Precision, Recall, and Identity Error in Programmatic Advertising
Programmatic ads optimize for reach because recall is easy to measure. Match rates show how much of the audience is resolved, not how accurately it’s targeted.
Join the DZone community and get the full member experience.
Join For FreeProgrammatic identity decisions are always tradeoffs between reach and correctness, even when they are presented as simple “match” or “addressability” metrics. Systems that optimize reach without explicitly managing identity error quietly degrade performance, learning, and trust—often without any single metric clearly signaling what went wrong.
This is Part 2 of a series on how audiences become addressable in programmatic advertising. Part 1 established a shared mental model: programmatic as a distributed decision system, identity as the upstream state representation, and match rate as a descriptive but fragile signal. This article focuses on what happens next: how identity error enters the system, how it propagates, and how operators can reason about precision in practice.
What the System Is Actually Deciding at Impression Time
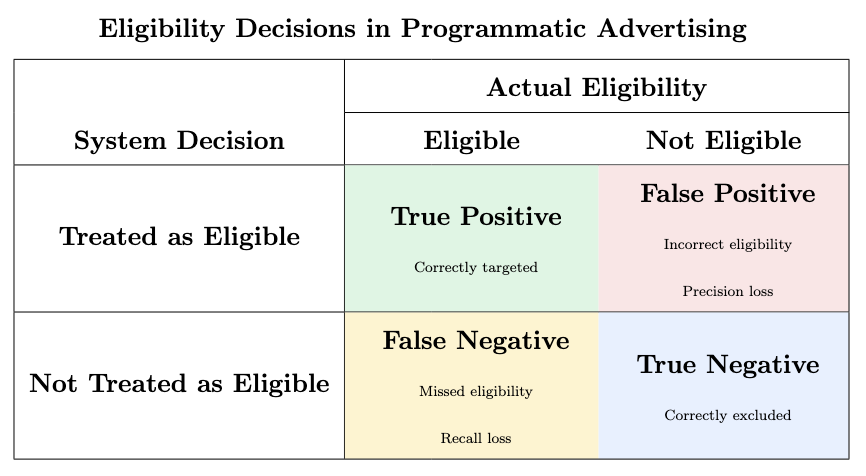
At activation time, every programmatic system is answering a practical eligibility question: Should we treat this impression as belonging to the intended audience and bid accordingly?
Identity is how the system arrives at an answer — but identity is never fully observed. It is inferred from deterministic keys, probabilistic linkages, and platform-specific resolution logic, all under latency and policy constraints. Once framed this way, identity quality becomes operational. Every decision has two possible failure modes:
- Missed eligibility (false negatives): impressions that should have been eligible but weren’t recognized.
- Incorrect eligibility (false positives): impressions treated as eligible but belonging to the wrong entity.
These map directly to recall and precision.
Precision and Recall, Translated Into Advertisers' Terms
In practice:
- Recall loss shows up as:
- Low match rate
- Small reachable audience
- Difficulty spending
- Complaints that “we can’t reach our customers
- Precision loss shows up as:
- Declining conversion or lead quality
- Weak or inconsistent incrementality
- Unstable learning
- Performance that doesn’t scale with budget
The critical imbalance: Recall is visible immediately, precision usually is not; that asymmetry shapes behavior across the ecosystem.
Why Most Systems Drift Toward Recall (Even When Teams Are Careful)
Even sophisticated organizations end up recall-heavy for structural reasons:
- Recall is instrumented; precision isn’t: Destinations can instantly report match rate or reachable size. They cannot easily report false-positive rates because the “true” eligible set is rarely observable.
- Coverage enables spend: Platforms are rewarded for making impressions addressable. Failing closed (high precision, low recall) often looks like underperformance compared to peers.
- Learning masks the root cause: Bidding models can partially adapt to noisy identity. That masks precision loss until it becomes large enough to overwhelm the system.
The result is not negligence; it’s a predictable system outcome.
Let's consider a common, well-intentioned scenario, person-level audiences to household-level CTV:
The setup:
- An advertiser has a person-level audience: known converters with hashed email.
