Quix Streams: Stream Processing With Kafka and Python
Quix Streams for open source stream processing with Kafka and Python to support data engineers to implement machine learning data pipelines.
Join the DZone community and get the full member experience.
Join For FreeOver 100,000 organizations use Apache Kafka for data streaming. However, there is a problem: The broad ecosystem lacks a mature client framework and managed cloud service for Python data engineers. Quix Streams is a new technology on the market trying to close this gap. This blog post discusses this Python library, its place in the Kafka ecosystem, and when to use it instead of Apache Flink or other Python- or SQL-based substitutes.
Why Python and Apache Kafka Together?
Python is a high-level, general-purpose programming language. It has many use cases for scripting and development. But there is one fundamental purpose for its success: Data engineers and data scientists use Python. Period.
Yes, there is R as another excellent programming language for statistical computing. And many low-code/no-code visual coding platforms for machine learning (ML).
SQL usage is ubiquitous amongst data engineers and data scientists, but it’s a declarative formalism that isn’t expressive enough to specify all necessary business logic. When data transformation or non-trivial processing is required, data engineers and data scientists use Python.
Hence, data engineers and data scientists use Python. If you don’t give them Python, you will find either shadow IT or Python scripts embedded into the coding box of a low-code tool.
Apache Kafka is the de facto standard for data streaming. It combines real-time messaging, storage for true decoupling and replayability of historical data, data integration with connectors, and stream processing for data correlation. All in a single platform. At scale for transactions and analytics.
Python and Apache Kafka for Data Engineering and Machine Learning
In 2017, I wrote a blog post about “How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka.” The article is still accurate and explores how data streaming and AI/ML are complementary:
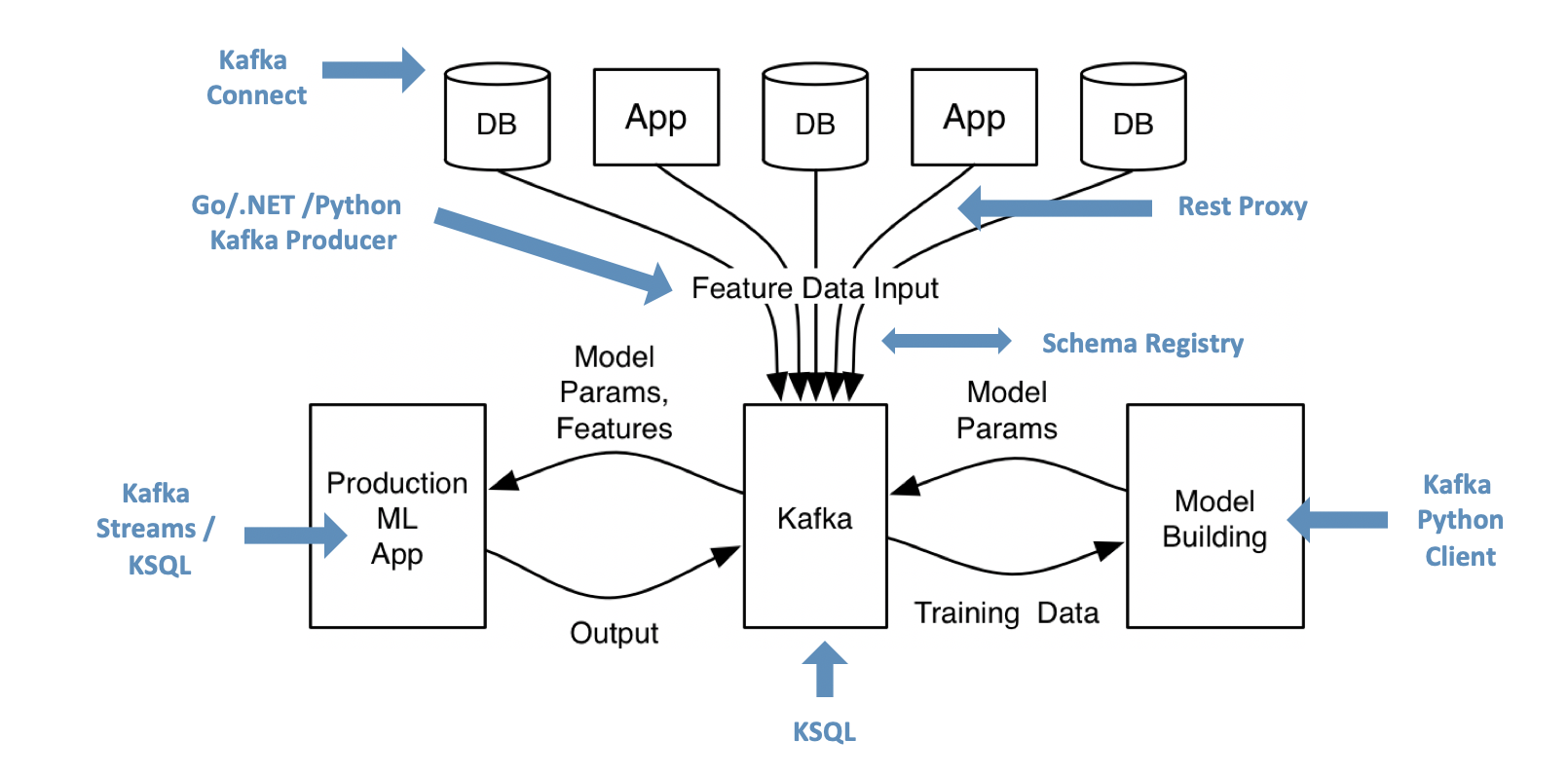
Machine Learning requires a lot of infrastructure for data collection, data engineering, model training, model scoring, monitoring, and so on. Data streaming with the Kafka ecosystem enables these capabilities in real-time, reliable, and at scale.
