Evaluating Accuracy in RAG Applications: A Guide to Automated Evaluation
RAG improves GenAI accuracy with external context retrieval; key metrics and automated checks ensure high-quality, reliable results.
Join the DZone community and get the full member experience.
Join For FreeGenerative AI applications are rapidly gaining momentum across industries, providing intelligent responses to a wide range of queries. Whether for customer support, content generation, or knowledge management, the ability of AI to deliver contextually relevant and accurate answers is critical. One powerful approach that has emerged is Retrieval-Augmented Generation (RAG), which integrates large language models (LLMs) with external knowledge sources to enhance the quality of AI-generated responses. The retrieval component draws on external databases to provide real-world information, while the generation component refines the content into human-like responses.
RAG’s usefulness lies in its ability to extend the capabilities of traditional language models, making them more context-aware and accurate. Applications of RAG span across multiple industries: for example, in customer support, RAG models dynamically access knowledge bases to deliver real-time, accurate answers to inquiries, reducing the need for manual intervention. In corporate environments, RAG helps automate information retrieval from large document repositories, improving response accuracy in knowledge-sharing platforms. It also plays a crucial role in fields like healthcare and education, where it enhances decision-making by fetching relevant research papers or educational materials, which LLMs can summarize for easy understanding.
A key advantage of RAG is its ability to reduce hallucination—when AI generates inaccurate or invented information—by grounding responses in verified knowledge sources. This leads to more factual and reliable outputs, making AI applications more trustworthy and efficient. However, as RAG models combine the complex processes of retrieval and generation, evaluating their accuracy presents unique challenges. In real-world applications, ensuring consistent, reliable accuracy is crucial to maintain user trust and efficiency. Therefore, automating the evaluation of RAG applications can lead to continuous performance monitoring and improvement, making it an essential part of the development process.
What Is Retrieval-Augmented Generation (RAG)?
RAG is an advanced approach that leverages the strengths of two distinct AI capabilities: retrieval and generation. In simple terms, RAG models combine a pre-trained language model with a retrieval mechanism that connects the model to external knowledge sources, such as documents, databases, or APIs. This architecture enables the model to generate more precise and contextually informed responses than a standalone LLM.
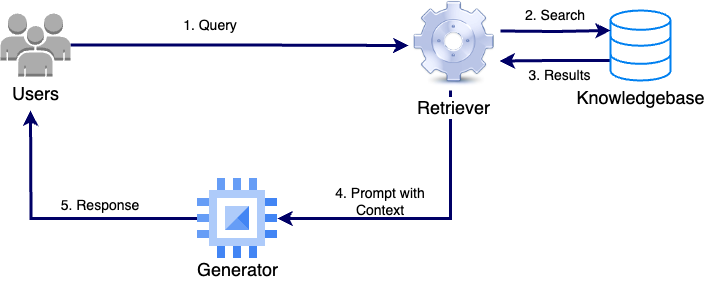
RAG contains two components:
- Retriever component: The retriever component searches external knowledge sources and returns information relevant to the user's query. Techniques like semantic similarity matching or keyword-based search are employed to ensure the returned information is relevant and accurate.
- Generator component: Once the relevant information is retrieved, the generation module processes this information, embedding it into natural language responses that are coherent, contextually appropriate, and human-like.
By augmenting LLMs with retrieval capabilities, RAG models deliver content that not only reflects the linguistic expertise of the model but also pulls in real-time, up-to-date, or domain-specific knowledge to provide factually grounded outputs.
Evaluating RAG Application Accuracy
Evaluating the accuracy of a RAG application is a multifaceted task because its overall performance depends on both the retrieval and generation modules, each of which must be assessed individually. The retrieval component sources relevant, factual information from external databases, while the generation module transforms it into coherent, context-aware responses. As a result, a holistic evaluation of a RAG application must consider both the quality of the retrieved data and how effectively the language model incorporates that data into its outputs.
The RAGAS tool offers a comprehensive set of metrics designed to evaluate various aspects of RAG applications. However, not all metrics will be relevant for every use case, as different RAG applications prioritize different performance criteria. For instance, when RAG is utilized to retrieve documentation about a programming language and provide code suggestions, the evaluation criteria should focus on whether the retrieved code includes relevant keywords, such as expected libraries, and whether the overall code is compilable and syntactically correct. Conversely, in an interactive chatbot or product assistant setup, the evaluation should emphasize the factuality of the responses and the relevance of the answers to user queries. This illustrates how the specific use case dictates the selection of metrics, ensuring that the evaluation process aligns with the unique objectives and requirements of each RAG application.
