PostgreSQL as a Vector Database: Getting Started and Scaling
In this article, learn how to build and scale a sample Airbnb recommendation service using PostgreSQL as a vector database.
Join the DZone community and get the full member experience.
Join For FreePostgreSQL has a rich ecosystem of extensions and solutions that let us use the database for general-purpose AI applications. This guide walks you through the steps required to build generative AI applications using PostgreSQL as a vector database.
We'll begin with the pgvector extension, which enables Postgres with the capabilities specific to vector databases. Then, we'll review methods to enhance the performance and scalability of AI apps running on PostgreSQL. In the end, we'll have a fully functional generative AI application recommending Airbnb listings to those traveling to San Francisco.
Airbnb Recommendation Service
The sample application is a lodging recommendation service. Imagine that you're planning to visit San Francisco and wish to stay in a nice neighborhood near the Golden Gate Bridge. You go to the service, type in your prompt, and the app will suggest the three most relevant lodging options.
The app supports two distinct modes:
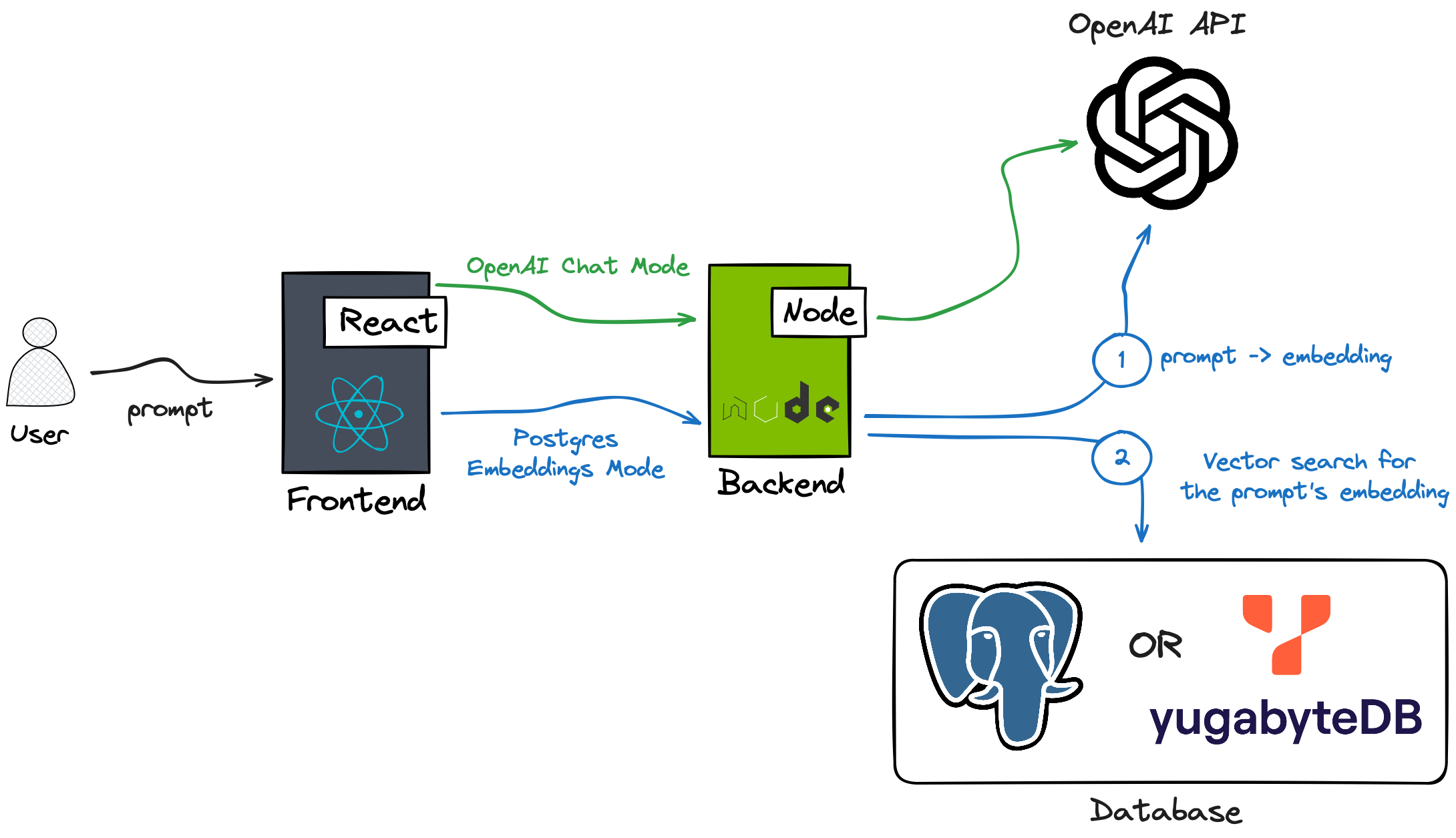
- OpenAI Chat Mode: In this mode, the Node.js backend leverages the OpenAI Chat Completion API and the GPT-4 model to generate lodging recommendations based on the user’s input. While this mode is not the focus of this guide, you are encouraged to experiment with it.
