Parse Data With Ab Initio Batch Graph and Write to Database
This article shows how to parse data with Ab Initio Batch Graph and write to a database.
Join the DZone community and get the full member experience.
Join For Free
Within the scope of this article, the Batch Ab Initio graph will be triggered via the scheduler and the files in the destination folder will be retrieved and the data in it will be parsed according to certain criteria.
The parsed data will be written to the database.
He talked about the architecture and coding of archiving of files, providing file control, retrieving the file, filing the content of the file according to the required criteria, writing and processing the filtered data to the database.
First of all, we should have a scheduler structure that will trigger the Ab Initio graph. The choice here is entirely up to you. An oracle scheduler can be used as an example.
With the job to be triggered via the scheduler, it is possible to run the Ab Initio graph.
You might also like: Understanding Batch, Microbatch, and Stream Processing
Folder Created
We must create our Folder structure in a directory that can be accessed from Ab Initio.
For input files --> SAMPLE\INPUT_FILE
For archive:
Output files --> SAMPLE\OUTPUT_FILE

After the directories are created, we assign our 'sample_xxxx.txt' file into the SAMPLE \ INPUT_FILE folder.
For example, let's have a single column in our file and let the column name Msisdn. Column data can be '+ 90530XXXXXX'.
Sampling was done to make the structure understandable. You can design as you want.

Ab Initio
New Ab Initio Graph is Created
On the Ab Initio Tool;
* Create a new graph
* Go to (‘File>New’)
* Then ‘File>Save As’ (i.e., Graph1) to save it in the appropriate ‘sandbox’ to enable this new graph to pick up the proper environment.
The newly created graph is opened. By clicking the organizer button on the main page, the following components are added.

Run Program Component
The Run program component is added to the graph.
With this component, we can read our files from the destination folder that we set ourselves.
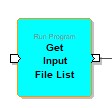
Run Program --> Description --> Get Input File List
Run Program --> Parameters --> value --> SAMPLE\INPUT_FILE directory is shown.
source --> embed selected.
Run Program --> Ports --> Output --> out --> record format
record
string("\n") filename;
end
Replicate Component

The first stream is used to parse the data in the file.
The 2nd stream is created with a replicate component to archive files while processing. (It will be better understood in the full graphical display later.) This stream is set to run after the files have been processed. In the second stream, the sh file is created to archive the files by taking the distinct file names in the flow.
ReFormat and Output File components are used to create the “Sh File”. This file is then created in a different phase (example: phase 3) It is run. The Run Commands component was used to run the “Sh File”.
Replicate --> Ports --> Output --> out --> record format
record
string("\n") filename;
endRead Multiple Files Component
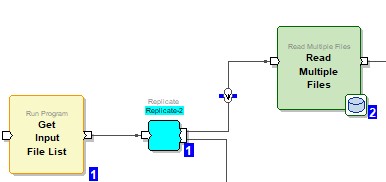
The Read Multiple Files component is added to transform the file contents.
type input_type = record
string("\n") msisdn;
end;
/*extract filename from input record*/
filename::get_filename(in) =
begin
filename :: in.filename;
end;
/* This function is optional. */
/*Create output record*/
out::reformat(read,filename,in)=
begin
let string(int) l_filename = string_substring(filename,string_rindex(filename,"/") + 1, 255);
let string('') [] l_filename_parts = string_split(l_filename,'_');
out.* :: read.*;
out.msisdn :: string_suffix(decimal_strip(read.msisdn),10);
out.filename_base :: l_filename;
out.file_external_id :: l_filename_parts[1];
out.record_no :: 1;
end;Read Multiple Files --> Parameters --> compressed --> False
Read Multiple Files --> Data --> Associate component with EME dataset : $AI_SERIAL/dummy.dat
Read Multiple Files --> Layout --> Url : $AI_SERIAL
Read Multiple Files --> Ports --> Output --> filereject -->
record
string("\n") filename;
endRead Multiple Files --> Ports --> Output --> fileerror --> string('\n')
Read Multiple Files --> Ports --> Output --> ou --> record format -->
record
string("¨", ) msisdn;
string("¨", ) filename_base;
decimal("¨", ) file_external_id;
decimal("¨", ) record_no;
string(1) newline = "\n";
endSort Component
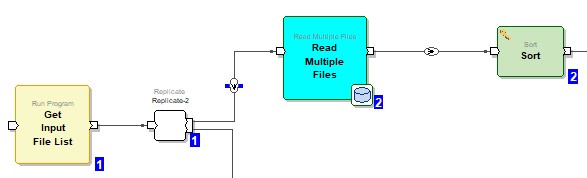
The sort component is added to sort the data. The filename_base and msisdn fields are sorted ascending.