In the context of our case study, we have carefully chosen the most suitable metrics to evaluate based on the unique requirements of our application. These metrics not only reflect the specific tasks the RAG system is intended to perform but also focus on the key performance indicators that will have the greatest impact on the end-users. By selecting the appropriate metrics, we can ensure that our evaluation is focused on the most relevant aspects of performance, leading to targeted improvements and better outcomes for the application’s users. We will provide a detailed explanation of each metric chosen for the case study, offering insight into how they apply to our specific use case and why they are the most relevant metrics for evaluating the effectiveness of the RAG system..
Some terms to be familiar before diving into the metrics.
- Question – The input query from the user to the RAG system.
- Context – Documents retrieved by the retriever from the knowledge base.
- Answer – The response generated by the RAG system using the retrieved context.
Ground Truth (GT) – The correct answer manually annotated for the user’s question.
The performance of the retriever must be analyzed using the following metrics to determine whether it has successfully retrieved the appropriate context:
-
Context Recall measures how well the retrieved context captures the information found in the Ground Truth (GT) answer. High context recall means that all claims present in the GT should also be found within the retrieved context. Incorrect context being retrieved will result in low context recall.
![Context recall formula]()
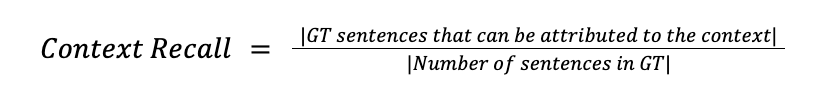
Context recall metric can be controlled by tuning hyper parameters such as vector database indexing strategy, embedding model and similarity search algorithm.
-
Context Precision evaluates whether all the ground-truth relevant items present in the contexts are ranked higher or not. Higher the rank of the most relevant document in the context, will result in higher context precision.
![Context precision formula]()
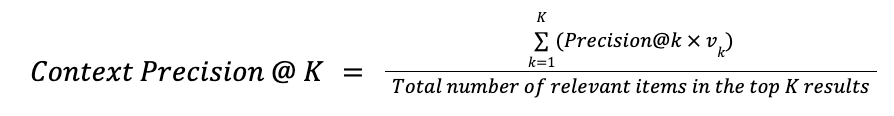
Where K is the total number of docs in the contexts and vk {0,1} is the relevance indicator at rank k.

The context precision metric can be improved by introducing a re-ranker to rank the retrieved context according to the relevance to the question.
Once the retriever has provided the context, the performance of the generator must be analyzed using the following metrics to determine whether the generated response is factually correct and semantically similar to the expected response:
-
Faithfulness measures the factual consistency of the generated answer against the given context. If any sentence has been hallucinated in the generated answer, then the faithfulness score will be low as that sentence is not available in the retrieved context.
![Faithfulness score formula]()
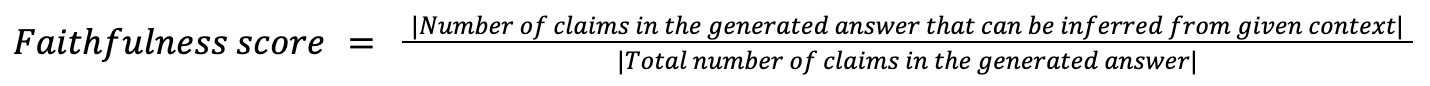
Faithfulness metric can be controlled through prompt engineering and tuning the temperature of the LLM.
-
Answer Semantic Similarity compares the generated answer with the GT answer, assessing how well the output aligns in semantic meaning with the expected response. Both the GT and generated answer will be vectorized through the embeddings model and the cosine similarity will be calculated.
Answer semantic similarity metric can be controlled by incorporating proper prompt engineering techniques.
These metrics offer a comprehensive evaluation of the hybrid retrieval-generation nature of RAG. Fine-tuning both the retriever and generator components based on these metrics is crucial for improving the accuracy and reliability of the overall system.
Automating RAG Application Accuracy Evaluation
Given the complexity of RAG models, manually evaluating their performance on a large scale is time-consuming and prone to inconsistencies. Automating the evaluation process can significantly streamline this task, making it easier to monitor performance over time and identify areas for improvement.
