Rapid Prototyping for Multimodal AI Agents in Enterprise Collaboration
Prompt-to-prototype multimodal agents fast; validate voice and text flows, trust/recovery, and multi-agent orchestration early to cut rework for dev teams.
Join the DZone community and get the full member experience.
Join For FreeGartner's latest research paints a striking picture: 40% of enterprise applications will have task-specific AI agents by 2026. Right now, we're at 5%. That's not gradual adoption. That's a landslide. And yet McKinsey found that while 88% of enterprises have AI running somewhere in their operations, only 6% are seeing real financial returns across the business. Everyone's adopting. Almost no one's scaling. The bottleneck isn't technology anymore. It's figuring out whether what you're building actually works for the people who have to use it.
The Validation Gap Nobody Talks About
The pitch sounds great: AI that joins your meetings, transcribes everything, writes up the recap, and flags who owes what to whom. Some of these tools even jump in when the conversation stalls. Technically, it's remarkable work. But here's what gets glossed over in product demos: this isn't software that behaves the way software usually behaves. You can ask the same thing twice and get different answers both times. That's not a bug. That's how language models function.
Now layer on the reality that users don't stick to one interaction mode. Someone asks a question out loud during a call, follows up in the chat window ten minutes later, then reviews whatever the AI produced in a shared doc the next morning. Gartner expects 40% of generative AI to be multimodal by 2027, handling voice, text, images, and video in the same system. Traditional UX playbooks weren't written for this.
You can't figure out if users feel that continuity when switching from voice to text by staring at wireframes. They need something real in their hands. That's where prompt-to-prototype tools change the game. Build a working voice agent interface in an afternoon, put it in front of real users, watch what confuses them, fix it, repeat. All before anyone writes production code. The feedback loop that used to take months now takes days.
What Prompt-to-Prototype Actually Looks Like
Most people miss what makes these tools different: they're not just faster wireframes. They generate functional interfaces from plain language descriptions. You can spin up a working chatbot, hook it to voice input, and even simulate multi-user interactions. No production backend required.
Think about what that means for a team building voice AI into their product. The old way? Months of API integration, frontend work, and backend plumbing before a single user touches the thing. By then, your core assumptions about how people want to interact with it are baked in. Changing direction gets expensive fast.
The new way flips that sequence. Meeting assistant prototypes can come together in a single afternoon. Voice input, text responses, simulated AI behaviors, the works. Real users test it the same week. And what they tell you almost never matches what you expected.
One pattern keeps showing up: people need the AI to acknowledge when they've switched channels. Moving from voice during a meeting to text afterward, they want some signal that the system remembers the earlier conversation. Without it, the whole experience feels broken. Even when the AI technically has full context, users don't trust that it does. That insight never would have surfaced from a spec document.
Speed Isn't Optional Anymore
Forrester called agentic AI a top emerging technology for 2025, and their message was blunt: organizations won't be experimenting by year's end. They'll be racing to keep pace or falling behind. That pressure hits hard if you're building voice AI for enterprise collaboration.
The teams winning right now share one thing: they've figured out how to shrink the gap between "we think this will work" and "we know this works because we watched people use it." McKinsey's research backs this up: structured implementation approaches lead to 40% higher success rates than teams that wing it.
Voice AI demands answers that only real usage can provide. What's the longest pause users will tolerate before the AI responds? Around 800 milliseconds for voice, but people wait two or three seconds for text without complaint. What happens when the AI misunderstands someone in front of their colleagues during a meeting? That's a trust problem with consequences. How do you rebuild confidence after a mistake? These aren't questions you can theorize about. You have to watch it happen.
Multi-Agent Systems Make Everything Harder
The next wave is already arriving. Instead of one AI assistant doing everything, platforms are moving toward specialized agents working together. One handles transcription. Another tracks tasks and follow-ups. A third keeps discussions on track. Gartner's roadmap shows collaborative agents within applications by 2027, then multi-agent ecosystems spanning multiple tools by 2029.
