Mule Batch Processing - Part 1: Introduction
Learn about Mule's batch message processing capability, how it works, and its applications in this introductory article.
Join the DZone community and get the full member experience.
Join For FreeMule Enterprise Edition has the capability to process messages in batches. This is useful for processing a large number of records or stream of data. It has many components that are very specific to batch processing and can be used to implement business logic. In this blog series, we will talk about batch processing in Mule and unit testing it with MUnit.
In this first part of the series, I will introduce you to Mule batch processing and different terminologies related to it. At the end, we will also see a simple Mule batch job.
Table of Contents:
1 Introduction to Batch
Batch processing in Mule is divided into four phases - Input, Load and Dispatch, Process, and On Complete.
1.1 Mule Batch Phases
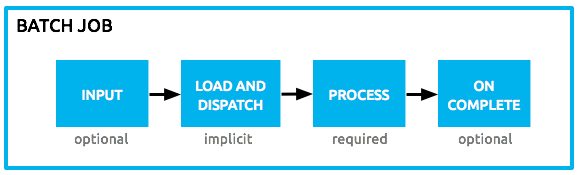
Figure 1.A: Mule Batch Phases [Source: Mule Docs].
Input Phase: This is an optional part of the batch job that can be used to retrieve the source data using any inbound connector. It also allows chaining of multiple message processors to transform the source data before it is ready for processing.
Load and Dispatch: This is an implicit phase and Mule runtime takes care of it. In this phase, the payload generated in the Input phase or provided to the batch from the caller flow is turned into a collection of records. It also creates a job instance for processing records. The collection is then sent through the collection-splitter to queue individual records for processing.
Process: This is the required phase where the actual processing of every record occurs asynchronously.
- Each record from the input queue is processed through the first step and sent back to the queue after processing of the first step completes.
- Records that are processed in the first step are then passed through the second step and sent back to the queue after processing of the second step completes.
- Mule continues this until all records are passed through each step.
At the step level, you can also specify what type of records each step should accept. This can be configured using accept-expression in the step definition. Records satisfying the accept-expression condition of a step will be processed by that step, or otherwise moved to the next eligible step. You can also define accept-policy to filter out messages based on their processing status.
Processing of records through the next step DOES NOT wait for the previous step to finish processing all records. Mule manages the state of each record while it moves back and forth between the queue and steps.
On Complete: In this final but optional phase, a summary of batch execution is made available to possibly generate reports or any other statistics. The payload in this phase is available as an instance of a BatchJobResult object. It holds information such as the number of records loaded, processed, failed, succeeded. It can also provide details of exceptions that occurred in steps, if any.
1.2 What Are Record Variables?
In general, Mule provides Flow Variables, Session Variables, and Outbound Properties to store information at different scope levels. When records are being processed through the steps, each record becomes the message payload for step.
If you want to store any information at the individual record level, then existing scopes does not work. That is where a record variable is needed. It is scoped to the process phase only and every record gets its own copy of record variables that are serialized and carried with the record through all the steps.
Record variables can be set using the <batch:set-record-variable /> element, similar to <set-variable />.Record variables can only exist and be used during the Batch Process phase when a record is being processed.
1.3 Initializing a Batch Job
Mule batch processing can be initiated in two ways:
A. Triggering via Input Phase: One-way message sources can be polled in the input phase to retrieve data for processing.
Listing 1.3.B: Triggering a Batch Job
<batch:input>
<poll>
<db:select config-ref="MySQL_Configuration" doc:name="Database">
<db:parameterized-query><![CDATA[select * from employees where status = 'REHIRE']]></db:parameterized-query>
</db:select>
</poll>
</batch:input>B. Invoking a Batch Job: Just like invoking a flow/sub-flow using the flow-ref component, it is possible to invoke a batch in the existing flow using the <batch:execute /> component.
Listing 1.3.B: Invoking a Batch job
<flow name="mule-configFlow">
<poll doc:name="Poll">
<fixed-frequency-scheduler frequency="1" timeUnit="HOURS"/>
<db:select config-ref="MySQL_Configuration" doc:name="Database">
<db:parameterized-query><![CDATA[select * from employees where status = 'REHIRE']]></db:parameterized-query>
</db:select>
</poll>
<batch:execute name="simple_batch_job" doc:name="simple_batch_job"/>
</flow>2. Simple Batch Job Application
We now have enough basic information about Mule batch job. Let’s look at a simple batch job (we will use this in our testing demo).