Sort --> Parameters --> Key --> value --> {filename_base; msisdn} --> Ascending sorting added.
Sort --> Parameters --> Max_core --> value --> 1 ( max_core value is written)
Sort --> Ports --> Output --> out --> record format -->
record
string("¨", ) msisdn;
string("¨", ) filename_base;
decimal("¨", ) file_external_id;
decimal("¨", ) record_no;
string(1) newline = "\n";
endSort --> Ports --> Output --> out --> Record Format Source --> Propagate from neighbors is marked.
Dedup Sorted Component
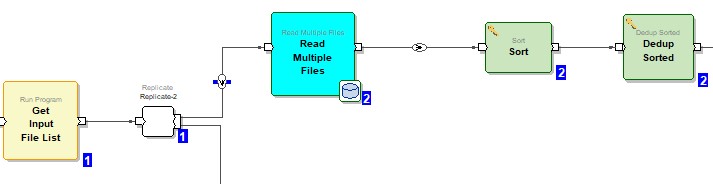
Dedup Sorted Component is added to eliminate duplicate records.
Dedup Sorted --> Parameters --> Key --> Value --> {filename_base; msisdn} --> Ascending sorted.
Dedup Sorted --> Parameters --> Keep --> first
Dedup Sorted --> Parameters --> Reject-threshold --> Abort on first reject
Dedup Sorted --> Parameters --> Check-sort --> False (Not checked. no need for sort component used before)
Dedup Sorted --> Parameters --> Logging --> False
Dedup Sorted --> Ports --> Output --> out --> Record Format Source --> Propagate from neighbors is marked.
Dedup Sorted --> Ports --> Output --> out --> Record format -->
record
string("¨", ) msisdn;
string("¨", ) filename_base;
decimal("¨", ) file_external_id;
decimal("¨", ) record_no;
string(1) newline = "\n";
endReformat Component
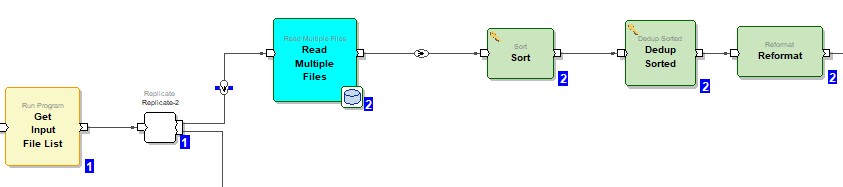
The reformat component is added to find out the record sequence number based on filename.
Reformat --> Parameters --> Transform --> value
let string(int) g_filename = '';
let integer(8) ;
/* This function is optional. */
/*Create output record*/
out::reformat(in)=
begin
/* initialize count filename changes*/
if (g_filename != in.filename_base)
begin
g_filename = in.filename_base;
g_count = 1;
end;
else
begin
g_count = g_count + 1;
end;
out.* :: in.*;
out.record_no :: g_count;
end;Reformat --> Ports --> Output --> out --> Record format -->
record
string("¨", ) msisdn;
string("¨", ) filename_base;
decimal("¨", ) file_external_id;
decimal("¨", ) record_no;
string(1) newline = "\n";
end;Reformat --> Ports --> Output --> out --> Record Format Source --> Propagate from neighbors is marked.
Join With DB Component

Insert with DB Component is added to insert the data into the Database.
NOTE: Particularly, the use of 'join with db component' is due to the fact that the insert operations in the database are performed on more than one table and the need to execute a database procedure due to the execution of some controls.
For example, for each file, an insert to the master table and each record in the file is inserted into the detail table.
If insert operation is to be performed for a single table, the use of out table component should be preferred because it will be more efficient.
Join with DB --> Parameters --> DBConfigFile --> Configuration File --> configration the definition is added.
