RAG on Android Done Right: Local Vector Cache Plus Cloud Retrieval Architecture
Most mobile RAG fails on latency and flaky networks. A local vector cache + cloud retrieval architecture keeps responses fast, fresh, and grounded.
Join the DZone community and get the full member experience.
Join For FreeWhy “Classic RAG” Breaks on Android
On paper, retrieval-augmented generation is straightforward: embed the query, retrieve the top chunks, stuff them into a prompt, and generate an answer with citations. On Android, that “classic” flow runs into real constraints:
- Latency budgets are tight. Users feel delays instantly, especially inside chat-like UIs.
- Networks are unreliable. RAG becomes brittle when your retrieval depends on a perfect connection.
- Privacy expectations are higher. Users assume mobile experiences are local-first, especially for enterprise or personal data.
- Resources are limited. Battery, memory, and storage don’t tolerate “just cache everything.”
- Cold start is unforgiving. If the first answer is slow or wrong, you lose trust quickly.
So the goal isn’t “RAG everywhere.” The goal is first to find a helpful answer quickly, then to upgrade the grounding when the cloud is available. That’s exactly what a two-tier system provides.
The Reference Architecture
The most reliable mobile RAG setup uses two retrieval tiers and treats the cloud like an upgrade, not a dependency.
Client (Android)
- Query Orchestrator: Runs local + cloud retrieval concurrently and merges results.
- Local Vector Cache (Room/SQLite): A small “hot set” of chunk embeddings and text.
- Lightweight Similarity Search: Exact cosine similarity over a small N (cheap and good enough).
- Prompt Builder: Strict schema, citations, and token budgeting.
- Gateway Client: Calls your server gateway (avoid direct model calls from the app).
- Background Sync (WorkManager): Keeps the cache warm using pinned/popular content.
Server
- AI Gateway: Auth, redaction, rate limits, model routing, and trace logging.
- Vector Search + Chunk Store: Canonical chunks with versions, enforced tenant isolation.
- Optional Reranker: Improves quality for top candidates (cross-encoder or LLM rerank).
This architecture gives you speed and resilience locally, plus freshness and recall from the cloud.
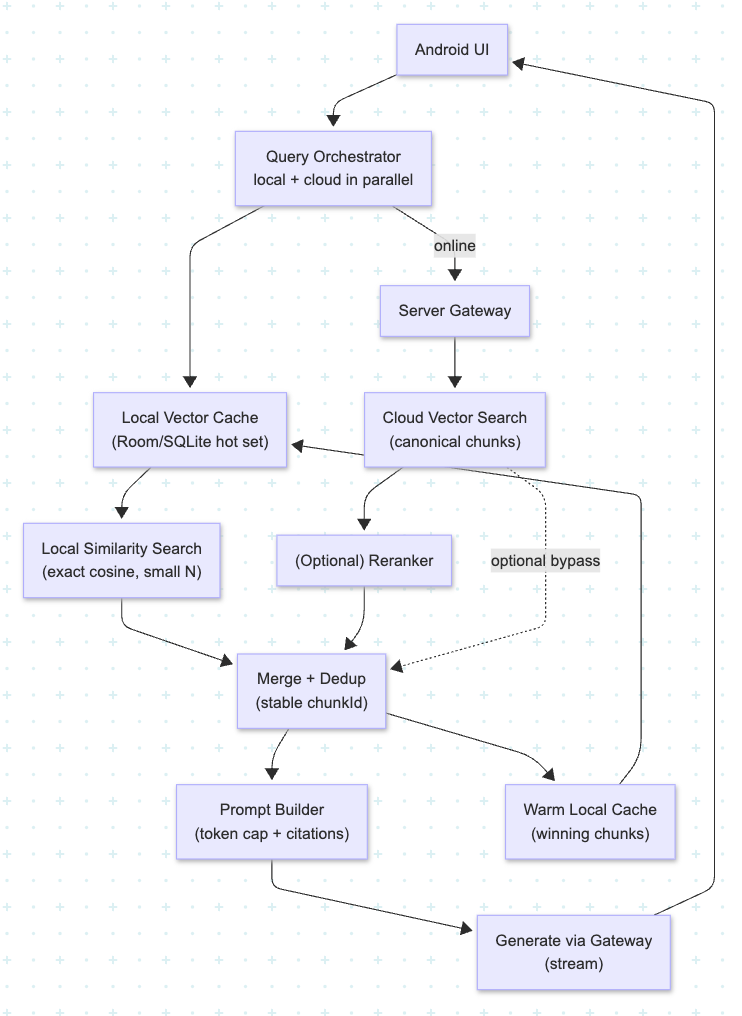
The Hybrid Retrieval Flow (Local-First, Cloud Upgrade)
A practical request flow looks like this:
- Normalize the query (trim, de-noise, remove obvious UI fluff).