- Postgres Embeddings Mode: Initially, the backend employs the OpenAI Embeddings API to convert the user's prompt into an embedding (a vectorized representation of the text data). Next, the app does a similarity search in Postgres or YugabyteDB (distributed PostgreSQL) to find Airbnb properties that match the user's prompt. Postgres takes advantage of the pgvector extension for the similarity search in the database. This guide will delve into the implementation of this particular mode within the application.
Prerequisites
- An OpenAI subscription with access to an embedding model.
- The latest Node.js version
- The latest version of Docker
Start PostgreSQL With Pgvector
The pgvector extension adds all the essential capabilities of a vector database to Postgres. It lets you store and process vectors with thousands of dimensions, calculate Euclidean and cosine distances between vectorized data, and perform exact and approximate nearest-neighbor searches.
1. Start an instance of Postgres with pgvector in Docker:
docker run --name postgresql \
-e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=password \
-p 5432:5432 \
-d ankane/pgvector:latest2. Connect to the database container and open a psql session:
docker exec -it postgresql psql -h 127.0.0.1 -p 5432 -U postgres3. Enable the pgvector extension:
create extension vector;4. Confirm the vector is present in the extensions list:
select * from pg_extension;
oid | extname | extowner | extnamespace | extrelocatable | extversion | extconfig | extcondition
-------+---------+----------+--------------+----------------+------------+-----------+--------------
13561 | plpgsql | 10 | 11 | f | 1.0 | |
16388 | vector | 10 | 2200 | t | 0.5.1 | |
(2 rows)Load Airbnb Data Set
The application uses an Airbnb dataset that has over 7,500 properties listed in San Francisco for rental. Each listing provides a detailed property description, including the number of rooms, types of amenities, location, and other features. This information is a perfect fit for the similarity search against user prompts.
Follow the next steps to load the dataset into the started Postgres instance:
1. Clone the application repository:
git clone https://github.com/YugabyteDB-Samples/openai-pgvector-lodging-service.git2. Copy the Airbnb schema file to the Postgres container (replace the {app_dir} with a full path to the application directory):
docker cp {app_dir}/sql/airbnb_listings.sql postgresql:/home/airbnb_listings.sql3. Download the file with Airbnb data from the Google Drive location below. The size of the file is 174MB as long as it already includes embeddings generated for every Airbnb property's description using the OpenAI embedding model.
4. Copy the dataset to the Postgres container (replace the {data_file_dir} with the full path to the application directory).
docker cp {data_file_dir}/airbnb_listings_with_embeddings.csv postgresql:/home/airbnb_listings_with_embeddings.csv5. Create the Airbnb schema and load the data into the database:
# Create schema
docker exec -it postgresql \
psql -h 127.0.0.1 -p 5432 -U postgres \
-a -q -f /home/airbnb_listings.sql
# Load data
docker exec -it postgresql \
psql -h 127.0.0.1 -p 5432 -U postgres \
-c "\copy airbnb_listing from /home/airbnb_listings_with_embeddings.csv with DELIMITER '^' CSV;"Every Airbnb embedding is a 1536-dimensional array of floating-point numbers. It's a numerical/mathematical representation of an Airbnb property's description.
docker exec -it postgresql \
psql -h 127.0.0.1 -p 5432 -U postgres \
-c "\x on" \
-c "select name, description, description_embedding from airbnb_listing limit 1"
# Truncated output
name | Monthly Piravte Room-Shared Bath near Downtown !3
description | In the center of the city in a very vibrant neighborhood. Great access to other parts of the city with all modes of public transportation steps away Like the general theme of San Francisco, our neighborhood is a melting pot of different people with different lifestyles ranging from homeless people to CEO''s
description_embedding | [0.0064848186,-0.0030366974,-0.015895316,-0.015803888,-0.02674906,-0.0083198985,-0.0063770646,0.010318241,-0.011003947,-0.037981577,-0.008783566,-0.0005710134,-0.0028015983,-0.011519859,-0.02011404,-0.02023159,0.03325347,-0.017488765,-0.014902675,-0.006527267,-0.027820067,0.010076611,-0.019069154,-0.03239144,-0.013243919,0.02170749,0.011421901,-0.0044701495,-0.0005861153,-0.0064978795,-0.0006775427,-0.018951604,-0.027689457,-0.00033081227,0.0034317947,0.0098349815,0.0034775084,-0.016835712,-0.0013787586,-0.0041632145,-0.0058219694,-0.020584237,-0.007386032,0.012486378,0.012473317,0.005815439,-0.010990886,-0.015111651,-0.023366245,0.019069154,0.017828353,0.030249426,-0.04315376,-0.01790672,0.0047444315,-0.0053419755,-0.02195565,-0.0057338076,-0.02576948,-0.009769676,-0.016914079,-0.0035232222,... The embeddings were generated with OpenAI's text-embedding-ada-002 model. If you need to use a different model, then:
- Update the model in the
{app_dir}/backend/embeddings_generator.jsand{app_dir}/backend/postgres_embeddings_service.jsfile - Regenerate embeddings by starting the generator with the
node embeddings_generator.jscommand.