For example: $AI_DB/oracle_XXX.dbc
--> DBMS type --> for example: ORACLE
Join with DB --> Parameters --> dbms --> value --> for example : ORACLE
Join with DB --> Parameters --> select_sql --> execute schema.p_insert( :p_filename, :p_msisdn, :p_file_external_id, :p_location_type_id, :p_recordno );
Join with DB --> Parameters --> transform -->
type query_result_type=
record
end;
/*Generated type from select statement*/
// Compute fields for where clause
type key_type =
record
string(int) p_filename;
string(int) p_msisdn;
integer(8) p_file_external_id;
integer(8) p_recordno;
end;
/*Optional calculation of data for query where clause*/
out::compute_key(in) =
begin
out.p_filename :: in.filename_base;
out.p_msisdn :: in.msisdn;
out.p_file_external_id :: in.file_external_id;
out.p_recordno :: in.record_no;
end;
/*Database lookup transform*/
out::join_with_db(in, query_result) =
begin
out.* :: in.*;
end;Join with DB --> Parameters --> Continuous --> false
Join with DB --> Parameters --> match_Required --> true
Join with DB --> Parameters --> cache_query_results --> false
Database
Database Writing
CREATE TABLE T_MASTER
(
MASTER_ID NUMBER,
FILE_EXTERNAL_ID NUMBER,
LOCATION_TYPE_ID NUMBER DEFAULT 1,
FILE_NAME VARCHAR2(255 BYTE),
FILE_COUNT NUMBER,
STATUS NUMBER DEFAULT 0,
INSERT_DATE DATE,
ERROR_DESC VARCHAR2(4000 BYTE)
);
CREATE UNIQUE INDEX MASTER_ID_PK ON T_MASTER(MASTER_ID);
ALTER TABLE T_MASTER ADD (
CONSTRAINT MASTER_ID_PK
PRIMARY KEY
(MASTER_ID)
USING INDEX MASTER_ID_PK
ENABLE VALIDATE);
CREATE SEQUENCE SEQ_MASTER
START WITH 1
MAXVALUE 999999999999
MINVALUE 0
NOCYCLE
NOCACHE
NOORDER;
CREATE SEQUENCE SEQ_FILE_DETAIL
START WITH 1
MAXVALUE 999999999999
MINVALUE 0
NOCYCLE
NOCACHE
NOORDER;
CREATE SEQUENCE SEQ_ERR_REC
START WITH 1
MAXVALUE 999999999999
MINVALUE 0
NOCYCLE
NOCACHE
NOORDER;
CREATE TABLE T_FILE_DETAIL
(
FILE_DETAIL_ID NUMBER,
MSISDN VARCHAR2(20 BYTE),
MASTER_ID NUMBER,
INSERT_DATE DATE,
ERROR_DESC VARCHAR2(4000 BYTE),
STATUS NUMBER DEFAULT 0
);
CREATE TABLE T_ERROR_RECORDS
(
ERROR_REC_ID NUMBER,
MSISDN VARCHAR2(20 BYTE),
MASTER_ID NUMBER,
INSERT_DATE DATE
);
CREATE UNIQUE INDEX ERROR_REC_ID_PK ON T_ERROR_RECORDS
(ERROR_REC_ID);
ALTER TABLE T_ERROR_RECORDS ADD (
CONSTRAINT ERROR_REC_ID_PK
PRIMARY KEY
(ERROR_REC_ID)
USING INDEX ERROR_REC_ID_PK
ENABLE VALIDATE);
ALTER TABLE T_ERROR_RECORDS ADD (
CONSTRAINT ERR_MASTER_ID_FK
FOREIGN KEY (MASTER_ID)
REFERENCES T_MASTER (MASTER_ID)
DISABLE NOVALIDATE);
CREATE OR REPLACE PROCEDURE P_INSERT (
p_filename IN VARCHAR2,
p_msisdn IN VARCHAR2,
p_file_external_id IN NUMBER,
p_location_type_id IN NUMBER,
p_recordno IN NUMBER
) AS