- Start local retrieval immediately to get the top 3–5 chunks fast.
- In parallel, attempt cloud retrieval if the device is online.
- Merge + de-duplicate results using a stable
chunkId. - Rerank using cheap heuristics; optionally, rerank top N with a stronger model.
- Build a strict prompt with short excerpts and forced citations.
- Generate via the gateway and stream to the UI.
- Warm the local cache with winning chunks for the next similar query.
The “secret” is concurrency: local retrieval gives you speed; cloud retrieval improves accuracy when available. Your UI can show a grounded answer quickly, then refine it if the cloud finds better sources.
Local Vector Cache: Keep It Small and Versioned
The local cache is not your full knowledge base. It’s a curated hot set.
What to Cache Locally
- Essential FAQs/product guides/help center snippets
- Recently used or recently retrieved “winning” chunks (semantic warming)
- Pinned documents per user/org (enterprise-friendly)
Size Guidance
Most apps do great with 500–2,000 chunks locally. With that scale, exact cosine similarity is cheap enough and avoids pulling in heavyweight on-device vector databases.
Fields That Matter
Store enough metadata to prevent silent staleness:
chunkId,docId,title,chunkTextembedding,embeddingDimnamespace(tenant/org/user scope)docVersionembeddingModelVersionexpiresAt(TTL)
Invalidation Rules (Non-Negotiable)
Invalidate cached chunks if:
docVersionchangesembeddingModelVersionchanges- TTL expires
- namespace/tenant scope changes
Stale caches are the fastest path to “confidently wrong” outputs.
Kotlin Skeleton (Room + Hybrid Retriever)
Below is a minimal pattern you can ship. It’s intentionally simple: keep the cache small, do exact similarity, and merge with cloud results.
@Entity(tableName = "rag_chunks")
data class RagChunkEntity(
@PrimaryKey val chunkId: String,
val namespace: String,
val docId: String,
val title: String,
val chunkText: String,
val embeddingBlob: ByteArray,
val embeddingDim: Int,
val docVersion: Long,
val embeddingModelVersion: String,
val expiresAtEpochMs: Long
)
class RagRetriever(
private val dao: RagChunkDao,
private val cloud: CloudRagApi,
private val embedder: QueryEmbedder,
private val network: NetworkChecker
) {
suspend fun retrieve(ns: String, query: String, modelVer: String): List<RagChunk> =
coroutineScope {
val now = System.currentTimeMillis()
val q = QueryNorm.normalize(query)
val embDeferred = async { embedder.embed(q) }
val localDeferred = async {
val emb = embDeferred.await()
dao.loadValid(ns, modelVer, now)
.asSequence()
.map { it.toDomain(score = Similarity.cosine(emb, it), source = "local") }
.sortedByDescending { it.score }
.take(5)
.toList()
}
val cloudDeferred = async {
if (!network.isOnline()) emptyList()
else cloud.search(ns, q, embDeferred.await(), topK = 8)
}
(localDeferred.await() + cloudDeferred.await())
.groupBy { it.chunkId }
.map { (_, items) -> items.maxBy { it.score } }
.sortedByDescending { it.score }
.take(8)
}
}
This gives you:
- fast local hits under typical conditions
- cloud “upgrade” when online
- deterministic merge behavior via stable IDs
Prompting Rules That Keep RAG Honest
RAG fails less because of “bad models” and more because of loose prompting. A few rules make a huge difference:
- Cap retrieved chunks (usually 6–10 max).
- Include short excerpts (not full pages).
- Always include
chunkIdandtitleand require the model to cite them (e.g.,[chunkId]). - Add explicit refusal behavior: if the sources don’t contain the answer, say you can’t confirm.
This prevents the model from “filling gaps” when retrieval is weak.
Production Guardrails
Security/Privacy
- Enforce namespace isolation in cloud vector search (tenant-safe by design).
- Allowlist from which a given feature can be retrieved.
- Redact common sensitive fields before cloud calls (emails, phones, IDs).
- Log chunk IDs and versions, not raw chunk text.
Observability
Track:
- latency breakdown (local retrieval, cloud retrieval, generation)
- local hit rate vs. cloud upgrade rate
- empty retrieval rate
- citation coverage rate
- docVersion mismatch/staleness incidents
If you can’t answer “which chunk led to this output?”, debugging becomes guesswork.
Takeaways
RAG feels “native” on Android when you stop treating retrieval as a single cloud dependency and instead build a two-tier system:
- Local vector cache for speed, resilience, and privacy
- Cloud retrieval for freshness and recall
- Versioned caching + TTL to prevent stale answers
- Strict citations + refusal behavior to keep outputs grounded
- Basic observability to iterate confidently
That’s the architecture that turns RAG from a demo into a feature users trust.
Opinions expressed by DZone contributors are their own.
Comments