Find Most Relevant Airbnb Listings
By this point, Postgres is ready to recommend the most relevant Airbnb properties to users. The application can obtain those recommendations by comparing a user's prompt embedding with the embeddings of Airbnb descriptions.
First, start an instance of the Airbnb recommendations service:
1. Update the {app_dir}/application.properties.ini with your OpenAI API key:
OPENAI_API_KEY=<your key>2. Start the Node.js backend:
cd {app_dir}/backend/node
npm i
npm start3. Start the React frontend:
cd {app_dir}/frontend
npm i
npm startThe application UI should be opened automatically in your default browser. Otherwise, open it at this address.
Now, select the Postgres Embeddings mode from the application UI and ask the application to recommend a few Airbnb listings that are most relevant to the following prompt:
I'm looking for an apartment near the Golden Gate Bridge with a nice view of the Bay.The service will recommend three lodging options:
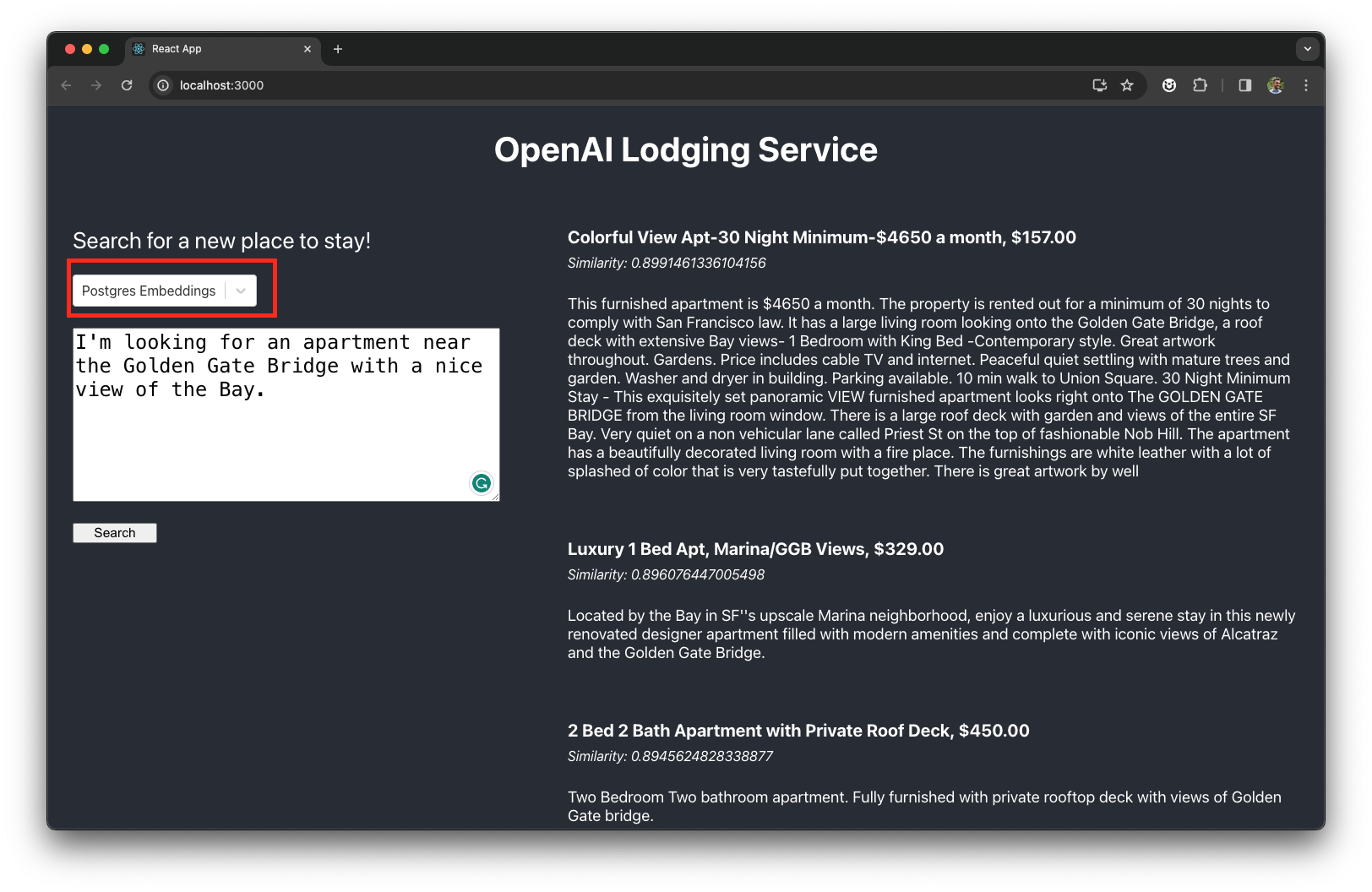
Internally, the application performs the following steps to generate the recommendations (see the {app_dir}/backend/postgres_embeddings_service.js for details):
1. The application generates a vectorized representation of the user prompt using the OpenAI Embeddings model (text-embedding-ada-002):
const embeddingResp = await this.#openai.embeddings.create(
{model: "text-embedding-ada-002",
input: prompt});2. The app uses the generated vector to retrieve the most relevant Airbnb properties stored in Postgres:
const res = await this.#client.query(
"SELECT name, description, price, 1 - (description_embedding <=> $1) as similarity " +
"FROM airbnb_listing WHERE 1 - (description_embedding <=> $1) > $2 ORDER BY description_embedding <=> $1 LIMIT $3",
['[' + embeddingResp.data[0].embedding + ']', matchThreshold, matchCnt]);The similarity is calculated as a cosine distance between the embeddings stored in the description_embedding column and the user prompt's vector.
3. The suggested Airbnb properties are returned in the JSON format to the React front-end:
let places = [];
for (let i = 0; i < res.rows.length; i++) {
const row = res.rows[i];
places.push({
"name": row.name,
"description": row.description,
"price": row.price,
"similarity": row.similarity });
}
return places;Ways to Scale
Presently, Postgres stores over 7,500 Airbnb properties. It takes milliseconds for the database to perform an exact nearest neighbor search, comparing embeddings of user prompts and Airbnb descriptions.
However, the exact nearest neighbor search (full table scan) has its limits. As the dataset grows, it will take longer for Postgres to perform the similarity search over multi-dimensional vectors.