l_file_detail_id NUMBER;
l_master_id NUMBER;
l_error_rec_id NUMBER;
BEGIN
IF p_recordno = 1 THEN
l_master_id := seq_master.NEXTVAL;
INSERT INTO t_master
(master_id, file_external_id, location_type_id, file_name,
file_count,status,insert_date
)
VALUES (l_master_id, p_file_external_id, p_location_type_id, p_filename,
1,0, --initial statu
SYSDATE
);
ELSE
SELECT master_id
INTO l_master_id
FROM t_master
WHERE file_name = p_filename;
UPDATE t_master
SET file_count = file_count + 1
WHERE master_id = l_master_id;
END IF;
l_file_detail_id := seq_file_detail.NEXTVAL;
BEGIN
IF p_msisdn IS NULL THEN
l_error_rec_id := seq_err_rec.NEXTVAL;
INSERT INTO t_error_records
(error_rec_id, msisdn, master_id, insert_date
)
VALUES (l_error_rec_id, p_msisdn,l_master_id,SYSDATE);
UPDATE t_master
SET file_count = file_count - 1
WHERE master_id = l_master_id;
ELSIF LENGTH(TO_CHAR(p_msisdn)) != 10 then
l_error_rec_id := seq_err_rec.NEXTVAL;
INSERT INTO t_error_records
(error_rec_id, msisdn, master_id, insert_date
)
VALUES (l_error_rec_id, p_msisdn,l_master_id,SYSDATE);
UPDATE t_master
SET file_count = file_count - 1
WHERE master_id = l_master_id;
ELSE
INSERT INTO t_file_detail
(file_detail_id, msisdn,master_id,
insert_date,status
)
VALUES (l_file_detail_id, p_msisdn,l_master_id,
SYSDATE,0 --initial statu
);
END IF;
END;
END p_insert;Ab Initio Continued
For Archive Files
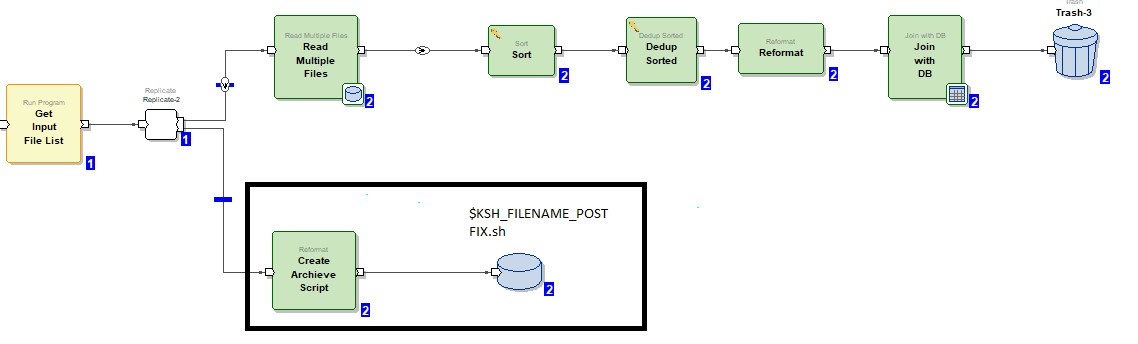
These two components are used to archive files after data is processed into the database.
Reformat Component
Reformat --> Ports --> Output --> out --> Record Format Source --> embed is marked.
Reformat --> Parameters --> Transform --> value
out::reformat(in)=
begin
let string("") l_start="";
let integer(4) l_nis=next_in_squence();
l_start = "#!/bin/ksh \n";
out.cmd:1:if(l_nis==1)string_concat(l_start,"mv","in.filename"";
"$KSH_FILENAME_POSTFIX.sh");
out.cmd::string_concat("mv",in.filename,"","$KSH_FILENAME_POSTFIX.sh");
end;Reformat --> Ports --> Output --> out --> Record format -->
record
string("¨", ) msisdn;
string("¨", ) filename_base;
decimal("¨", ) file_external_id;
decimal("¨", ) record_no;
string(1) newline = "\n";
end;Reformat --> Ports --> Output --> out --> Record Format Source à embed is marked.
Output File Component
OutputFile --> Data --> URL is marked. ( The path to the ksh file that will run should be given here )
OutputFile --> Access -->

OutputFile --> Ports --> Input --> write --> Record Format -->
record
string("\n") cmd;
end;OutputFile --> Ports --> Record Format Source --> Propagate from neighbors is marked.
Opinions expressed by DZone contributors are their own.
Comments