Why Stable RAG Answers Can Still Hide Unstable Evidence
RAG answers can stay stable while evidence shifts. Learn why evidence stability matters for reproducibility, auditability, and debugging — and how to check it.
Join the DZone community and get the full member experience.
Join For FreeMost RAG evaluations focus on the answer.
- Is the answer correct?
- Does it appear grounded?
- Did retrieval metrics improve after a pipeline change?
Those checks are useful. But they do not tell the full story.
Two runs can produce nearly the same answer while relying on different supporting evidence. A small change in chunking, retrieval depth, overlap, or reranking may leave the output looking stable on the surface. Underneath, the cited documents or spans may have changed.
Once that happens, reproducibility and auditability become weaker. Another engineer may not be able to reproduce the same support trail. A reviewer may not be able to explain why the system relied on one source in one run and a different source in another.
What Gets Missed
In many teams, the workflow is simple.
- Change the retriever. Run the benchmark.
- Change chunk size. Run the benchmark.
- Compare answer quality, faithfulness, latency.
If the answer still looks fine, the change is treated as safe. But a system can keep giving roughly the same answer while quietly shifting its evidence. That weakens debugging, regression analysis, and traceability.
A Simple Example
Take an internal HR assistant. A user asks: How many days per week can hybrid employees work remotely?
Run A
The assistant answers: Hybrid employees may work remotely up to three days per week.
It cites:
HR_Policy_2024.pdfRemote_Work_FAQ.pdf
Run B
After a retrieval configuration change, the assistant gives almost the same answer: Hybrid employees may work remotely up to three days per week.
But now it cites:
Manager_Guidelines.pdfTeam_Handbook.pdf
The answer barely moved. But the evidence did.
That changes the review question. It is no longer only about whether the answer sounds reasonable. It becomes which source the system treated as authority, and why that changed.
- Did it move from policy to guidance?
- Did it move from a formal source to a looser one?
- Would HR or Legal accept both?
- Could the team explain the shift if they had to?
That is where evidence stability stops feeling academic and starts looking operational.
The Subtler Case
There is another version of the same problem. Sometimes the system keeps citing the same document, but the cited span inside that document changes.
At the document level, it looks stable. At the span level, it may not be stable at all.