In a typical software development process, developers write code and create unit tests to validate functionality. These tests are often integrated into a continuous integration/continuous deployment (CI/CD) pipeline, allowing automated checks to occur after each code change. GitHub workflows serve as one of the mechanisms to trigger these automated processes. However, other tools, such as Jenkins, Azure pipeline, or GitLab CI, can also facilitate similar workflows. Our aim is to apply this same principle to the accuracy evaluation of RAG applications.
Building an automated pipeline for accuracy evaluation typically involves several key steps:
- Dataset Preparation: Before evaluation can begin, a well-structured dataset is essential. This dataset should include a representative sample of inputs and expected outputs, allowing for meaningful comparisons. The preparation may involve curating documents, code snippets, or user queries, along with their corresponding ideal responses, ensuring that the evaluation accurately reflects real-world usage.
- Metric Computation: Once the dataset is prepared, evaluation scripts are set up to compute the key metrics relevant to the RAG application. These metrics may include precision, recall, response time, factual accuracy, and relevance, depending on the specific use case.
- Integration with CI/CD Pipelines: By integrating the evaluation scripts with a CI/CD pipeline, automated evaluations can be triggered after every code update, such as GitHub pull requests or model retraining sessions. This ensures continuous monitoring of model accuracy and can flag potential regressions early in the development cycle.
- Result Reporting: The pipeline automates data input, metric computation, and result reporting, providing developers with detailed insights into the application’s performance without manual intervention. These insights can inform decision-making and guide further development efforts.
By automating the accuracy evaluation of RAG applications, we can create a more streamlined workflow where continuous evaluation occurs without significant human oversight. This approach enables faster iterations and promotes more reliable performance over time, ensuring that RAG applications consistently meet the evolving needs of users.
Case Study: Automated Evaluation Pipeline for a Documentation Assistant
Background of the Case Study
In this case study, we’ll walk through building an automated evaluation pipeline for a documentation assistant that answers user questions about the Choreo platform, which is an internal developer platform (IDP). The code for the service can be found at https://github.com/Nirhoshan/docs-assistant-bot/. We utilize a RAG approach that integrates the Zilliz vector database, OpenAI models, and the Cohere Reranker.
- The knowledge base is created in the
Zillizvector database from the Choreo documentation. Cohere Rerankeris used to rerank the documents at the retrieval step.OpenAI text-embedding-3-smallis used for embeddings andGPT-4ois used for generation.
The knowledge base is created by running the data_index.py script. Then the documentation assistant service is created by running the generate_response.py script, which utilizes RAG underneath.
from langchain_community.vectorstores import Zilliz
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_cohere import CohereRerank
from fastapi import FastAPI, Body
app = FastAPI()
def invoke_retriever(question):
# This function will retrieve the docs and rerank them
return reranked_docs
def invoke_generator(question):
docs = invoke_retriever(question)
# This function will invoke the LLM with the user's question and the
# context retrieved from the knowledge base
return response
@app.post('/chat')
def chat(question: str = Body(..., embed=True)):
return invoke_generator(question)
The following image shows the service being invoked through Postman.