DevOps, microservices, and other modern deployment concepts merged the job roles of software developers and data engineers/data scientists. The focus is much more on data products solving a business problem, operated by the team that develops it. Therefore, the Python code needs to be production-ready and scalable.
As mentioned above, the data engineering and ML tasks are usually realized with Python APIs and frameworks. Here is the problem: The Kafka ecosystem is built around Java and the JVM. Therefore, it lacks good Python support.
Let’s explore the options and why Quix Streams is a brilliant opportunity for data engineering teams for machine learning and similar tasks.
What Options Exist for Python and Kafka?
Many alternatives exist for data engineers and data scientists to leverage Python with Kafka.
Python Integration for Kafka
Here are a few common alternatives for integrating Python with Kafka and their trade-offs:
- Python Kafka client libraries: Produce and consume via Python. This is solid but insufficient for advanced data engineering as it lacks processing primitives, such as filtering and joining operations found in Kafka Streams and other stream processing libraries.
- Kafka REST APIs: Confluent REST Proxy and similar components enable producing and consuming to/from Kafka. It works well for gluing interfaces together but is not ideal for ML workloads with low latency and critical SLAs.
- SQL: Stream processing engines like ksqlDB or FlinkSQL allow querying of data in SQL. KsqlDB and Flink are other systems that need to be operated. And SQL isn’t expressive enough for all use cases.
Instead of just integrating Python and Kafka via APIs, native stream processing provides the best of both worlds: The simplicity and flexibility of dynamic Python code for rapid prototyping with Jupyter notebooks and serious data engineering AND stream processing for stateful data correlation at scale either for data ingestion and model scoring.
Stream Processing With Python and Kafka
In the past, we had two suboptimal open-source options for stream processing with Kafka and Python:
- Faust: A stream processing library, porting the ideas from Kafka Streams (a Java library and part of Apache Kafka) to Python. The feature set is much more limited compared to Kafka Streams. Robinhood open-sourced Faust. But it lacks maturity and community adoption. I saw several customers evaluating it but then moving to other options.
- Apache Flink’s Python API: Flink’s adoption grows significantly yearly in the stream processing community. This API is a Python version of DataStream API, which allows Python users to write Python DataStream API jobs. Developers can also use the Table API, including SQL, directly in there. It is an excellent option if you have a Flink cluster and some folks want to run Python instead of Java or SQL against it for data engineering. The Kafka-Flink integration is very mature and battle-tested.
As you see, all the alternatives for combining Kafka and Python have trade-offs. They work for some use cases but are imperfect for most data engineering and data science projects.
A new open-source framework to the rescue? Introducing a brand new stream processing library for Python: Quix Streams…
What Is Quix Streams?
Quix Streams is a stream processing library focused on ease of use for Python data engineers. The library is open-source under Apache 2.0 license and available on GitHub.
Instead of a database, Quix Streams uses a data streaming platform such as Apache Kafka. You can process data with high performance and save resources without introducing a delay.
Some of the Quix Streams differentiators are defined as being lightweight and powerful, with no JVM and no need for separate clusters of orchestrators. It sounds like the pitch for why to use Kafka Streams in the Java ecosystem minus the JVM — this is a positive comment! :-)
Quix Streams does not use any domain-specific language or embedded framework. It’s a library that you can use in your code base. This means that with Quix Streams, you can use any external library for your chosen language. For example, data engineers can leverage Pandas, NumPy, PyTorch, TensorFlow, Transformers, and OpenCV in Python.