To keep Postgres performant and scalable amid increasing data volumes and traffic, you can use specialized indexes for vectorized data and/or scale storage and compute resources horizontally using a distributed version of Postgres.
The pgvector extension supports several index types, including the top-performing HNSW index (Hierarchical Navigable Small World). This index performs an approximate nearest neighbor search (ANN) over vectorized data, allowing the database to maintain low and predictable latency even with large data volumes. However, as the search is approximate, the recall of the search might not be 100% relevant/accurate because the index only traverses a subset of the data.
For example, here’s how you can create an HNSW index in Postgres for the Airbnb embeddings:
CREATE INDEX ON airbnb_listing
USING hnsw (description_embedding vector_cosine_ops)
WITH (m = 4, ef_construction = 10);For a deeper understanding of how the HNSW index is built and performs the ANN search over the Airbnb data, check out this video:
With distributed PostgreSQL, you can easily scale database storage and compute resources when the capacity of a single database server is no longer sufficient. Although PostgreSQL was originally designed for single-server deployments, its ecosystem now includes several extensions and solutions that enable it to run in a distributed configuration. One such solution is YugabyteDB, a distributed SQL database that extends the capabilities of Postgres for distributed environments.
YugabyteDB supports the pgvector extension since version 2.19.2. It distributes data and embeddings across a cluster of nodes, facilitating similarity searches on a large scale. Thus, if you want the Airbnb service to run on a distributed version of Postgres:
1. Deploy a multi-node YugabyteDB cluster.
2. Update the database connectivity settings in the {app_dir}/application.properties.ini file:
# Configuration for a locally running YugabyteDB instance with defaults.
DATABASE_HOST=localhost
DATABASE_PORT=5433
DATABASE_NAME=yugabyte
DATABASE_USER=yugabyte
DATABASE_PASSWORD=yugabyte3. Load the data from scratch (or migrate it from the running Postgres instance using YugabyteDB Voyager) and restart the application. No other code-level changes are necessary because YugabyteDB is feature and runtime-compatible with Postgres.
Watch the following video to see how the Airbnb recommendation service works over a distributed version of Postgres:
Have fun building scalable AI applications with Postgres, and let me know if you wish to learn more about Postgres as a vector database.
Published at DZone with permission of Denis Magda. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments