Reactive Ops to Autonomous Infrastructure: How Agentic AI Is Redefining Modern DevOps
Agentic AI transforms DevOps from reacting to incidents to systems that understand, decide, and act on their own, reducing toil and enabling autonomous infrastructure.
Join the DZone community and get the full member experience.
Join For FreeWhy Operations Can’t Keep Up Anymore
Modern infrastructure has evolved much faster than the way we operate it.
Today’s systems are distributed, constantly changing, and deeply interconnected. A single user request can move through many services, each producing logs, metrics, and traces. We now have more visibility than ever before.
But visibility is not the problem.
The real challenge is that someone still has to make sense of all this information.
When something goes wrong, engineers are expected to:
- Look across multiple dashboards
- Connect signals from different systems
- Identify the root cause
- Decide what action to take
This is where operations begin to struggle.
There is simply too much data. Systems are more complex than before. And most incidents do not follow clear or predictable patterns. What appears to be a simple issue often turns into a chain of related problems.
Because of this, teams spend more time:
- Investigating instead of resolving
- Reacting instead of improving
- Handling alerts instead of building better systems
Even with automation, many workflows still depend on human judgment at critical moments.
And that is the real limitation.
Infrastructure has scaled, but human decision making has not.
This gap is growing quickly, and it is making traditional operations harder to sustain. It is also the reason why a new approach is needed.
From Reactive to Autonomous: A Fundamental Shift
For years, operations have followed a simple pattern.
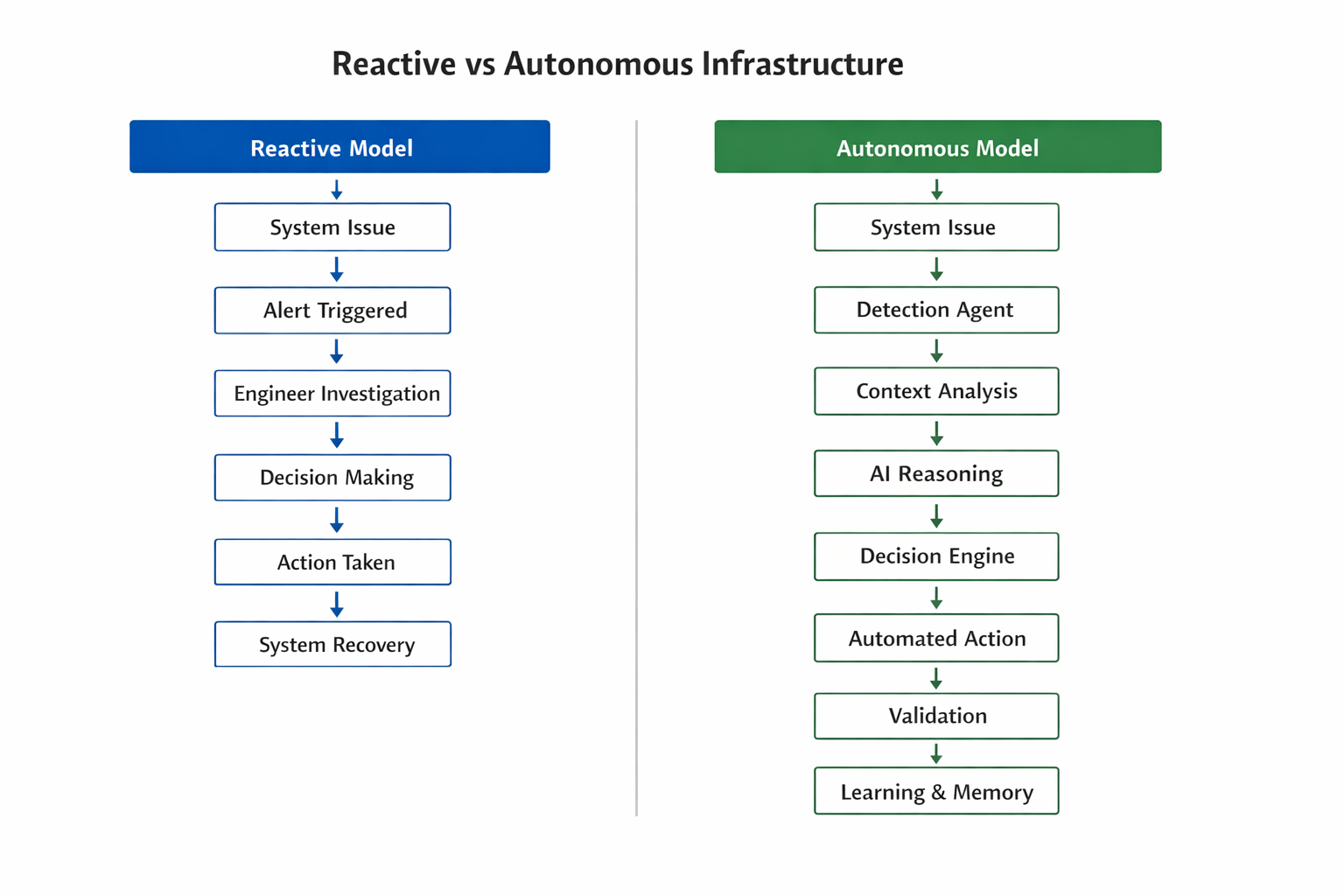
Something breaks. An alert is triggered. An engineer investigates. A fix is applied.