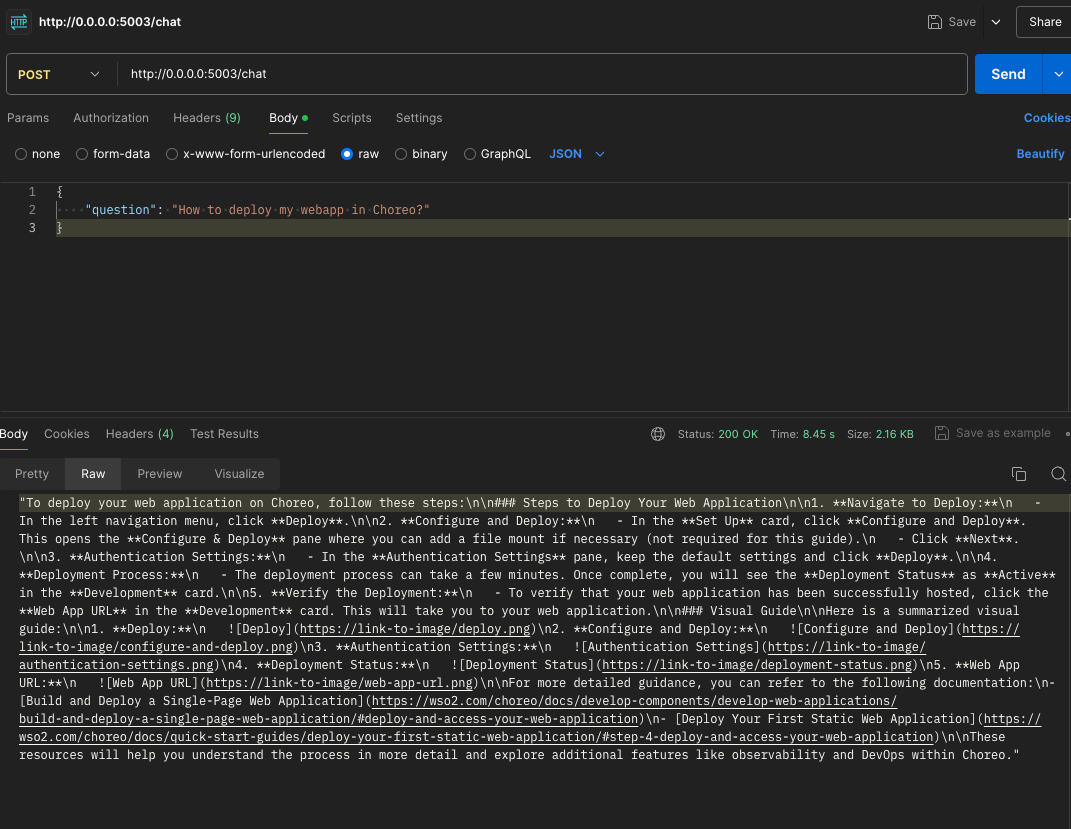
Now, let’s automate the accuracy evaluation for this service through the following steps.
Step 1: Designing the Evaluation Pipeline
The RAG-based assistant can be evaluated using the RAGAS library. The goal is to automate the evaluation process by measuring key metrics such as context recall, context precision, faithfulness, and answer similarity.
The testing dataset is stored in a CSV file that includes sample questions and their corresponding ground truth answers. The following code loads the test data, retrieves the relevant documents, generates answers, and evaluates them. Set RUN_ACCURACY_TEST to True in your environment variables list.
import csv
import logging
import sys
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import context_recall, context_precision, faithfulness, answer_similarity
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from generate_response import invoke_retriever, invoke_generator
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def load_data(filepath):
questions, ground_truths = [], []
with open(filepath, newline='') as csvfile:
reader = csv.reader(csvfile)
next(reader, None)
for row in reader:
questions.append(row[0])
ground_truths.append([row[1]])
return questions, ground_truths
def process_questions(questions):
answers, contexts = [], []
for question in questions:
answer = invoke_generator(question)
docs = invoke_retriever(question)
context = [(f"doc: {doc.page_content}.You can refer to this [document] "
f"({doc.metadata['ChoreoMetadata']['doc_link']}) for more details.") for doc in docs]
answers.append(answer)
contexts.append(context)
return questions, answers, contexts
def main():
# Initialize LLM and embeddings
llm = ChatOpenAI(model="gpt-4-turbo-2024-04-09", temperature=1e-8)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# Load and process data
questions, ground_truths = load_data('test_data/validation_dataset.csv')
questions, answers, contexts = process_questions(questions)
# Prepare dataset
data = {
"question": questions,
"answer": answers,
"contexts": contexts,
"ground_truths": ground_truths
}
dataset = Dataset.from_dict(data)
# Run evaluation
results = evaluate(
dataset=dataset,
metrics=[
context_precision,
context_recall,
faithfulness,
answer_similarity,
],
llm=llm,
embeddings=embeddings,
raise_exceptions=False
).to_pandas()
# Save results
results.to_csv('test_data/accuracy_results.csv', index=False)
# Define thresholds
thresholds = {
'context_precision': 0.95,
'context_recall': 0.90,
'faithfulness': 0.90,
'answer_similarity': 0.90
}
# Check metrics against thresholds
mean_scores = results[list(thresholds.keys())].mean()
failed_metrics = []
for metric, threshold in thresholds.items():
score = mean_scores[metric]
logger.info(f"{metric} average: {score:.2f} (threshold: {threshold})")
if score < threshold:
failed_metrics.append(f"{metric} ({score:.2f} < {threshold})")
# Exit with error if any metrics failed
if failed_metrics:
logger.error("Accuracy test failed for the following metrics:")
for metric in failed_metrics:
logger.error(f"- {metric}")
sys.exit(1)
else:
logger.info("All accuracy metrics passed!")
if __name__ == "__main__":
main()In this evaluation framework:
- The
CSVfile contains test queries and ground truth answers. - The system retrieves the relevant context (documents), generates answers, and evaluates the outputs.