So far, so good. This was more or less the copy and paste of Quix Streams marketing (it makes sense to me)… Now, let’s dig deeper into the technology.
The Quix Streams API and Developer Experience
The following is the first feedback after playing around, doing code analysis, and speaking with some Confluent colleagues and the Quix Streams team.
The Good
- The Quix API and tooling persona is the data engineer (that’s at least my understanding). Hence, it does not directly compete with other offerings, say a Java developer using Kafka Streams. Again, the beauty of microservices and data mesh is the focus of an application or data product per use case. Choose the right tool for the job!
- The API is mostly sleek, with some weirdness / unintuitive parts. But it is still in beta, so hopefully, it will get more refined in the subsequent releases. No worries at this early stage of the project.
- The integration with other data engineering and machine learning Python frameworks is excellent. If you can combine stream processing with Pandas, NumPy, and similar libraries is a massive benefit for the developer experience.
- The Quix library and SaaS platform are compatible with open-source Kafka and commercial offerings and cloud services like Cloudera, Confluent Cloud, or Amazon MSK. Quix’s commercial UI provides out-of-the-box integration with self-managed Kafka and Confluent Cloud. The cloud platform also provides a managed Kafka for testing purposes (for a few cents per Kafka topic and not meant for production).
The Improvable
- The stream processing capabilities (like powerful sliding windows) are still pretty limited and not comparable to advanced engines like Kafka Streams or Apache Flink. The roadmap includes enhanced features.
- The architecture is complex since executing the Python API jumps through three languages: Python -> C# -> C++. Does it matter to the end user? It depends on the use case, security requirements, and more. The reasoning for this architecture is Quix’s background coming from the McLaren F1 team and ultra-low latency use cases and building a polyglot platform for different programming environments.
- It would be interesting to see a benchmark for throughput and latency versus Faust, which is Python top to bottom. There is a trade-off between inter-language marshaling/unmarshalling versus the performance boost of lower-level compiled languages. This should be fine if we trust Quix’s marketing and business model. I expect they will provide some public content soon, as this question will arise regularly.
The Quix Streams Data Pipeline Low Code GUI
The commercial product provides a user interface for building data pipelines and code, MLOps, and a production infrastructure for operating and monitoring the built applications.
Here is an example:
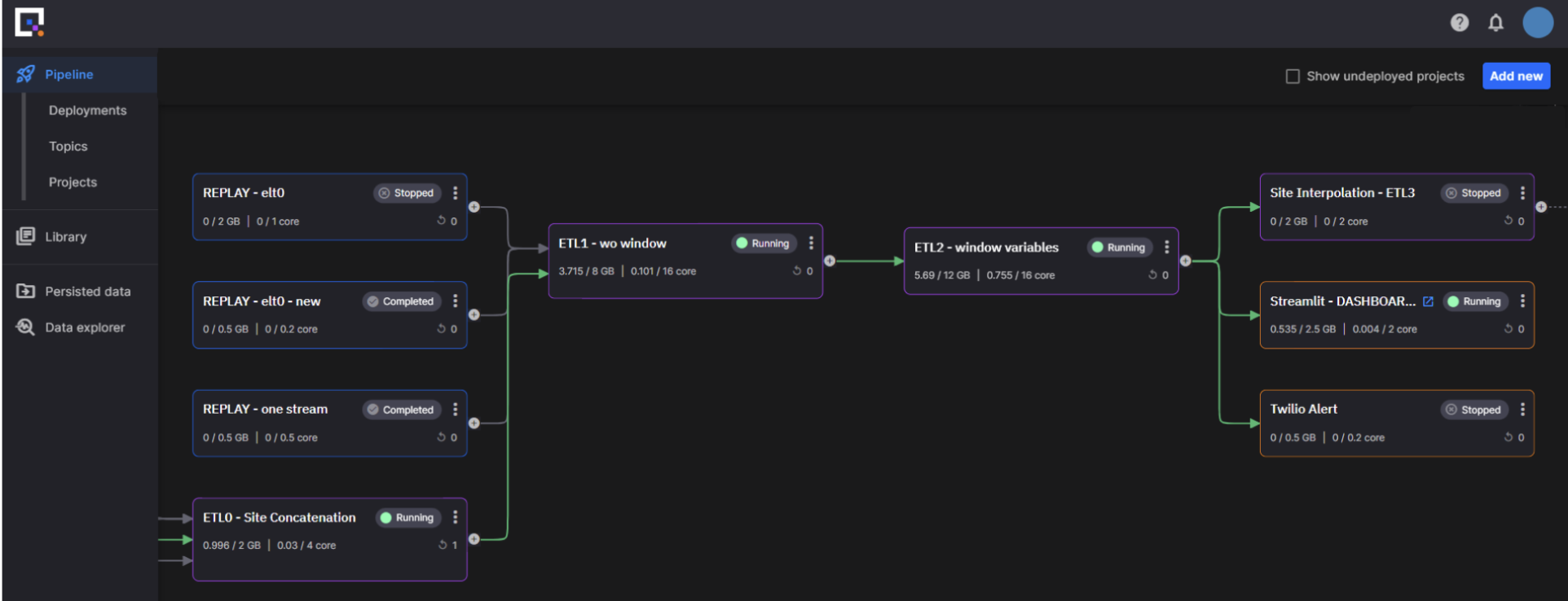
- Tiles are K8’s containers. Each purple (transformation) and orange (destination) node is backed by a Git project containing the application code.