This approach worked when systems were smaller and easier to understand. But today’s environments are very different. Systems are distributed, changes happen frequently, and failures are rarely isolated.
The result is a constant cycle of reacting to problems instead of preventing them.
What Reactive Operations Look Like Today
In most organizations, the flow still looks like this:
- Monitoring tools detect an issue
- Alerts are sent to engineers
- Engineers check dashboards and logs
- They try to connect what is happening
- A decision is made
- The fix is applied
This process depends heavily on human effort at every step.
It also has some clear limitations:
- It takes time to understand the issue
- It depends on the experience of the engineer
- It does not scale well with system complexity
- The same problems are solved again and again
Even with automation, most systems still wait for a human to decide what to do next.
What Changes With Autonomous Infrastructure
Autonomous infrastructure changes this model completely.
Instead of waiting for instructions, the system begins to take responsibility for its own behavior.
It can:
- Observe what is happening
- Understand the context
- Decide what action is needed
- Execute that action
- Learn from the outcome
This removes the constant need for human intervention in routine operations.
The key difference is simple:
Reactive systems respond after something happens.
Autonomous systems understand and act as things are happening.
Breaking Down the Shift Step by Step
This transformation does not happen overnight. It typically evolves through stages.
Stage 1: Manual Operations
Engineers handle everything themselves. Monitoring is basic, and responses are manual.
Stage 2: Automated Operations
Scripts and pipelines handle repetitive tasks, but decisions are still made by humans.
Stage 3: Assisted Intelligence
Systems begin to suggest possible actions, but humans remain in control.
Stage 4: Autonomous Operations
Systems make decisions, take action, and improve over time with minimal human input.
A Practical Architecture for Agentic Infrastructure
Agentic infrastructure is best understood not as a complex system, but as a simple continuous loop.
At any moment, the system is doing five things:
- Observing what is happening
- Understanding the situation
- Deciding what to do
- Taking action
- Learning from the outcome
This loop runs continuously, allowing the system to behave less like a tool and more like an intelligent operator.
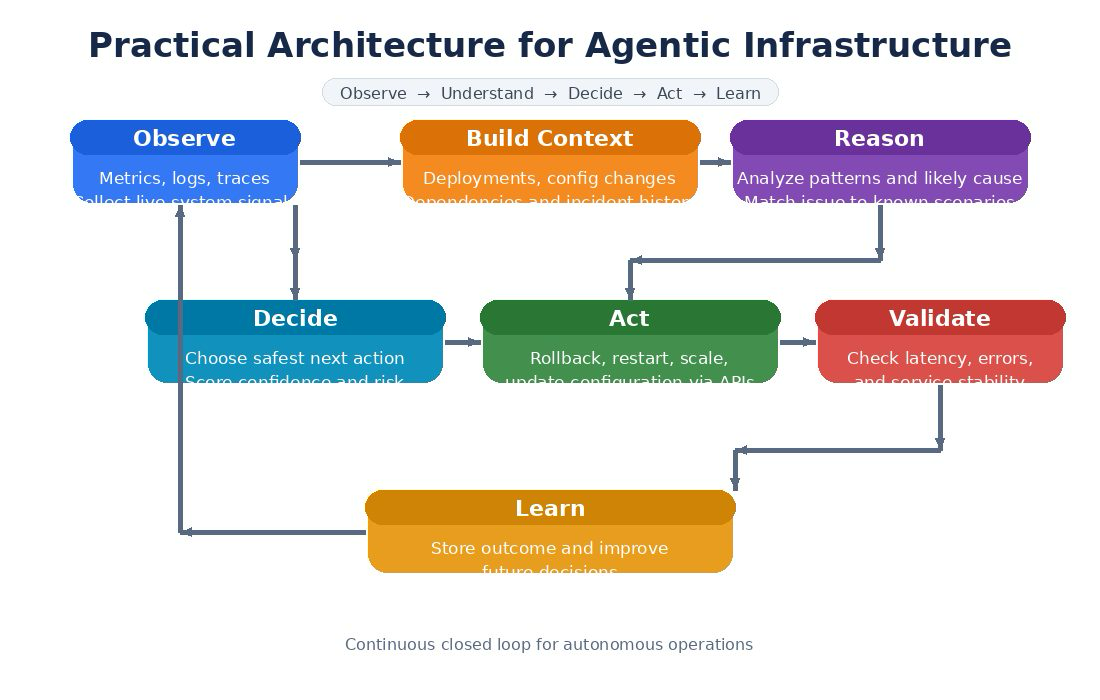
The process begins with collecting signals from the system. These signals usually come from metrics, logs, and traces. In traditional setups, this data sits in dashboards waiting for someone to look at it. In an agentic system, the data is actively pulled and processed.