- Metrics such as
context recallandcontext precisionevaluate the performance of the retriever, while metrics likefaithfulnessandanswer similarityassess the performance of the generator in a RAG-based system. - The results will be written to the
accuracy_results.csvfile. - Thresholds were set as follows:
0.95for context precision,0.90for context recall,0.90for faithfulness, and0.90for answer similarity. These thresholds ensure that the evaluation test will fail if the RAG system does not meet or exceed these specified values.
The image below shows a sample row from the output CSV file, highlighting the results for each metric.

Step 2: Automating the Evaluation in CI/CD Pipeline
In this step, we automate the accuracy evaluation as part of the CI/CD pipeline using GitHub Actions. This ensures that every change to the RAG-based assistant, such as updates to the document retrieval system or model, is automatically evaluated before deployment.
Setting Up the GitHub Workflow:
Create a workflow file at .github/workflows/ci.yml in your GitHub repository.
The workflow will:
- Add the required API keys and install the necessary dependencies to configure the environment.
- Run the evaluation script that tests the documentation assistant’s accuracy.
- Fail the build if the evaluation does not meet a certain accuracy threshold.
Here's how you can structure the GitHub Actions workflow:
name: Accuracy Check CI
on:
push:
branches:
- main
jobs:
accuracy-check:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.11'
- name: Install dependencies
run: |
sudo apt update
python3.11 -m pip install --upgrade pip setuptools wheel pyopenssl pytest
python3.11 -m pip install --no-cache-dir -r requirements.txt
- name: Run Accuracy Test
run: |
export PYTHONPATH="$(pwd)/docs-assistant-bot:$PYTHONPATH"
set -eo pipefail
python3.11 tests/test_accuracy.py
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
COHERE_API_KEY: ${{ secrets.COHERE_API_KEY }}
COLLECTION_NAME: ${{ vars.COLLECTION_NAME }}
ZILLIZ_CLOUD_API_KEY: ${{ secrets.ZILLIZ_CLOUD_API_KEY }}
ZILLIZ_CLOUD_URI: ${{ vars.ZILLIZ_CLOUD_URI }}
- name: Publish Accuracy Test Results
uses: actions/upload-artifact@v3
with:
name: AccuracyTestResults
path: 'test_data/accuracy_results.csv'
In this workflow:
- Environment variables such as API keys are securely stored in GitHub Secrets.
- The evaluation script is triggered every time there is a push to the
mainbranch or a pull request is created. - The evaluation results are compared against a predefined accuracy threshold. If the accuracy is below this threshold, the workflow fails, ensuring that any performance regressions are caught before the code is merged or deployed.
- The results will be stored in the artifacts of the workflow run.
The image below illustrates the accuracy test run for each commit.