This creates UX problems without established solutions. How does someone know which agent handles what? What do they do when two agents give conflicting information? When there's no single AI to evaluate, how does trust even work?
Prototyping remains the only reliable way to get traction on these questions. Build a quick simulation with multiple agents operating at once. Watch where people get confused. Figure out what makes the boundaries clear versus invisible. A week of testing teaches more than months of architectural planning.
Also read: Why State Management Is the #1 Challenge for Agentic AI
Building Trust Through Iteration
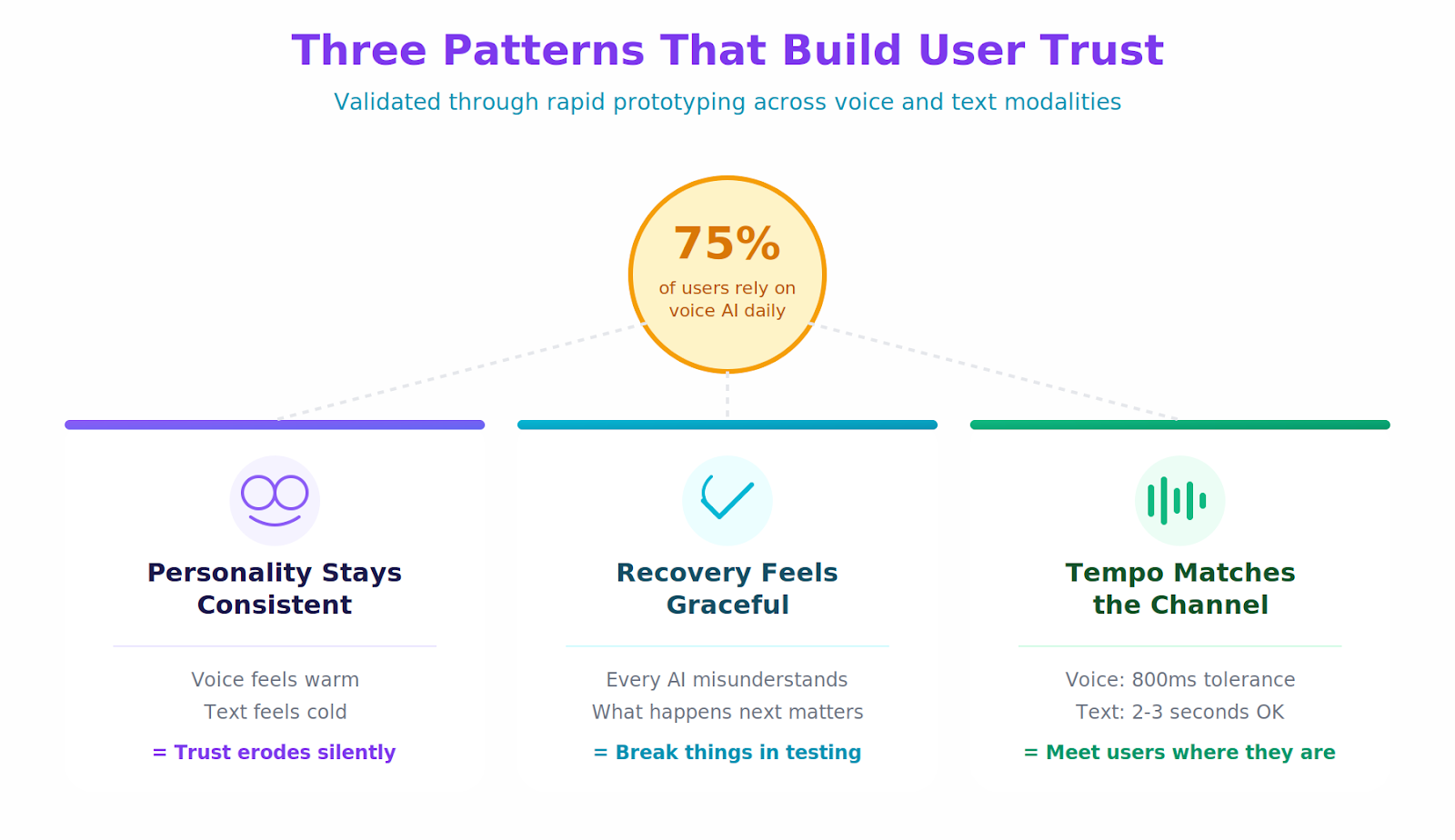
Research shows that 75% of people already use voice-based AI for daily tasks. But enterprise contexts raise the stakes. Getting the answers right is table stakes. The harder problem is trust. Will someone share a confidential strategy in front of this thing? Will they worry it might say something weird when their VP is on the call? Do they believe it's the same AI whether they're talking out loud or typing in a chat box? Those questions don't show up in accuracy benchmarks.