- The three blue (source) nodes on the left are replay services used to test the pipeline by replaying specific streams of data.
- Arrows are individual Kafka topics in Confluent Cloud (green = live data).
- The first visible pipeline node (bottom left) is joining data from different physical sites (see the three input topics; one was receiving data when I took the image).
- There are three modular transformations in the visible pipeline (two rolling windows and one interpolation).
- There are two real-time apps (one real-time Streamlit dashboard and the other is an integration with a Twilio SMS service).
Quix Streams vs. Apache Flink for Stream Processing With Python
The Quix team wrote a detailed comparison of Apache Flink and Quix Streams. I don’t think it’s an entirely fair comparison as it compares open-source Apache Flink to a Quix SaaS offering. Nevertheless, for the most part, it is a good comparison.
Flink was always Java-first and has added support for Python for its DataStream and Table APIs at a later stage. On the contrary, Quix Streams is brand new. Hence, it lacks maturity and customer case studies.
Having said all this, I think Quix Streams is a great choice for some stream processing projects in the Python ecosystem!
Should You Use Quix Streams or Apache Flink?
TL;DR: There is a place for both! Choose the right tool… Modern enterprise architectures built with concepts like data mesh, microservices, and domain-driven design allow this flexibility per use case and problem.
I recommend using Flink if the use case makes sense with SQL or Java. And if the team is willing to operate its own Flink cluster or has a platform team or a cloud service taking over the operational burden and complexity.
On the contrary, I would use Quix Streams for Python projects if I want to go to production with a more microservice-like architecture building Python applications. However, beware that Quix currently only has a few built-in stateful functions or JOINs. More advanced stream processing use cases cannot be done with Quix (yet). This is likely to change in the next months by adding more capabilities.
Hence, make sure to read Quix’s comparison with Flink. But keep in mind if you want to evaluate the open-source Quix Streams library or the Quix SaaS platform. If you are in the public cloud, you might combine Quick Streams SaaS with other fully managed cloud services like Confluent Cloud for Kafka. On the other side, in your own private VPC or on-premise, you need to build your own platform with technologies like the Quix Streams library, Kafka or Confluent Platform, and so on.
The Current State and Future of Quix Streams
If you build a new framework or product for data streaming, you need to make sure that it does not overlap with existing established offerings. You need differentiators and/or innovation in a new domain that does not exist today.
Quix Streams accomplishes this essential requirement to be successful: The target audience is data engineers with Python backgrounds. No severe and mature tool or vendor exists in this space today. And the demand for Python will grow more and more with the focus on leveraging data for solving business problems in every company.
Maturity: Making the Right (Marketing) Choices in the Early Stage
Quix Streams is in the early maturity stage. Hence, a lot of decisions can still be strengthened or revamped.
The following buzzwords come into my mind when I think about Quix Streams: Python, data streaming, stream processing, Python, data engineering, Machine Learning, open source, cloud, Python, .NET, C#, Apache Kafka, Apache Flink, Confluent, MSK, DevOps, Python, governance, UI, time series, IoT, Python, and a few more.
TL;DR: I see a massive opportunity for Quix Streams to become a great data engineering framework (and SaaS offering) for Python users.
I am not a fan of polyglot platforms. It requires finding the lowest common denominator. I was never a fan of Apache Beam for that reason. The Kafka Streams community did not choose to implement the Beam API because of too many limitations.