- The goal is incremental reach via CTV.
- The CTV environment resolves primarily at the household level.
What happens in practice:
- The audience list is onboarded successfully.
- The match rate looks strong once household resolution and graph expansion are applied.
- Spend ramps smoothly; reach looks impressive.
Where identity error enters:
- Each matched household may contain:
- The intended individual
- Additional adults
- Children
- No longer the original individual at all
- The system has effectively shifted the targeting entity from person to household, without explicitly acknowledging the change.
Observed symptoms
- Top-of-funnel conversions may hold.
- Downstream quality (site depth, lead qualification, repeat purchase) weakens.
- Incremental lift flattens earlier than expected.
- Frequency controls feel “off” because the system believes it is pacing across fewer entities than it actually is.
Nothing is “broken.” The system is working as designed. But precision has changed, and no match-rate metric captures that shift. This is not a CTV problem. The same pattern appears whenever the targeting entity drifts across layers.
Why Match Rate Fails as an Identity KPI
Match rate measures overlap between an input audience and a destination’s current identity space. It primarily reflects recall.
It does not indicate whether the resolved identity corresponds to the intended targeting entity, whether probabilistic expansion introduced false positives, or whether the marginal impressions are incremental.
This leads to a common trap: addressability improves, spend becomes easier, but incremental outcomes flatten or degrade. The system responds by broadening further or bidding down, absorbing identity error into optimization rather than surfacing it.
From the outside, this looks like diminishing returns or creative fatigue. In reality, it is often precision dilution.
Why Precision Loss Is Especially Dangerous for Learning Systems
Identity error is not just inefficient spend; it degrades the system’s ability to learn.
False positives introduce label noise. Conversions are attributed to the wrong clusters, negatives are misclassified, and value estimates blur across heterogeneous populations. Over time, this destabilizes automated bidding, lookalike modeling, and cross-channel learning.
Measurement frameworks do not rescue this. Attribution assumes eligibility correctness. Incrementality methods estimate effects of exposure, not accuracy of assignment. Clean rooms constrain joins and enforce governance boundaries, but they do not improve identity truth.
If the treated population is wrong, even well-designed experiments estimate the wrong effect.
Detecting Precision Risk Without Ground Truth
Most teams do not observe true eligibility. That is normal. Precision risk can still be monitored indirectly.
Segment delivery and outcomes by identity path — deterministic resolution versus expanded or modeled paths. Watch the marginal difference.
Track down-funnel quality, not just top-of-funnel conversion. Precision loss often appears in qualification rates, close rates, returns, or churn before it appears in CPA.
Monitor stability over time. Precision-poor audiences tend to be volatile across refreshes and sensitive to small budget changes.
Look for early saturation. If returns flatten before frequency is meaningfully high, suspect eligibility dilution before blaming creative or bidding.
These signals are imperfect, but they are directionally aligned with precision in ways match rate is not.
Identity Governance: What “Good Enough” Looks Like Operationally
You don’t need a perfect identity to run an effective programmatic. You do need discipline.
At minimum:
- Explicitly define the targeting entity for each use case.
- Separate augmentation from expansion in design and reporting.
- Treat expansion as a population change, not just a reach boost.
- Require incremental validation when identity scope changes.
This is less about control and more about clarity.
Conclusion: Precision Is the Constraint, Not Reach
Modern programmatic systems make it easy to buy reach across fragmented environments. What’s scarce is controlled, explainable precision — especially as identity shifts across web, app, CTV, and retail media.
Match rate exists because it’s easy to observe. Treated as a KPI, it incentivizes aggressive linkage and hides error. Treated as a diagnostic, it helps explain system behavior but must be paired with downstream signals and experimentation.
The real operator question is not “how addressable is this audience?” It is: How much identity error are we introducing, and are we proving that the marginal reach is incremental?
Part 3 of this series focuses on how to answer that question systematically — using experimentation, incrementality, and governance frameworks that scale.
Opinions expressed by DZone contributors are their own.
Comments