def collect_signals(service):
return {
"latency": get_latency(service),
"error_rate": get_error_rate(service),
"logs": get_logs(service)
}This step may seem basic, but it is critical. If the system cannot see clearly, it cannot act correctly.
Once the system has signals, it needs to make sense of them. Raw numbers do not explain much. A spike in latency could be caused by a deployment, a dependency failure, or resource limits.
To understand the situation, the system adds context. It looks at recent changes, system dependencies, and past incidents. This is what transforms raw data into something meaningful.
For example, if the system sees an increase in errors and also notices a deployment happened a few minutes ago, it starts forming a connection. This is similar to how an engineer would think during an investigation.
After building context, the system moves into reasoning. This is where agentic AI plays a key role.
Instead of following predefined rules, the system evaluates the situation and asks:
- What is most likely causing this issue?
- Have we seen something similar before?
- What actions worked in the past?
In a real system, this is where an LLM would analyze logs, patterns, and relationships to form a hypothesis.
Once the system understands the problem, it needs to decide what to do next.
This is not just about choosing an action. It is about choosing the right action based on:
- Risk
- Confidence
- Potential impact
For example, if the system strongly believes a deployment caused the issue, rolling back might be the safest option. If the issue looks like resource exhaustion, scaling might be better.
The system does not act blindly. It evaluates options and selects the most appropriate one.
After the decision is made, the system executes it using infrastructure APIs. This could involve restarting a service, scaling resources, or rolling back a deployment.
def execute(service, action):
if action == "rollback":
rollback(service)
elif action == "scale":
scale(service)This is where the system moves from analysis to real change.
But execution alone is not enough. The system must verify that the action actually solved the problem.
It checks whether:
- Error rates have dropped
- Latency has improved
- The system has stabilized
If the issue is not resolved, the system can try another approach or escalate.
Finally, the system learns from what happened.
Every incident becomes a data point:
- What was the issue
- What decision was made
- What the result was
Over time, this builds a memory that allows the system to:
- Recognize recurring problems
- Apply proven solutions faster
- Avoid ineffective actions
When all these steps come together, the system behaves very differently from traditional automation.
It is no longer waiting for instructions. It is actively:
- Observing its own state
- Understanding what is happening
- Making decisions
- Taking action
- Improving over time
To make this more real, imagine a common scenario.
A service starts failing right after a deployment. The system detects the spike in errors, checks that a deployment happened recently, compares it with past incidents, and concludes that the deployment is likely the cause. It rolls back the change, verifies recovery, and records the outcome.
No manual investigation. No delay.
This is what makes agentic infrastructure powerful.
It does not replace engineers. It removes the repetitive, time-consuming parts of operations, allowing teams to focus on building better systems.
And most importantly, it turns infrastructure into something that can take care of itself.
What Makes Agentic AI Different
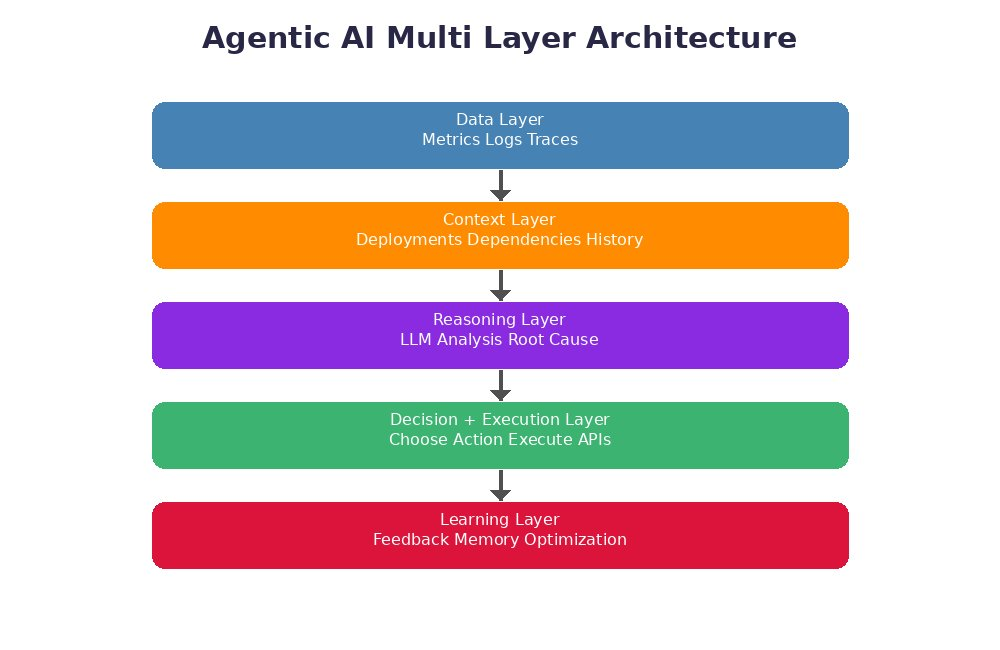
At a surface level, agentic AI may look like another automation layer. It collects data, processes signals, and triggers actions. But the real difference is not in what it does. It is in how it thinks.
