Harnessing Real-Time Insights With Streaming SQL on Kafka
Streaming SQL enables real-time data processing and analytics on the fly, seamlessly querying Kafka topics for actionable insights without complex coding.
Join the DZone community and get the full member experience.
Join For FreeIn the era of real-time data, the ability to process and analyze streaming information has become critical for businesses. Apache Kafka, a powerful distributed event streaming platform, is often at the heart of these real-time pipelines. But working with raw streams of data can be complex. This is where Streaming SQL comes in: it allows users to query and transform Kafka topics with the simplicity of SQL.
What Is Streaming SQL?
Streaming SQL refers to the application of structured query language (SQL) to process and analyze data in motion. Unlike traditional SQL, which queries static datasets in databases, streaming SQL continuously processes data as it flows through a system. It supports operations like filtering, aggregating, joining, and windowing in real time.
With Kafka as the backbone of real-time data pipelines, Streaming SQL allows users to directly query Kafka topics, making it easier to analyze and act on the data without writing complex code.
Key Components of Streaming SQL on Kafka
1. Apache Kafka
Kafka stores and streams real-time events through topics. Producers write data to topics, and consumers subscribe to process or analyze that data. Kafka’s durability, scalability, and fault tolerance make it ideal for streaming data.
2. Kafka Connect
Kafka Connect facilitates integration with external systems such as databases, object stores, or other streaming platforms. It enables seamless ingestion or export of data to/from Kafka topics.
3. Streaming SQL Engines
Several tools enable Streaming SQL on Kafka, including:
- ksqlDB: A Kafka-native streaming SQL engine built on Kafka Streams.
- Apache Flink SQL: A versatile stream-processing framework with advanced SQL capabilities.
- Apache Beam: Provides SQL for batch and stream processing, compatible with various runners.
- Spark Structured Streaming: Supports SQL for real-time and batch data processing.
How Does Streaming SQL Work?
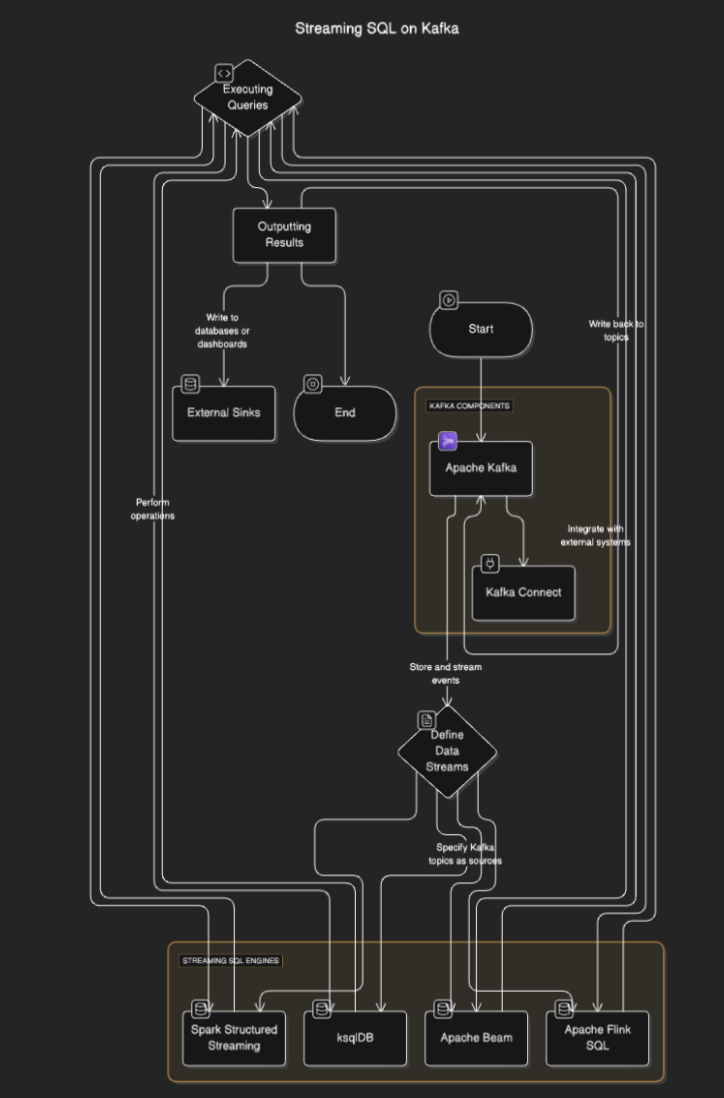
Streaming SQL engines connect to Kafka to read data from topics, process it in real time, and output results to other topics, databases, or external systems. The process typically involves the following steps:
- Defining data streams: Users define streams or tables by specifying Kafka topics as sources.
- Executing queries: SQL queries are executed to perform operations like filtering, aggregation, and joining streams.
- Outputting results: The results can be written back to Kafka topics or external sinks like databases or dashboards.
Flow Diagram
Streaming SQL Tools for Kafka
ksqlDB
ksqlDB is purpose-built for Kafka and provides a SQL interface to process Kafka topics. It simplifies operations like filtering messages, joining streams, and aggregating data. Key features include:
- Declarative SQL Queries: Define real-time transformations without coding.
- Materialized Views: Persist query results for fast lookups.
- Kafka-Native: Optimized for low-latency processing.
Example:
CREATE STREAM purchases (
user_id VARCHAR,
item_id VARCHAR,
amount DECIMAL
) WITH (
KAFKA_TOPIC='purchases_topic',
VALUE_FORMAT='JSON'
);
CREATE STREAM high_value_purchases AS
SELECT *
FROM purchases
WHERE amount > 100;
Apache Flink SQL
Apache Flink is a powerful stream-processing framework that provides SQL capabilities for both batch and streaming data. It supports complex operations like event-time processing and advanced windowing.
Example:
CREATE TABLE purchases (
user_id STRING,
amount DECIMAL,
purchase_time TIMESTAMP(3),
WATERMARK FOR purchase_time AS purchase_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'purchases_topic',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset'
);
SELECT user_id, COUNT(*) AS purchase_count
FROM purchases
GROUP BY user_id;
Apache Spark Structured Streaming
Spark Structured Streaming enables SQL-based stream processing and integrates well with other Spark components. It’s ideal for complex data pipelines combining batch and stream processing.
Example:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("StreamingSQL").getOrCreate()
# Read Kafka topic as a stream
df = spark.readStream.format("kafka").option("subscribe", "purchases_topic").load()
# Perform SQL-like transformations
df.selectExpr("CAST(value AS STRING)").createOrReplaceTempView("purchases")
query = spark.sql("SELECT user_id, COUNT(*) AS purchase_count FROM purchases GROUP BY user_id")
query.writeStream.format("console").start()
Use Cases for Streaming SQL on Kafka
- Real-time analytics. Monitor user activity, sales, or IoT sensor data with live dashboards.
- Data transformation. Cleanse, filter, or enrich data as it flows through Kafka topics.
- Fraud detection. Identify suspicious transactions or patterns in real time.
- Dynamic alerts. Trigger alerts when specific thresholds or conditions are met.
- Data pipeline enrichment. Join streams with external datasets to create enriched data outputs
Benefits of Streaming SQL on Kafka
- Simplified development. SQL is familiar to many developers, reducing the learning curve.
- Real-time processing. Enables immediate insights and actions on streaming data.
- Scalability. Leveraging Kafka’s distributed architecture ensures scalability.
- Integration. Easily integrates with existing Kafka-based pipelines.
Challenges and Considerations
- State management. Complex queries may require managing large states, which could impact performance.
- Query optimization. Ensure queries are efficient to handle high-throughput streams.
- Tool selection. Choose the right SQL engine based on your requirements (e.g., latency, complexity).
- Fault tolerance. Streaming SQL engines must handle node failures and ensure data consistency.
Conclusion
Streaming SQL on Kafka empowers businesses to harness real-time data with the simplicity of SQL. Tools like ksqlDB, Apache Flink, and Spark Structured Streaming make it possible to build robust, scalable, and low-latency data pipelines without deep programming expertise.
Opinions expressed by DZone contributors are their own.
Comments