance the error reporting process in pagination-related errors, consider utilizing error extensions. Error extensions provide additional context and details about the encountered error, enabling clients to understand the issue better. For pagination, error extensions can include information such as:
- Invalid cursor values: If an error occurs due to an invalid cursor value provided by the client, include the problematic cursor in the error extension. This helps clients identify the specific cursor causing the issue and make necessary adjustments.
- Pagination metadata: Include relevant pagination metadata in the error extensions, such as the total number of available items, the current page, or the page size. This information assists clients in understanding the pagination context and adjusting their queries accordingly.
- Guidance for recovery: Provide guidance or recommendations within the error extensions to help clients recover from errors. This could include suggestions for alternative pagination strategies, adjusting pagination arguments, or retrying the request with different parameters.
Conclusion
Throughout this article, it became evident that GraphQL offers significant benefits for pagination. Its flexible and declarative nature allows clients to request precisely the data they need, minimizing unnecessary data retrieval. Additionally, GraphQL's ability to retrieve connections and implement pagination on demand provides a seamless and efficient experience for developers and users alike.
We encourage you to explore and implement pagination techniques in your GraphQL APIs. Experiment with Relay's Connection model or cursor-based pagination, and consider the specific requirements and constraints of your project. By leveraging the power of pagination in GraphQL, you can enhance the scalability, performance, and user experience of your APIs.
To further expand your knowledge on pagination and GraphQL, we recommend exploring additional resources and documentation provided by the GraphQL community and frameworks. Stay up to date with the latest advancements in GraphQL pagination techniques, and continue to refine and optimize your pagination implementation based on evolving best practices.
Incorporating pagination effectively in your GraphQL APIs opens up new possibilities for managing and retrieving data in a controlled and efficient manner. Embrace the power of GraphQL's pagination capabilities and unlock the full potential of your APIs.
Happy paginating!
Opinions expressed by DZone contributors are their own.
Comments