Persistent and Transient Queues in Mule
To prove the persistence of Mule’s queues on-premise, I created a project with two different configurations for VM already set and each of with a different queue name.
Join the DZone community and get the full member experience.
Join For FreeHi, I'm a nearshore MuleSoft Developer and this article is an analysis of the persistent and transient queues in Mulesoft.
At the moment of publishing the article, I’m using:
Anypoint Studio: 7.3.3
Mule Runtime: 4.1.5
There are two types of queues in Mule: TRANSIENT and PERSISTENT.
On-premise Behavior
Realized tests using both types of queues.
Transient queue proved to be faster than persistent because data is stored in memory. Because of this, if the application or server is turned off or is down due to a failure, a message placed in the queue will be lost.
Meanwhile, the persistent queue had to write to the disk to persist the data in it, becoming slower. However, there is an advantage to it, since the message is serialized onto the disk even if the server has a downtime the data will be recoverable once the Mule server is up and running again. The recovered message in the VM queue will be picked up automatically as inbound data in the listener.
For each persistent queue defined, Mule created 3 files:
- <queueName>-1
- <queueName>-2
- <queueName>-crl
“When running on a single instance, persistent queues work by serializing and storing the contents onto the disk.”
Working in Clusters
If an app using VMs is deployed in a cluster, Mule runtime will decide in which node of the cluster the info will be saved.
Scenario
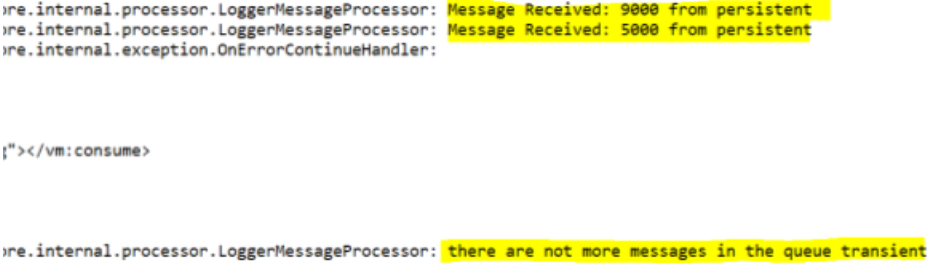
To prove the persistence of Mule’s queues on-premise, I created a project with the two different configurations for VM already set and each of them with a different queue name, this way I only had to pass over a query parameter to decide in which queue to write, based on the value sent. I used an HTTP listener to post messages in any of the queues.
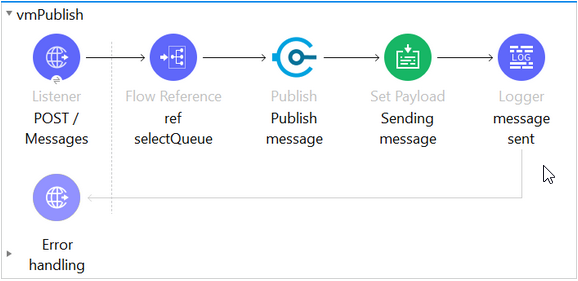
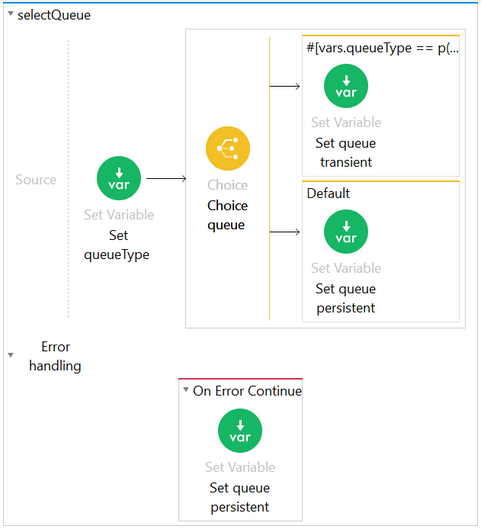
For reading messages, I used a GET request to trigger a consume operation, this way I could control when to read messages from the VM queue. So, I could place messages into both queues, then stopping the application and when starting again, validate which messages were lost or remained.

In this example, I’m testing two messages in the persistent queue and two more in the transient.


CloudHub Behavior With Only One Instance (1 Worker)
Mule Runtime: 4.1.5
Environment: Sandbox
One Worker
In order to use persistent queues in CloudHub, when your application has been deployed, it is necessary to tick the 'Persistent Queue' checkbox in the application settings in Runtime Manager.
Note: With a trial account this is not possible because the check box of Persistent Queues is disabled, it is necessary for an Enterprise Account to select persistent queues.
This 'Persistent Queue' option overrides any configuration done in the Mule configuration files. If enabled, all queues become persistent. If not selected, all queues are set as transient, even if they were configured as persistent in Mule configuration files.
Conclusions
Local |
Transient Queue |
Persistent Queue |
It is faster. |
It is slower. |
|
Not trustworthy in case of a system crash. |
Reliable. |
|
Messages not saved. |
Saved in files. |
|
CloudHub |
Not trustworthy in case of a system crash. |
Reliable. |
Not saved. |
Saved in AWS queues |
Bonus Topic
Why call a VM connector if we have a flow reference?
If you want a task to be processed asynchronously (decoupled) you should use a VM connector, the task will continue in the flow that received the message — this can help you free resources. However, you can use a VM in a synchronous way too and persist the messages, but resources will not be freed.
Opinions expressed by DZone contributors are their own.
Comments