We expect to invoke this batch from another flow that generates the source data and feeds it to the batch. Our batch expects a list of coffee orders with some status. General business logic will be:
- If the status is 'MessedUp,' then the input phase will not load those records.
- Records with a status of 'Ready' will be marked as 'Processed.'
- Records with a status of 'Not-Ready' will be marked as 'Failed.'
Also, our steps have accept-expression defined to demonstrate record filtering.
Listing 2.A: Simple Batch Job
<batch:job name="mule-simple-batch">
<batch:input>
<dw:transform-message doc:name="Transform Message">
<dw:set-payload><![CDATA[%dw 1.0
%output application/java
---
payload filter $.status != 'MessedUp']]></dw:set-payload>
</dw:transform-message>
</batch:input>
<!-- Implicit Load and Dispatch phase -->
<batch:process-records>
<batch:step name="Batch_Step_1">
<flow-ref name="batch-step-1-process" doc:name="Flow batch-step-1-process"/>
</batch:step>
<batch:step name="Batch_Step_2" accept-expression="#[payload.status == 'Processing']">
<flow-ref name="batch-step-2-process" doc:name="Flow batch-step-2-process"/>
</batch:step>
<batch:step name="Batch_Step_3" accept-expression="#[payload.status == 'Not-Processing']">
<flow-ref name="batch-step-3-process" doc:name="Flow batch-step-3-process"/>
</batch:step>
</batch:process-records>
<batch:on-complete>
<logger message="#['Batch Processing Result: Loaded:'+ payload.loadedRecords + ', successful: '+ payload.successfulRecords + ', failed: '+ payload.failedRecords]" level="INFO" doc:name="EndLogger"/>
</batch:on-complete>
</batch:job>Batch Input phase: Filters out the MessedUp records. |
| Implicit Load and Dispatch phase will run at this point. |
| Processing Phase: Process records through steps to mark as Processed or Failed. |
| On Complete phase: Log the processing statistics. |
Each of our batch step calls a sub-flow that implements logic to update the status and process record.
Listing 2.B: Batch Step 1 Sub-flow
<sub-flow name="batch-step-1-process">
<logger message="#['Processing Step 1 for Id:' + payload.id + ' with status: ' + payload.status.trim()]" level="INFO" doc:name="Logger"/>
<batch:set-record-variable variableName="id" value="#[payload.id]" doc:name="Record Variable"/>
<dw:transform-message doc:name="Transform Message">
<dw:set-payload><![CDATA[%dw 1.0
%output application/java
---
(payload ++ (status: 'Processing' when payload.status == 'Ready' otherwise 'Not-Processing'))]]></dw:set-payload>
</dw:transform-message>
</sub-flow>Listing 2.C: Batch Step 2 Sub-flow
<sub-flow name="batch-step-2-process">
<logger message="#['Processing Step 2 for Id:' + recordVars.id + ' with status: ' + payload.status]" level="INFO" doc:name="Logger"/>
<dw:transform-message doc:name="Transform Message">
<dw:set-payload><![CDATA[%dw 1.0
%output application/java
---
(payload ++ (status: 'Processed'))]]></dw:set-payload>
</dw:transform-message>
</sub-flow>Listing 2.D: Batch Step 3 Sub-flow
<sub-flow name="batch-step-3-process">
<logger message="#['Processing Step 3 for Id:' + recordVars.id + ' with status: ' + payload.status]" level="INFO" doc:name="Logger"/>
<dw:transform-message doc:name="Transform Message">
<dw:set-payload><![CDATA[%dw 1.0
%output application/java
---
(payload ++ (status: 'Failed'))]]></dw:set-payload>
</dw:transform-message>
</sub-flow>
</mule>This is a very simple batch application that does not call any other systems, but it does not mean you can not do that. You can replace the logic in the sub-flow with any implementation. The only message processors that you CANNOT use in batch steps are request-response inbound connectors.
3. Conclusion
In this part, we learned what a Mule batch job is and different phases in batch processing. We also saw how to manage record level variables and then trigger the batch processing. At the end, we saw a simple batch application that processes coffee orders.
4. Next: Part 2
In the next part, we will enable MUnit on our batch and learn how we can unit test Input and On Complete phase.
5. References
Mule Documentation for Batch Processing.
For quick reference, here are links to all parts in this series:
Part 1: Mule Batch Processing - Introduction
Part 2: Mule Batch Processing - MUnit Testing
Part 3: Mule Batch Processing - MUnit Testing (The Conclusion)
Published at DZone with permission of Manik Magar. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments