Performance Benchmark of Explicit Locks (Part 1)
Learn more about the performance benchmark of explicit locks.
Join the DZone community and get the full member experience.
Join For FreeIn one of my recent articles, I was introducing a "safe accessor service" that worked on shared resources by applying Java's ReentrantReadWriteLock. At the end of the article, I was discussing performance of a ReadWriteLock as opposed to conventional explicit Lock like ReentrantLock. The issue was that I found myself making only vague statements. This actually raised my interest to find a benchmark that shows scenarios when ReentrantReadWriteLock can outperform ReentrantLock.
In this article, I want to share my first results on a benchmark that applied a "predominant read workload" on shared resources guarded by the two different Lock implementations. This workload is made up of 80 percent reads and 20 percent writes. These reads and writes are performed randomly. The benchmark uses the jmh framework and is publicly available on my GitHub account. You can download the repository and run it on your machine. Brief instructions how to execute the benchmark are documented in the README.md.
The test harness accepts three configuration parameters:
The time delay between lock acquisitions, which results in specific "lock interval" or "lock frequency";
The time a resource lock is held by a thread, which results in a specific "lock duration" or "task size" respectively;
The workload mix, which results in a specific read/write ratio, here 80% read and 20% write operations.
Application performance can be measured in different ways, and this article won't go into the alternatives. The benchmark measures throughput in operations (ops) per second (s).
Now, let's dive into results to make this more interesting (measured with Java 8 on a 2,7 GHz Intel i7 quad core system).
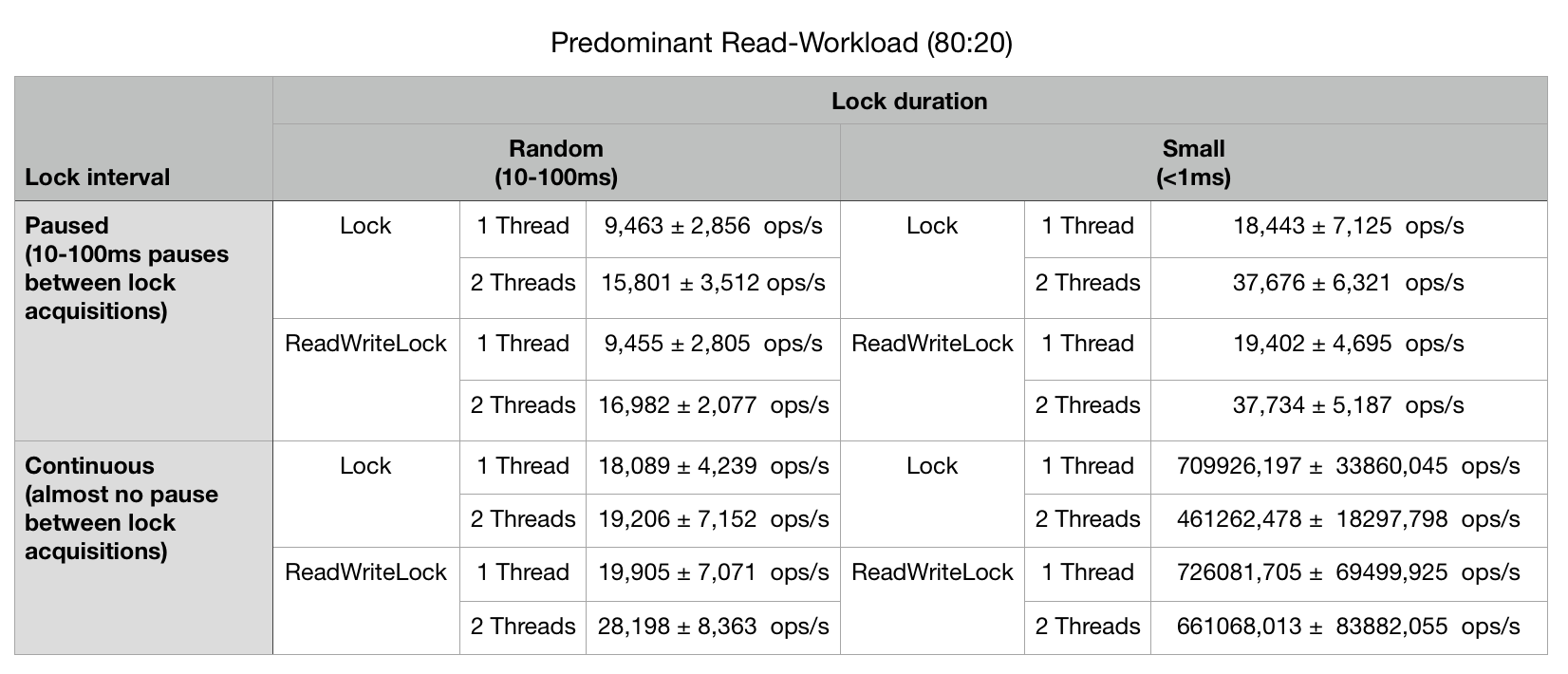
The table shows a predominant read-workload mix, where there are 80 percent read and 20 percent write operations on a shared resource. Furthermore, the lock duration (task size) is either random between 10-100 ms or very small < 1 ms. The lock intervals (pauses) are either random 10-100 ms or there is (almost) no pause between lock acquisitions at all.
Medium Load Scenarios
On the upper half of the table, all benchmarks used a locking interval with pauses between lock acquisitions. Pauses simulate that the thread performs some other tasks outside the shared resource. The pauses vary randomly in size between 10-100ms. The whole benchmark is intended to simulate a medium workload scenario. The benchmark results on medium workload show that:
1. a second thread increased throughput considerably
2. there was no difference in throughput with regards to the explicit lock types used
With equivalent number of threads, ReeantrantLock and ReeantrantReadWriteLock achieved the same throughput on medium utilized predominant read workload mix. This observation was independent of the applied lock duration (task size). It's important to notice that the average task size was equal or smaller then the applied pauses between lock acquisitions.
High Load Scenarios
Let's look at the bottom half of the table. Here, there is no pause applied between lock acquisitions, which simulates a very high load scenario. Multiple threads perform tasks on shared resources aggressively, constantly competing for associated locks. Important results in the bottom left half with random size tasks between 10-100 ms are:
1. ReentrantLock could not increase throughput significantly by adding an extra thread;
2. ReentrantReadWriteLock could increase throughput significantly (~19 up to ~28 ops/s) by adding an extra thread.
The following interesting results on the bottom right half with very small tasks (<1 ms) are:
1. The addition of a second thread results in a decrease of overall throughput compared to single thread execution;
2. With two threads, ReentrantReadWriteLock does perform better as ReentrantLock, though throughput also decreases as opposed to single thread execution.
Adding threads to a high load setup with high lock frequency and small tasks (bottom right of the table) decreased overall throughput, supposably due to the lock contention overhead. In general, the high load scenario (bottom half of the table) was the domain whereReentrantReadWriteLock could achieve better throughput results then ReentrantLock, especially when the task size varied randomly between 10-100ms ReentrantReadWriteLock (bottom left of the table). ReentrantReadWriteLock could also weaken the negative impact of lock overhead. All in all: in the predominant read workload applied in the benchmark ReeantranReadWriteLock achieved equivalent or even better results than ReentrantLock.
OK, in my subsequent posts, I will present the results of predominant write workload, read only workloads, and others. You can use these results as a reference in decision making in the development process. It is not meant as a replacament of individual performance measuring on your concrete application.
Hope you enjoyed reading the post!
Opinions expressed by DZone contributors are their own.
Comments