Protecting Your Domain-Driven Design from Anemia
What do Monopoly and domain-driven software development have in common? Check out the answer and 4 ways to keep your domain encapsulated and avoiding anemia.
Join the DZone community and get the full member experience.
Join For FreeProviso: I largely refer to Java implementation aspects in this article but the principles are transferable to other languages
Sometimes with my children, when the nights draw in, we play board games to pass the time. Monopoly is a favorite. Of course, it comes with the board and counters, the cards and the money. There's a rule book too in the box but that is largely left to the side; we know the rules already. We put out the board, place the counters and cards, and begin to play the game. It's usually a great deal of fun.
There are two different aspects of what's happening here which I'd like to draw your attention to; there are the physical elements of the game - the board, the counters, the money, and so on - which live in the box most of the time, and there are the non-physical elements such as the rules, which as mentioned, generally live in our minds.
These two aspects - the physical and the non-physical - have different properties, different life cycles, and are used in different ways. They are both needed together to play the game.
In domain-driven software development, there is a similar situation: there are data fields and structures, (which we might liken to the physical pieces of the game), and there is the programming logic, or business logic, which governs how the data fields can be changed and manipulated. Software needs to use both aspects together to produce an application or microservice, but in many senses, these two things are quite different and have different requirements and life cycles. This is summarized in the table below.
Physical |
Non-physical |
When both exist together as a whole |
|
|---|---|---|---|
| Application | data fields | business logic | rich domain model |
| Game | game pieces | rules | full game set |
Consider how the data fields in a micro-service class might be used. They will generally exist as part of a domain class. Methods within the class operate on them and change their values, they validate them and ensure the class as a whole is always consistent and makes sense. They form part of the rich domain model. As they represent data their life goes beyond this also - the class might be persisted to disk or database or be placed into an in-memory cache. They might be converted into JSON and used in an external web service call. Often they don't only exist as part of the domain model but they have these additional lives elsewhere.
The business logic, on the other hand always lives as part of the domain model, is often attached to a specific class and operates on a specific set of data. It is never persisted as an entity in a database or in a file because it never changes. (Or never changes without an upgrade of the application, at least). It does not need to be transformed in different ways to suit its different usages. It is static.
The figure below shows a simple example. "Product" is a class existing within a domain model. The business logic pertaining to the Product class can exist within the class itself and the business logic for the domain can be tested in isolation. The Product class contains data fields and these can be persisted to a database. As part of that process the data fields are first wrapped in another class, and then transformed into a JPA entity before being persisted. In this example a version is added to the data to assist with optimistic locking in the database.
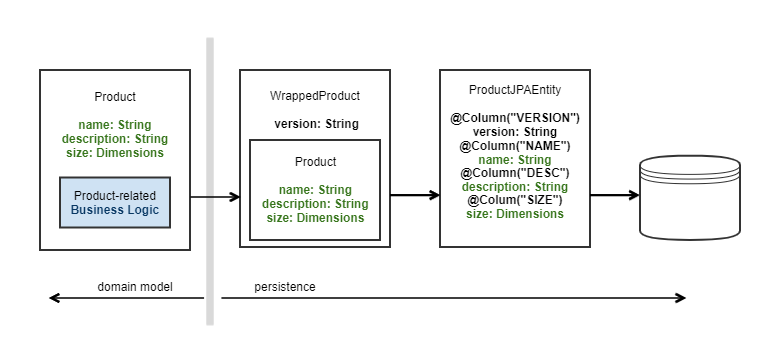
As a second example, if I wish to store the data in a class into an in-memory data grid, such as Hazelcast, I need to transfer the data into an object which can be serialized and which has a unique key. (Keys in Hazelcast need to provide identity without considering the content of the data). Again we need to add information to the domain model in order to use the data in other places or with other tools.
So our code has these two aspects -- data and business logic -- and they are quite different. They serve different needs and are handled in different ways. We are taught to nevertheless bind the two together and build rich domain models. Martin Fowler mentions "A domain model mingles data and processes, has multi-valued attributes and a complex web of associations, and uses inheritance." (PoEAA)
It's great if we can do this and have all the logic and validations associated with a given domain class living within the class, but as we have seen above the reality is often that the data needs to be stored, retrieved, cached and so on, and the business logic does not.
We are caught between a rock and a hard place. If we extract the data fields from the business logic in order to support the different operations we need to do to the data, then we may be left with POJOs or DTOs; objects that Martin Fowler describes as 'hateful' and 'things our mothers told us never to write' (PoEAA again). In the worse case our domain model will become "anemic". You can read about "anemic domain models" here ( AnedmicDomainModel ). Others describe anemic domain models as the anti-pattern of the devil! (ADM2). Clearly there are demons here.
