Reading Data From Oracle Database With Apache Spark
In this quick tutorial, learn how to use Apache Spark to read and use the RDBMS directly without having to go into the HDFS and store it there.
Join the DZone community and get the full member experience.
Join For FreeIn this article, I will connect Apache Spark to Oracle DB, read the data directly, and write it in a DataFrame.
Following the rapid increase in the amount of data we produce in daily life, big data technology has entered our lives very quickly. Instead of traditional solutions, we are now using tools with the capacity to solve our business quickly and efficiently. The use of Apache Spark is a common technology that can fulfill our needs.
Apache Spark is based on a framework that can process data very quickly and distributedly. In this article, I will not describe Apache Spark technology in detail, so those who are interested in the details should check out the Apache Spark documentation.
The preferred method to process the data we store in our RDBMS databases with Apache Spark is to migrate the data to Hadoop first (HDFS), distributively read the data we have stored in Hadoop (HDFS), and process it with Apache Spark. As those with Hadoop ecosystem experience know, we are exchanging data between the Hadoop ecosystem and other systems (RDBMS-NoSQL) with tools that integrate into the Hadoop ecosystem with Sqoop. Sqoop is a data transfer tool that is easy to use, common, and efficient.
There is some cost involved in moving the data to be processed to the Hadoop environment before the RDBMS, and then importing the data to be processed with Apache Spark. The fact that we do not use the data that we have moved to HDFS will cause us to lose a certain amount of space in HDFS, and it will also increase the processing time. Instead of this method, there is a way with Apache Spark that reads and uses the RDBMS directly without having to go to the HDFS and store it there — especially afterward.
Let's see how to do this.
The technologies and versions I used are as follows:
Hadoop: Hadoop 2.7.1
Apache Spark: Apache Spark 2.1.0
Oracle database: Oracle 11g R2, Enterprise Edition
Linux: SUSE Linux
To do this, we need to have the ojdbc6.jar file in our system. You can use this link to download it.
We will create tables in the Oracle database that we will read from Oracle and insert sample data in them.
CREATE TABLE EMP
(
EMPNO NUMBER,
ENAME VARCHAR (10),
JOB VARCHAR (9),
MGR NUMBER,
SAL NUMBER,
COMM NUMBER,
DEPTNO NUMBER
);
INSERT INTO EMP VALUES
(7369, 'SMITH', 'CLERK', 7902, 800, 50, 20);
INSERT INTO EMP VALUES
(7499, 'ALLEN', 'SALESMAN', 7698, 1600, 300, 30);
INSERT INTO EMP VALUES
(7521, 'WARD', 'SALESMAN', 7698, 1250, 500, 30);
INSERT INTO EMP VALUES
(7566, 'JONES', 'MANAGER', 7839, 2975, NULL, 20);
INSERT INTO EMP VALUES
(7654, 'MARTIN', 'SALESMAN', 7698, 1250, 1400, 30);
INSERT INTO EMP VALUES
(7698, 'BLAKE', 'MANAGER', 7839, 2850, NULL, 30);
INSERT INTO EMP VALUES
(7782, 'CLARK', 'MANAGER', 7839, 2450, NULL, 10);
INSERT INTO EMP VALUES
(7788, 'SCOTT', 'ANALYST', 7566, 3000, NULL, 20);
INSERT INTO EMP VALUES
(7839, 'KING', 'PRESIDENT', NULL, 5000, NULL, 10);
INSERT INTO EMP VALUES
(7844, 'TURNER', 'SALESMAN', 7698, 1500, 0, 30);
INSERT INTO EMP VALUES
(7876, 'ADAMS', 'CLERK', 7788, 1100, NULL, 20);
INSERT INTO EMP VALUES
(7900, 'JAMES', 'CLERK', 7698, 950, NULL, 30);
INSERT INTO EMP VALUES
(7902, 'FORD', 'ANALYST', 7566, 3000, NULL, 20);
INSERT INTO EMP VALUES
(7934, 'MILLER', 'CLERK', 7782, 1300, NULL, 10);
CREATE TABLE DEPT
(
DEPTNO NUMBER,
DNAME VARCHAR (14),
LOC VARCHAR (13)
);
INSERT INTO DEPT VALUES (10, 'ACCOUNTING', 'NEW YORK');
INSERT INTO DEPT VALUES (20, 'RESEARCH', 'DALLAS');
INSERT INTO DEPT VALUES (30, 'SALES', 'CHICAGO');
INSERT INTO DEPT VALUES (40, 'OPERATIONS', 'BOSTON');
COMMIT;Now we are starting Apache Spark from the linux terminal with Pyspark interface (Python Interface).
/spark-2.1.0-bin-hadoop2.7/bin/pyspark
--jars "/home/jars/ojdbc6.jar"
--master yarn-client
--num-executors 10
--driver-memory 16g
--executor-memory 8g We started Apache Spark. Now let's write the Python code to read the data from the database and run it.
We started Apache Spark. Now let's write the Python code to read the data from the database and run it.
empDF = spark.read \
.format("jdbc") \
.option("url", "jdbc:oracle:thin:username/password@//hostname:portnumber/SID") \
.option("dbtable", "hr.emp") \
.option("user", "db_user_name") \
.option("password", "password") \
.option("driver", "oracle.jdbc.driver.OracleDriver") \
.load()Let's take a look at the contents of this dataframe as we write to the empDF dataframe.
empDF.printSchema()
empDF.show()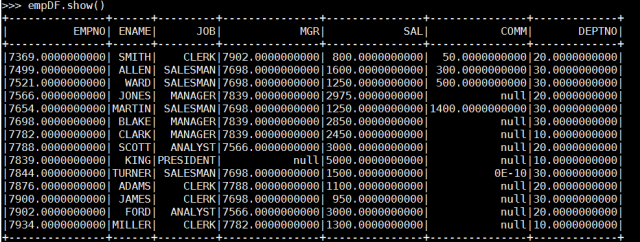
Yes, I connected directly to the Oracle database with Apache Spark. Likewise, it is possible to get a query result in the same way.
query = "(select empno,ename,dname from emp, dept where emp.deptno = dept.deptno) emp"
empDF = spark.read \
.format("jdbc") \
.option("url", "jdbc:oracle:thin:username/password@//hostname:portnumber/SID") \
.option("dbtable", query) \
.option("user", "db_user_name") \
.option("password", "password") \
.option("driver", "oracle.jdbc.driver.OracleDriver") \
.load()
empDF.printSchema()
empDF.show()
It is very easy and practical to use, as you can see from the examples made above.
With this method, it is possible to load large tables directly and in parallel, but I will do the performance evaluation in another article.
Opinions expressed by DZone contributors are their own.
Comments