That matters because two spans from the same document can play very different roles. One may contain the rule. Another may contain context, an exception, or a weaker explanation. A document-level check can say nothing changed while the actual justification shifted in a meaningful way.
So, How Do You Check It?
At that point, the obvious question is: how do you check this in a repeatable way?
That is what pushed me to build RagCiteCheck. It is a post-hoc checker for evidence stability. Feed it retrieval logs from different runs, and it compares what came back at the document level and at the span level when span hashes are available.
It is not trying to replace answer scoring or retrieval benchmarking. It answers a narrower question: Did the evidence stay stable across runs?
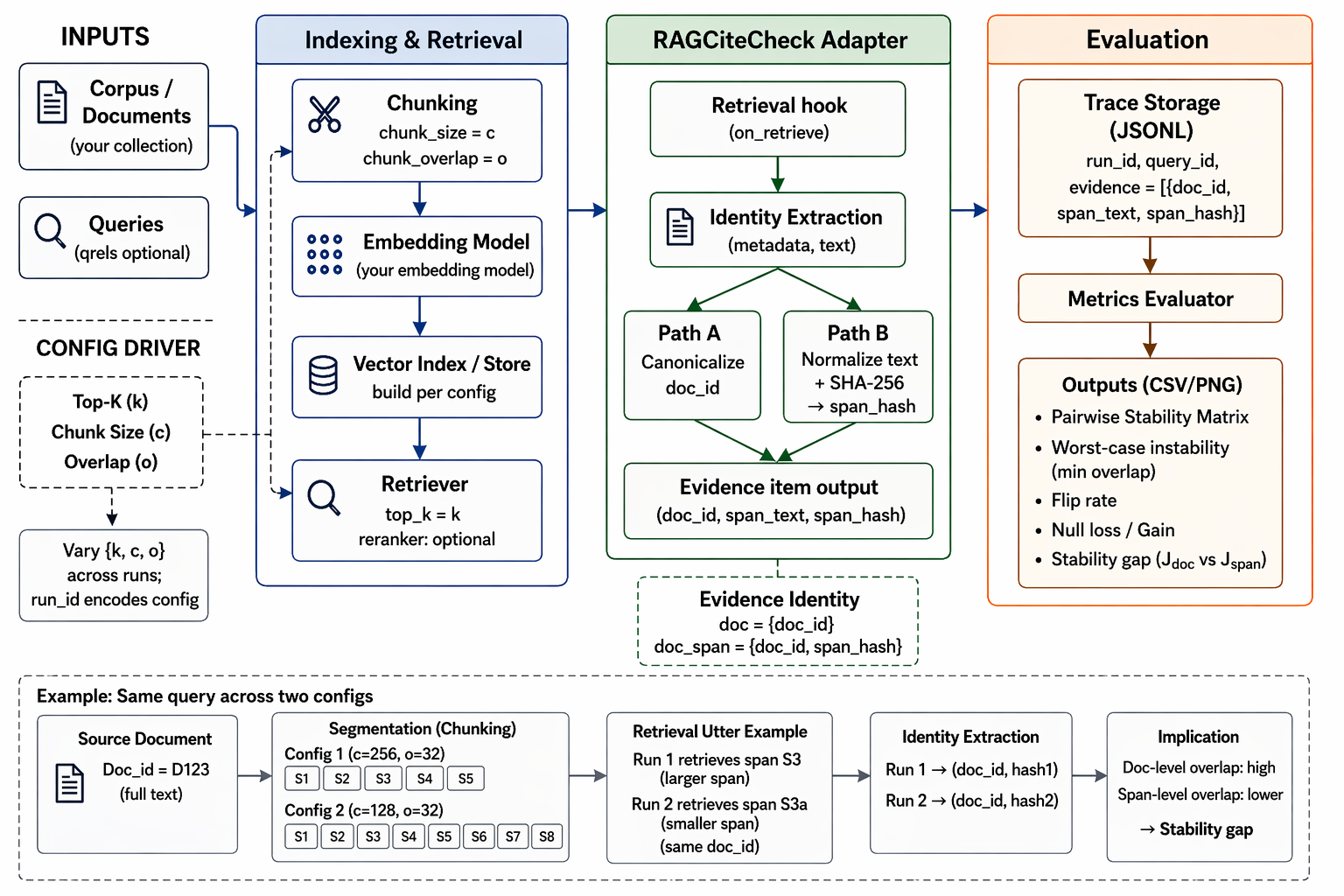
The workflow is small.
- Run your pipeline a few times.
- Change one retrieval setting each time.
- Save what came back.
- Compare.
A simple CLI flow is enough.
Validate the logs:
python -m ragcitecheck.cli validate --runs ./examples/minimal --out ./out_checkGenerate a document-level report:
python -m ragcitecheck.cli report --runs ./examples/minimal --out ./out_report_doc --evidence-key docGenerate a document-plus-span-level report:
python -m ragcitecheck.cli report --runs ./examples/minimal --out ./out_report_span --evidence-key doc_spanYou get a quick view of:
- How similar the runs are
- Which queries behave inconsistently
- Where most of the movement is happening
What You Start Noticing
Once you look at evidence across runs, the same patterns keep showing up.
- The answer stays similar, but the cited documents change
- The document stays the same, but the cited span changes
- Some queries remain stable while others keep shifting
- Small retrieval tweaks have larger effects than expected
None of that is obvious if you only compare answers.
Why It’s Worth Checking
If a team says a RAG workflow is reproducible, that should mean more than the answer looked similar again. It should also mean the support trail can be rerun, inspected, and compared.
If a team says a RAG system is auditable, that should mean more than the answer came with citations. It should also mean the cited basis does not quietly shift under routine pipeline changes without anyone noticing.
That is the value of checking evidence stability. It gives teams a way to inspect changes that would otherwise stay hidden behind stable-looking answers.
Final Thought
Most teams already compare answers across runs. They should compare the evidence, too. Because sometimes the answer did not change. But the evidence did.
Opinions expressed by DZone contributors are their own.
Comments