Traditional automation follows instructions.
Agentic AI works toward outcomes.
That shift changes how systems behave.
In most environments today, automation is built around rules. If something happens, do a specific action. These rules are useful, but they only work when the situation matches what was expected. The moment something unusual happens, the system cannot adapt. It either does the wrong thing or does nothing at all.
Modern infrastructure rarely behaves in predictable ways. A single issue can involve multiple services, delayed signals, or hidden dependencies. In these situations, fixed rules are not enough.
Agentic AI approaches the problem differently.
Instead of reacting to one signal, it tries to understand the full situation. It gathers information from different sources, connects related events, and forms a view of what is actually happening. Only then does it decide what to do.
This is similar to how an experienced engineer works during an incident. They do not jump to conclusions based on one alert. They look at logs, recent changes, system behavior, and past patterns before making a decision.
Agentic systems bring that same thinking into the platform itself.
Another key difference is that agentic AI is goal driven.
Traditional automation focuses on tasks. Restart a service. Scale a system. Run a script. Each action is predefined.
Agentic AI focuses on outcomes such as restoring system health or reducing impact. That means it can choose different actions depending on the situation.
For example, if a service slows down, a rule based system may always scale resources. But an agentic system will ask:
- Did this start after a deployment
- Are there new errors in logs
- Is a dependency failing
If it finds that a deployment caused the issue, it may roll back instead of scaling. The action is not fixed. It is chosen based on what will best solve the problem.
Agentic AI also brings memory into operations.
In traditional systems, every incident is handled as if it is new. Engineers may remember past issues, but the system does not. Agentic systems store what happened, what action was taken, and whether it worked.
Over time, this creates a knowledge base that helps the system:
- Recognize repeat problems faster
- Apply proven solutions
- Avoid actions that failed before
This makes the system smarter with every incident.
Another important difference is how decisions are made.
Traditional automation assumes certainty. If a condition is true, the action is executed.
Agentic AI works with confidence and risk.
It can decide:
- This looks like a deployment issue with high confidence
- This might be resource saturation, but confidence is low
Based on that, it can:
- Act automatically for safe decisions
- Ask for approval when risk is higher
This makes it much safer for real production environments.
To make this simple, think of the difference like this:
Traditional automation executes predefined actions.
Agentic AI understands situations and chooses actions.
That is the shift.
Simple Example
A basic rule based system might do this:
if cpu > 85:
scale_service()An agentic system takes a broader view:
if latency_is_high:
analyze_logs()
check_deployments()
evaluate_dependencies()
choose_best_action()The first reacts to a single signal.
The second builds understanding before acting.
Why This Matters
This approach reduces repeated manual work and allows systems to handle common operational decisions on their own.
Instead of engineers spending time investigating the same types of issues again and again, the system begins to take on that responsibility.
This does not replace engineers. It allows them to focus on improving systems instead of constantly fixing them.
That is what makes agentic AI different. It adds intelligence to operations, not just automation.
Conclusion
The move from reactive operations to autonomous infrastructure is a major shift in how systems are managed.
For a long time, we focused on better monitoring and more automation. But even with all these tools, systems still depend on humans to understand issues and decide what to do. That is where the real bottleneck exists.
Agentic AI changes this by bringing decision making into the system itself. It allows infrastructure to understand what is happening, take action, and improve over time.
This does not replace engineers. It removes the repetitive work and constant firefighting, so teams can focus on building better and more reliable systems.
Of course, this shift needs to be done carefully with proper guardrails and gradual adoption. But the direction is clear.
Infrastructure is no longer just something we monitor and fix.
It is becoming something that can take care of itself.
And that is the future of DevOps.
Opinions expressed by DZone contributors are their own.
Comments