Python Function Pipelines: Streamlining Data Processing
Function pipelines allow seamless execution of multiple functions in a sequential manner, where the output of one function serves as the input to the next.
Join the DZone community and get the full member experience.
Join For FreeFunction pipelines allow seamless execution of multiple functions in a sequential manner, where the output of one function serves as the input to the next. This approach helps in breaking down complex tasks into smaller, more manageable steps, making code more modular, readable, and maintainable. Function pipelines are commonly used in functional programming paradigms to transform data through a series of operations. They promote a clean and functional style of coding, emphasizing the composition of functions to achieve desired outcomes.
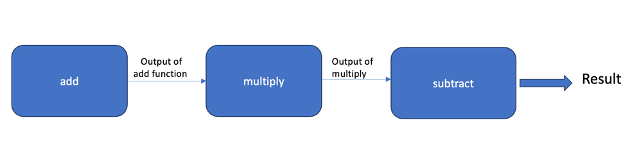
In this article, we will explore the fundamentals of function pipelines in Python, including how to create and use them effectively. We'll discuss techniques for defining pipelines, composing functions, and applying pipelines to real-world scenarios.
Creating Function Pipelines in Python
In this segment, we'll explore two instances of function pipelines. In the initial example, we'll define three functions—'add', 'multiply', and 'subtract'—each designed to execute a fundamental arithmetic operation as implied by its name.
def add(x, y):
return x + y
def multiply(x, y):
return x * y
def subtract(x, y):
return x - y
Next, create a pipeline function that takes any number of functions as arguments and returns a new function. This new function applies each function in the pipeline to the input data sequentially.
# Pipeline takes multiple functions as argument and returns an inner function
def pipeline(*funcs):
def inner(data):
result = data
# Iterate thru every function
for func in funcs:
result = func(result)
return result
return inner
Let’s understand the pipeline function.
- The pipeline function takes any number of functions (*funcs) as arguments and returns a new function (inner).
- The inner function accepts a single argument (data) representing the input data to be processed by the function pipeline.
- Inside the inner function, a loop iterates over each function in the funcs list.
- For each function func in the funcs list, the inner function applies func to the result variable, which initially holds the input data. The result of each function call becomes the new value of result.
- After all functions in the pipeline have been applied to the input data, the inner function returns the final result.
Next, we create a function called ‘calculation_pipeline’ that passes the ‘add’, ‘multiply’ and ‘substract’ to the pipeline function.
# Create function pipeline
calculation_pipeline = pipeline(
lambda x: add(x, 5),
lambda x: multiply(x, 2),
lambda x: subtract(x, 10)
)
Then we can test the function pipeline by passing an input value through the pipeline.
result = calculation_pipeline(10)
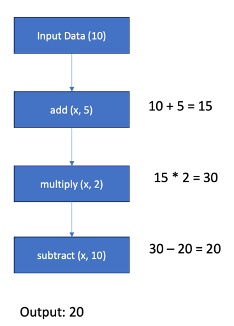
print(result) # Output: 20We can visualize the concept of a function pipeline through a simple diagram.
Another example:
def validate(text):
if text is None or not text.strip():
print("String is null or empty")
else:
return text
def remove_special_chars(text):
for char in "!@#$%^&*()_+{}[]|\":;'<>?,./":
text = text.replace(char, "")
return text
def capitalize_string(text):
return text.upper()
# Pipeline takes multiple functions as argument and returns an inner function
def pipeline(*funcs):
def inner(data):
result = data
# Iterate thru every function
for func in funcs:
result = func(result)
return result
return inner
# Create function pipeline
str_pipeline = pipeline(
lambda x : validate(x),
lambda x: remove_special_chars(x),
lambda x: capitalize_string(x)
)
Testing the pipeline by passing the correct input:
# Test the function pipeline
result = str_pipeline("Test@!!!%#Abcd")
print(result) # TESTABCD
In case of an empty or null string:
result = str_pipeline("")
print(result) # Error
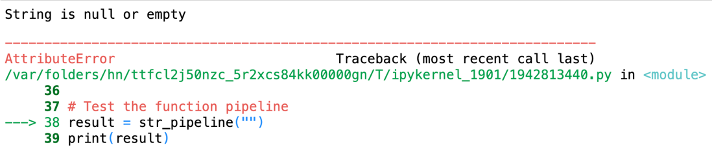
In the example, we've established a pipeline that begins by validating the input to ensure it's not empty. If the input passes this validation, it proceeds to the 'remove_special_chars' function, followed by the 'Capitalize' function.
Benefits of Creating Function Pipelines
- Function pipelines encourage modular code design by breaking down complex tasks into smaller, composable functions. Each function in the pipeline focuses on a specific operation, making it easier to understand and modify the code.
- By chaining together functions in a sequential manner, function pipelines promote clean and readable code, making it easier for other developers to understand the logic and intent behind the data processing workflow.
- Function pipelines are flexible and adaptable, allowing developers to easily modify or extend existing pipelines to accommodate changing requirements.
Opinions expressed by DZone contributors are their own.
Comments