Similarly, most people do not care about the underlying technology. Yes, Quix Streams’ core is C++. But is the goal to roll out stream processing for various programming languages, only starting with Python, then going to .NET, and then to another one? I am skeptical.
Hence, I would like to see a change in the marketing strategy already: Quix Streams started with the pitch of being designed for high-frequency telemetry services when you must process high volumes of time-series data with up to nanosecond precision. It is now being revamped to focus mainly on Python and data engineering.
Competition: Friends or Enemies?
Getting market adoption is still hard. Intuitive use of the product, building a broad community, and the right integrations and partnerships (can) make a new product such as Quix Streams successful. Quix Streams is on a good way here. For instance, integrating serverless Confluent Cloud and other Kafka deployments works well:
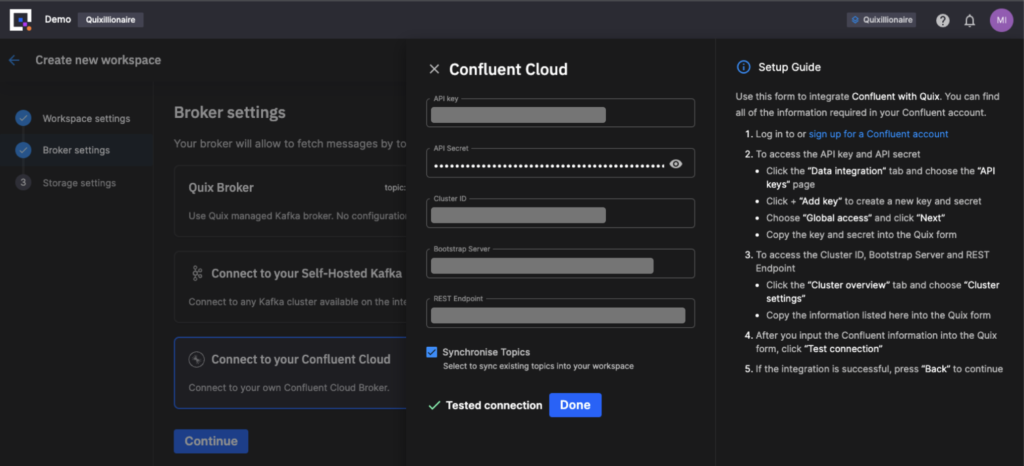
This is a native integration, not a connector. Everything in the pipeline image runs as a direct Kafka protocol connection using raw TCP/IP packets to produce and consume data to topics in Confluent Cloud. Quix platform is orchestrating the management of the Confluent Cloud Kafka Cluster (create/delete topics, topic sizing, topic monitoring, etc.) using Confluent APIs.
However, one challenge of these kinds of startups is the decision to complement versus compete with existing solutions, cloud services, and vendors. For instance, how much time and money do you invest in data governance? Should you build this or use the complementing streaming platform or a separate independent tool (like Collibra)? We will see where Quix Streams will go here —building its cloud platform for addressing Python engineers or overlapping with other streaming platforms.
My advice is the proper integration with partners that lead in their space. Working with Confluent for over six years, I know what I am talking about: We do one thing: data streaming, but we are the best in that one. We don’t even try to compete with other categories. Yes, a few overlaps always exist, but instead of competing, we strategically partner and integrate with other vendors like Snowflake (data warehouse), MongoDB (transactional database), HiveMQ (IoT with MQTT), Collibra (enterprise-wide data governance), and many more. Additionally, we extend our offering with more data streaming capabilities, i.e., improving our core functionality and business model. The latest example is our integration of Apache Flink into the fully managed cloud offering.
Kafka for Python? Look At Quix Streams!
In the end, a data engineer or developer has several options for stream processing deeply integrated into the Kafka ecosystem:
- Kafka Streams: Java client library
- ksqlDB: SQL service
- Apache Flink: Java, SQL, Python service
- Faust: Python client library
- Quix Streams: Python client library
All have their pros and cons. The persona of the data engineer or developer is a crucial criterion. Quix Streams is a nice new open-source framework for the broader data streaming community. If you cannot or do not want to use just SQL but native Python, then watch the project (and the company/cloud service behind it).
bytewax is another open-source stream processing library for Python integrating with Kafka. It is implemented in Rust under the hood. I never saw it in the field yet. But a few comments mentioned it after I shared this blog post on social networks. I think it is worth a mention. Let’s see if it gets more traction in the following months.
Published at DZone with permission of Kai Wähner. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments