How Reactive Scaling Drains Your Cloud Budget Without Warning
Reactive auto-scaling wastes cloud budgets on idle servers. Learn to replace it with a predictive C# and ML.NET engine that forecasts latency and scales proactively.
Join the DZone community and get the full member experience.
Join For FreeIn high-scale engineering, milliseconds eventually turn into millions of dollars in either revenue or waste. Most infrastructure teams today accept a "tax of fear" where they over-provision resources by 30 percent to 50 percent simply because they cannot trust their scaling policies to react in time. This is the invisible bleed of cloud computing. We build systems that are technically "up," yet they are financially hemorrhaging because our scaling strategies are fundamentally reactive.
The Invisible Cost of Infrastructure Fear
Reactive auto-scaling is, by design, a lagging indicator. It waits for the disaster to manifest as a CPU spike, a memory leak, or a saturated disk before it even begins provisioning new capacity. In mission-critical environments, by the time a new node is healthy and receiving traffic, the latency spike has already breached the SLA and impacted the customer.
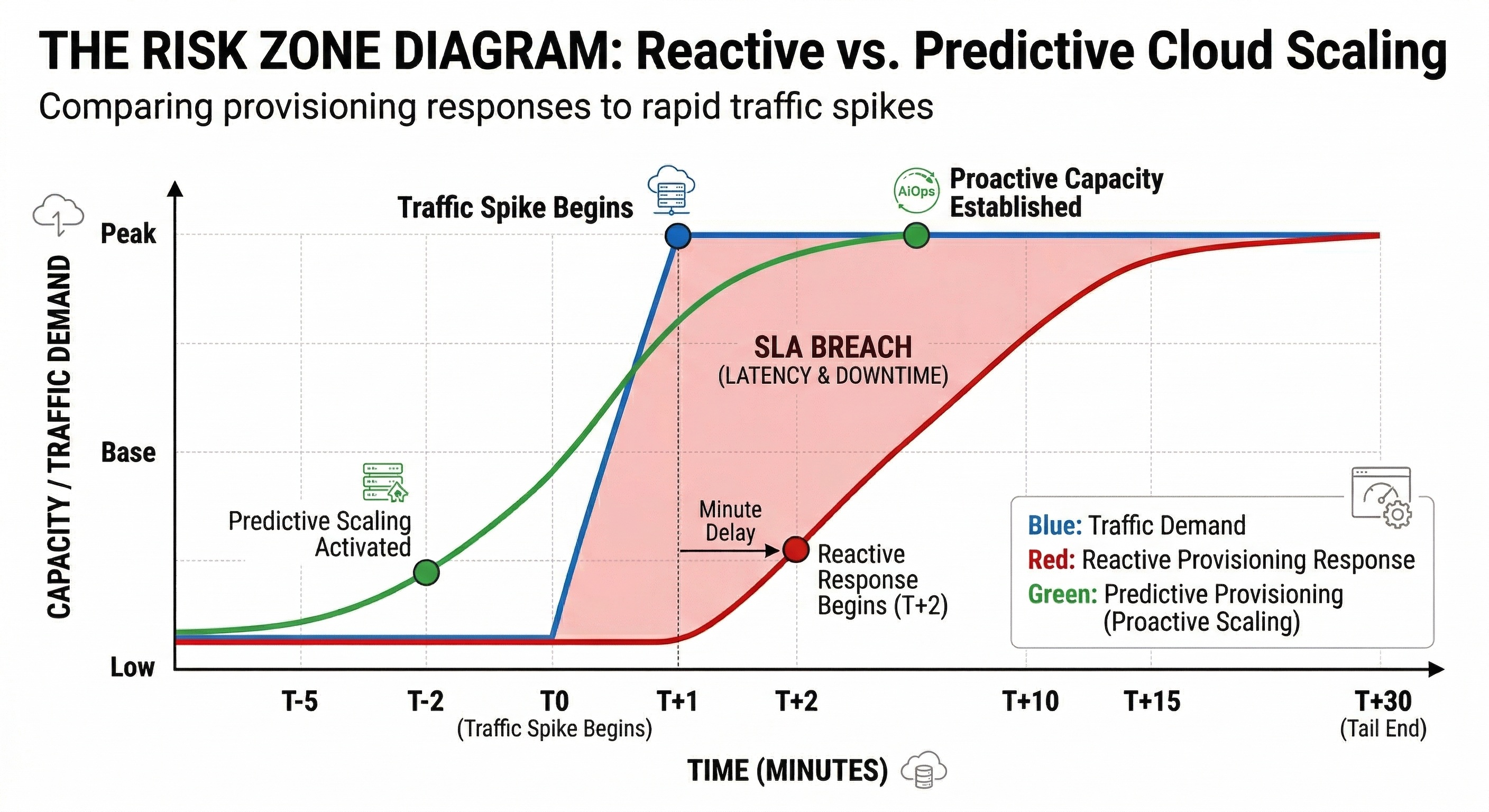
To compensate for this mechanical slowness, engineers over-provision. They end up paying for idle servers 24/7 just to survive a three-minute traffic surge. This is not optimized engineering; it is pure expensive guesswork. The real challenge is not to react faster, but to predict performance degradation before it reflects on the monitoring dashboards.
Why Traditional Monitoring Ignores the Real Bottlenecks
Standard cloud monitors are obsessed with the server surface. They report CPU and RAM utilization but ignore the internal friction of the runtime and the operating system. During the development of CloudSealed-Predictive-ML-Core, we shifted the focus to low-level telemetry that effectively predicts failures before they occur.
We identified four specific metrics that serve as early warning signs of system exhaustion. Thread context switches indicate the hidden cost of concurrency management. Generation 2 garbage collections reveal the critical pauses that freeze processing in the .NET environment. The IOPS throttle rate and the network queue length show that the physical limits of the infrastructure are being reached before the application even realizes it is slow.
public class TelemetryData
{
[LoadColumn(0)] public float ThreadContextSwitches { get; set; }
[LoadColumn(1)] public float Gen2GcCollections { get; set; }
[LoadColumn(2)] public float IopsThrottleRate { get; set; }
[LoadColumn(3)] public float NetworkQueueLength { get; set; }
[LoadColumn(4)] public float Latency { get; set; }
}Simple linear regression fails to model the chaotic behavior of a server under a traffic attack. A 10 percent increase in context switches might be harmless in isolation, but if it occurs concurrently with a garbage collector pause, the system latency will skyrocket exponentially.
Building a Predictive Brain With C# and ML.NET
To move beyond reactive firefighting, we implemented a predictive intelligence layer using C# and .NET 10. The core engine utilizes the FastTree regression algorithm within the ML.NET ecosystem to model the non-linear relationships between these low-level signals and the final system latency.
A non-negotiable requirement for this architecture was scientific reproducibility. In compliance audits and forensic infrastructure investigations, an artificial intelligence black box represents an unacceptable risk. By enforcing a deterministic context with a fixed seed, we ensure that every diagnostic report and training session can be audited and reproduced with absolute precision.
public PredictiveHeuristicsEngine()
{
// Seed 42 ensures determinism for mission-critical audits
_mlContext = new MLContext(42);
}The clear separation between the training engine and the prediction service ensures that the Machine Learning model can be updated and deployed in production environments with zero downtime. The testing framework guarantees that the engine not only trains correctly but that the latency predictions are rigorously coherent before any large-scale integration.
The Mathematical Advantage of Gradient Boosting in Infrastructure
Why choose FastTree over simpler statistical methods? In a cloud environment, resource contention is rarely a linear progression. A small increase in network packets doesn't just add a millisecond of delay; it can trigger a cascade of thread locks and memory pressure that leads to exponential latency growth.
Traditional linear regression attempts to draw a straight line through these events, often missing the "tipping point" until it is too late. By utilizing Gradient Boosted Decision Trees, the engine constructs an ensemble of weak prediction models into a strong predictor. This allows the system to recognize complex patterns — such as the specific moment when a Gen2 GC collection coincides with high context switching — providing the precision necessary for high-stakes proactive scaling.
Proactive Scaling in Practice
The ultimate goal is to create a system that understands its own breaking point. Our interface demonstrates this by analyzing real-time telemetry to forecast imminent responsiveness violations. When the engine predicts that latency will cross the 200-millisecond barrier, it does not wait for the server to start struggling. Instead, it triggers node expansion heuristically, long before the user experience degrades.
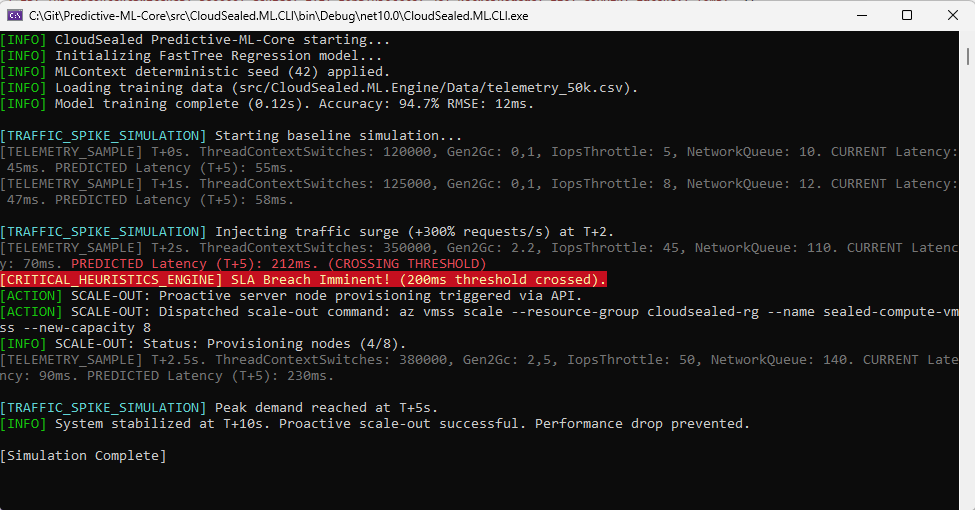
var prediction = engine.Predict(trafficSpike);
if (prediction.PredictedLatency > 200)
{
Console.WriteLine("[CRITICAL] SLA Breach Imminent.");
Console.WriteLine("[ACTION] Triggering Node Scale-Out.");
}This shift towards a predictive FinOps management mindset is what allows us to stop throwing money at cloud providers and start designing engineering focused on real efficiency. By extracting meaning from the low-level telemetry noise, we transform the infrastructure from a passive cost center into a self-optimizing engine that actively protects profit margins.
The open-source code, the core architecture, and the unit tests of the predictive intelligence layer are available for community review.
Official repository link: github.com/cloudsealed/Predictive-ML-Core
Opinions expressed by DZone contributors are their own.
Comments