The following patterns prove reliable across prototypes:
- Personality stays consistent. People attribute more warmth and intelligence to voice interfaces than to text. When the same system feels friendly out loud but cold in chat, something registers as off. They might not articulate it, but trust erodes. Testing both modalities with the same users catches this early.
- Recovery has to feel graceful. Every voice AI will misunderstand something. The question is what happens next. Some recovery approaches rebuild trust. Others destroy it. The only way to know which is which: deliberately break things during testing and watch how people react.
- Tempo needs to match the channel. Voice conversations move fast. Text exchanges are slower and more deliberate. When someone switches from voice to text, their expectations don't reset immediately. They're still in conversation mode. The AI needs to meet them there before settling into a different rhythm.
What This Looks Like in Practice
Abstract principles only get you so far. Here's how prompt-to-prototype methodology plays out in real scenarios.
Testing when to speak up. A team wanted their AI to help guide brainstorming sessions by summarizing threads and suggesting topic changes. The critical question: when should it jump in? They prototyped three versions in an afternoon. One is interrupted after every speaker. One waited for natural pauses. One only spoke when someone asked directly. A week of testing revealed people preferred the pause-based approach, but wanted some visual cue showing the AI was preparing to contribute. That insight came before any backend work started.
Also read: Using AI to Augment Customer Service Agents
Validating channel switches. A platform planned to let users start voice conversations during calls and continue them via text afterward. Would seamless continuity feel natural, or strange, without some acknowledgment? They tested both. Version A just continued in text. Version B opened with a brief reference to the earlier voice exchange. Users kept re-explaining themselves in Version A, not realizing the AI remembered. Version B eliminated that confusion entirely. Ten minutes of prototype work saved weeks of post-launch fixes.
Stress-testing multiple agents. One team designed a system with separate agents for transcription and task tracking. The big unknown: would users understand which agent did what? They built a prototype with both running simultaneously, then deliberately introduced errors to see how people tried to correct them. Users didn't distinguish between agents at all. They got frustrated when fixing transcription errors didn't affect task tracking. The solution: present a unified interface with clear handoffs rather than exposing the multi-agent architecture directly.
Where This Goes Next
Enterprise collaboration is changing faster than most people realize. AI agents will become standard participants in meetings. They'll persist across team workflows. They'll coordinate activities that used to require human follow-through.
The platforms that figure out how to make these experiences feel coherent will pull ahead. The ones that ship confusing, fragmented AI interactions will watch adoption stall.
What separates winners increasingly comes down to execution at the UX level. The underlying AI capabilities are converging. Everyone has access to the same foundation models. The differentiator is translating those capabilities into something people actually trust and want to use.
Rapid prototyping gives teams a real edge here. Collapse the time between hypothesis and validation. Learn from real behavior instead of assumptions. Iterate before committing engineering resources. For voice AI in enterprise collaboration, this isn't a nice-to-have methodology. It's becoming the baseline for anyone serious about shipping.
The teams that get good at this will shape how hundreds of millions of people work with intelligent systems.
Note: All views expressed are my own.
Opinions expressed by DZone contributors are their own.
Comments