On the other hand if we don't separate the data and logic we may need to add additional info to our domain model which is not directly relevant, which adds clutter and binds the domain model to other layers of our architecture. It may even prevent us using some open source technologies or force us to add additional untidy code to work around this abstraction.
A compromise is needed! We need to find a way to avoid the pitfalls of an anemic domain model whilst still allowing us to separate the data fields from the business logic if we need to. How can we do that? Well the first consideration is 'Why are anemic domain models bad in the first place?' Anemic domain models lead to business logic becoming spread throughout your application. The services layer, for example, may do more than just co-ordinate changes, it may include rules for how the domain objects are created and changed. We might find multiple parts of the application attempting to do the same domain changes in different ways and perhaps ending up with different results. We can't in general manage access to the domain model and its business logic with an anemic domain model.
Therefore if we are forced to separate data and business logic these still both need to reside together, tightly coupled, in the domain layer. There needs to be clear rules about how to create and change the model and ideally an interface to initiate those changes which can be used by other layers of the application.
What techniques can we use, then, to ensure access to the domain model is controlled and managed? Here are four:
1. Use Package-Level Setters
put the domain business logic in the same package as the POJOs and make the POJO fields private. Provide public getters and make the setters accessible only from the package. The code snippet below shows this:
package domain.encapsulation.example;
public class Product {
private int id;
private String name;
private String description;
private double width,height,depth;
//public access
public int getId() { return id; }
//package level access
void setId(int id) { this.id = id; }
//public access
public String getName() { return name; }
//package level access
void setName(String name) { this.name = name; }
...
}
This has the advantage that only classes within the same package can change the data fields in the domain model, so business logic can't get strewn throughout the application, and it allows you to provide interfaces in to your model to ensure it is modified in a controlled manner. It means that the whole of your domain needs to exist within a single java package which isn't ideal. Package-level access in Java does not allow sub-package classes to access the fields of classes in packages higher up the hierarchy.
2. Use a Fully Parameterised Constructor
Use a constructor taking all the parameters and then make the setters private.
xxxxxxxxxx
package domain.encapsulation.example;
public class Product {
private int id;
private String name;
private String description;
private double width,height,depth;
public Product( int id, String name, String description, double width, double height, double depth ){
this.id=id;
this.name=name;
this.description=description;
this.width=width;
this.height=height;
this.depth=depth;
}
//public access
public int getId() { return id; }
//private access
private void setId(int id) { this.id = id; }
//public access
public String getName() { return name; }
//private access
private void setName(String name) { this.name = name; }
...
}
This is fine if you never want anything to change your class once it has been created. In that case you could also make all of the fields 'final' and you'd end up with an immutable object. That is something more suited for Value Objects rather than Domain Objects. Nevertheless you could use a public constructor which takes all initial field values as parameters together with the restricted access to the setters from (1) to allow instances of your domain objects to be created in a controlled manner.
3. Use the Factory Pattern
If you make your object constructor private and then use a Factory class to create different sub-classes this would also give you control over how your domain classes are created and validated. Some of your business logic can then reside in the factory class. However it adds complexity - your POJO might become a set of different derived classes, each with different data fields, which in some senses takes you away from what you need; a simple object with externalized business logic. It doesn't really prevent developers directly accessing the sub-classes either, so only offers limited restrictions.
4. Control Cross-Package Access
Finally there are slightly more exotic ways to govern access to your domain; let's go through these in more detail. In the (pseudo) code examples below we have a POJO domain object -- Product -- and we use a static method call - AccessControl.checkAuthorized() - to protect access to one of the setters. AccessControl makes use of the Java stack to examine which part of the application is calling the setter. If the caller of the setter is a class which has a package name which does not match our domain package prefix then an exception is thrown and the setter cannot be called.
xxxxxxxxxx
package domain.encapsulation.example.model;
import domain.encapsulation.example.security.AccessControl;
public class Product {
...
public void setName(String name) {
AccessControl.checkAuthorized();
this.name=name;
}
...
}
xxxxxxxxxx
package domain.encapsulation.example.security;
public class AccessControl {
private static final String DOMAIN_PACKAGE = "domain.encapsulation.example.model.";
public static void checkAuthorized() {
//Examine the stacktrace to ensure calling method has same package prefix as the domain
StackTraceElement[] stackTraceElements = Thread.currentThread().getStackTrace();
if (stackTraceElements.length>=4) {
String resourceBeingAccessed = stackTraceElements[2].getClassName();
String accessAttemptedFrom = stackTraceElements[3].getClassName();
if (resourceBeingAccessed.startsWith(DOMAIN_PACKAGE) && accessAttemptedFrom.startsWith(DOMAIN_PACKAGE)) {
//In this case access to the setter is authorized
} else {
//A method in a non-domain package has tried to access the setter, so throw an exception
throw new RuntimeException("Access violoation. " + accessAttemptedFrom + " attempting to access " + resourceBeingAccessed);
}
}
}
}
For example, we might have a class in our application's service layer called domain.encapsulation.example.service.ProductScanner . The package of the class here is "domain.encapsulation.example.service" which differs from that of our domain model, which is "domain.encapsulation.example.model" . Thus if the service class attempts to call the (public) setter in our Product class, the AccessControl will prevent it and throw an exception.