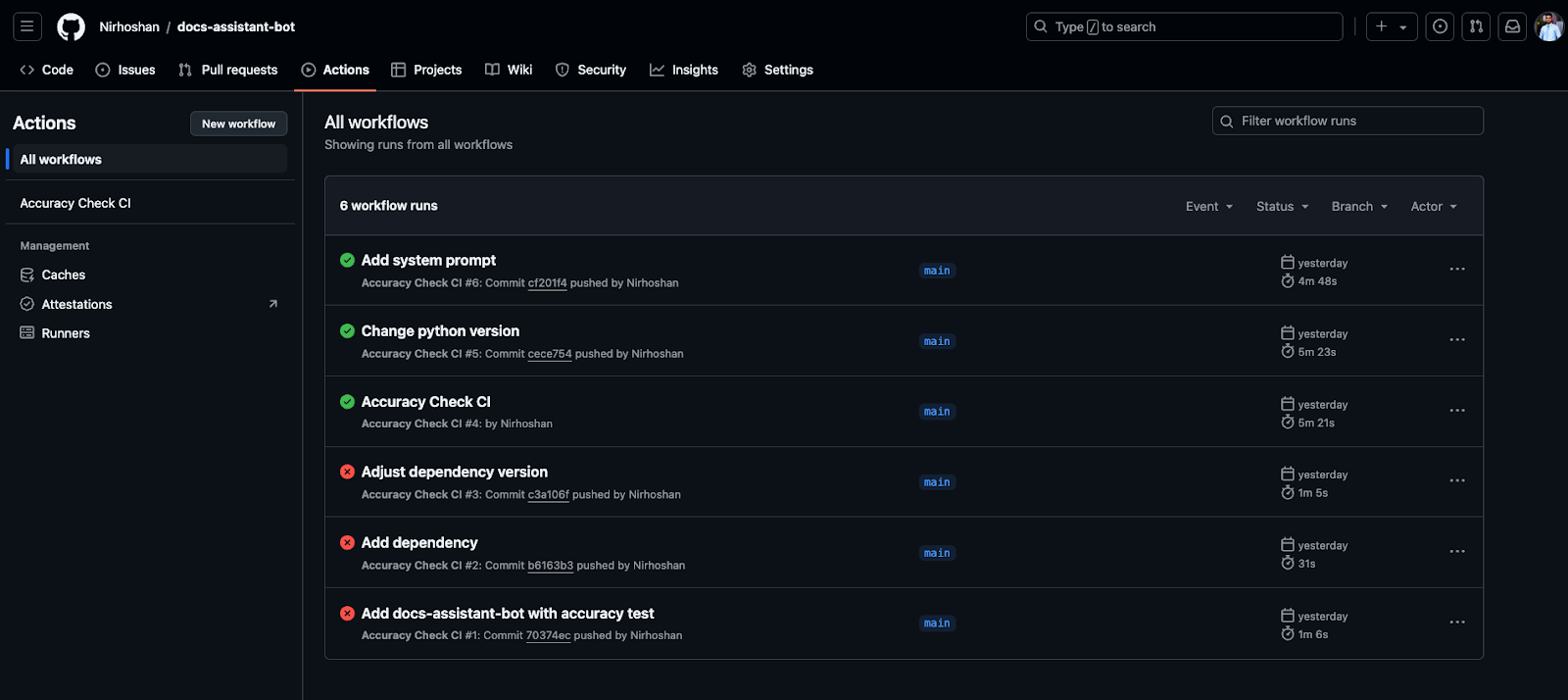
With Step 2, the evaluation process is fully automated within the CI/CD pipeline. This ensures continuous quality control of the RAG-based documentation assistant, providing developers with quick feedback on the system's performance after every update.
Conclusion
As RAG models continue to evolve and find applications across diverse industries, the need for accurate, context-aware AI responses has never been greater. To maintain output quality and reliability, it's essential to evaluate these models regularly and improve their performance.
By automating the accuracy evaluation process, developers can consistently monitor key performance indicators, fine-tune their systems, and ensure that their RAG applications deliver the highest level of accuracy. Automation not only reduces manual effort but also helps in streamlining continuous improvements, making RAG models more robust and effective for real-world use cases.
Key Takeaways
- RAG enhances Generative AI by integrating external knowledge sources, improving response accuracy and relevance.
- The retriever component identifies relevant knowledge from a knowledge base using methods like semantic similarity or keyword matching. The generator component produces content based on the context retrieved by the retriever, ensuring informed and coherent responses.The accuracy of a RAG application is directly influenced by the performance of both the retriever and generator components.
- Context recall evaluates whether the most relevant context has been retrieved, while context precision assesses if the most relevant context has the highest similarity score. These metrics focus on the performance of the retriever component. On the other hand, answer semantic similarity, which measures the semantic closeness to the ground truth, and faithfulness, which checks for factual consistency, evaluate the generator component.
- Automating accuracy evaluation is crucial for consistently monitoring and improving the performance of RAG applications.
- Any improvements made to the RAG application by developers must maintain the accuracy standards set by the enterprise, ensuring that no changes are released to production unless these standards are upheld.
References
[1] Es, S., James, J., Espinosa-Anke, L., & Schockaert, S. (2023). RAGAs: Automated Evaluation of Retrieval Augmented Generation. arXiv preprint arXiv:2309.15217.
Opinions expressed by DZone contributors are their own.
Comments