There are a couple of points here to be careful of:
- We're using the stack to ensure that our POJO domain objects are only accessed from packages which we define as being 'inside' our domain layer. That allows our business logic, which exists within our domain layer to create and change the domain objects as it needs to but prevents other layers of our application having direct access to our POJO setters. However, the penalty we pay here is that Thread.currentThread().getStackTrace() is very slow to execute and so isn't something we would want to use continually as we create and modify our domain objects.
- Java does not support nested packages. Although it might look as though domain.encapsulation.example.model and domain.encapsulation.example.service are both subpackages of domain.encapsulation.example, this is not how Java interprets things. From the Java perspective these two packages are entirely separate. Nevertheless as human beings we often organise the code in our applications in a hierarchical fashion. We might have a package structure such as that below and we can then use that structure to define which parts live in the domain layer and which are other parts of our software. And, of course, we can then use that to allow access as needed.
application.domain application.domain.product application.domain.shipping application.service.search application.service.ordermanagement application.util
As it stands this is a little clunky: we're making calls to static class methods throughout our domain model and these perform poorly. We can tidy things up using Aspect Orientated programming (ref . https://en.wikipedia.org/wiki/Aspect-oriented_programming ). I've show this in the code snippets below.
xxxxxxxxxx
package domain.encapsulation.example.model;
public class Product {
...
(prefix="domain.encapsulation.example.model.")
public void setName(String name) {
this.name=name;
}
...
}
xxxxxxxxxx
public class AccessControlAspect {
...
("callAt(packageAccessOnly)")
public Object around(ProceedingJoinPoint pjp, PackageAccessOnly packageAccessOnly) throws Throwable {
//much as in AccessControl.checkAuthorized
...
if (accessAttemptedFrom.startsWith(prefix)) {
//In this case access to the setter is authorized
} else {
throw new AccessControlException("Access violation. " + accessAttemptedFrom + " attempting to access " + pjp.getSignature());
}
return pjp.proceed();
}
}
Here we use an annotation "PackageAccessOnly" to define which setter methods can be called from which package prefix. Then we use an Aspect to provide the implementation and control the authorization. We've explicitly defined 'prefix' in the annotation here but you could also use the current package as a sensible default. Using Aspects here with annotations allows us to remove the authorization checks using the aspect configuration, so that our production code does not need any performance penalties from our stack access, but our test code can leave the authorization in place to ensure we protect our domain.
This provides a convenient way to manage access to the domain model POJOs, allowing the business logic to be slightly removed from the domain POJOs themselves and thus also allowing the POJOs to be wrapped and transformed as need be for persistence and caching and so on.
In the end the relevant part of our class hierarchy might look like:
application.domain application.domain.product application.domain.product.Product application.domain.product.ProductManager application.domain.shipping application.service.search application.service.ordermanagement application.util
Product is our product POJO which we can transform elsewhere as needed. ProductManager contains the product related domain logic and has access to the Product setters. It provides a public set of methods which other layers of the application can use to transform the domain in a controlled manner. Classes in the application.service.search domain, for example, would not have access to the setters of Product and would need to use the ProductManager to access the product part of the domain. We still have a rich domain model here as all domain logic and fields are encapsulated but this richness is not occurring at the class level but at the slightly higher package level.
We can summarize our findings by extending the game analogy and the table we had above:
Physical |
Non-physical |
Both together as a whole |
Both disconnected |
Exist alongside each other with managed access |
|
|---|---|---|---|---|---|
| Application | data fields | business logic | rich domain model | anemic domain model, business logic strewn throughout application and inconsistently applied | data and business logic live side by side in one specific place with managed access from the rest of the application |
| Game | game pieces | rules | full game set | everyone making up their own rules, no consistency, chaos | the rule book might be lost but everyone agrees on a new set and applies them consistently |
Summary
We all want to use domain-driven design and use rich domain models to create applications that mirror our business objects and the business logic associated with them. Data and logic, however, have different lives within our code base and are handled and transformed in different ways. This means that even with the best will in the world, sometimes our domain models will become anemic. Provided we are careful to ensure that the business logic remains with the domain model and isn't spread throughout our application or UI, we can mitigate the negative effects of that anemia and Martin Fowler's mother can stay happy.
Opinions expressed by DZone contributors are their own.
Comments