Real-Time Stock Processing With Apache NiFi and Apache Kafka, Part 1
A big data expert starts his series on using Kafka and NiFi for real-time data flow programming.
Join the DZone community and get the full member experience.
Join For FreeImplementing Streaming Use Case From REST to Hive With Apache NiFi and Apache Kafka
Part 1
With Apache Kafka 2.0 and Apache NiFi 1.8, there are many new features and abilities coming out. It's time to put them to the test.
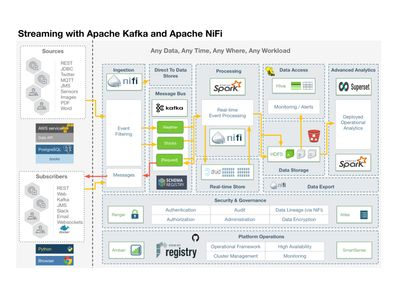
So to plan out what we are going to do, I have a high-level architecture diagram. We are going to ingest a number of sources including REST feeds, Social Feeds, Messages, Images, Documents, and Relational Data.
We will ingest with NiFi and then filter, process, and segment it into Kafka topics. Kafka data will be in Apache Avro format with schemas specified in the Hortonworks Schema Registry. Spark and NiFi will do additional event processing along with machine learning and deep learning. This will be stored in Druid for real-time analytics and summaries. Hive, HDFS, and S3 will store the data for permanent storage. We will do dashboards with Superset and Spark SQL + Zeppelin.
We will also push back cleaned and aggregated data to subscribers via Kafka and NiFi. We will push to Dockerized applications, message listeners, web clients, Slack channels, and email mailing lists.
To be useful in our enterprise, we will have full authorization, authentication, auditing, data encryption, and data lineage via Apache Ranger, Apache Atlas, and Apache NiFi. NiFi Registry and GitHub will be used for source code control.
We will have administration capabilities via Apache Ambari.
An example server layout:
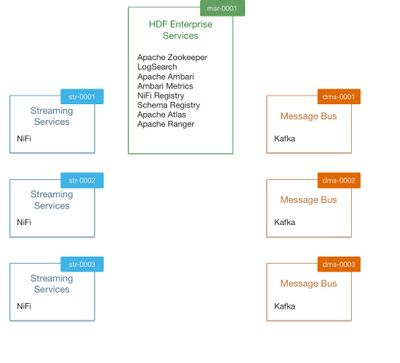
NiFi Flows
Real-time free stock data is available from IEX with no license key. The data streams in very fast, thankfully that's no issue for Apache NiFi and Kafka.
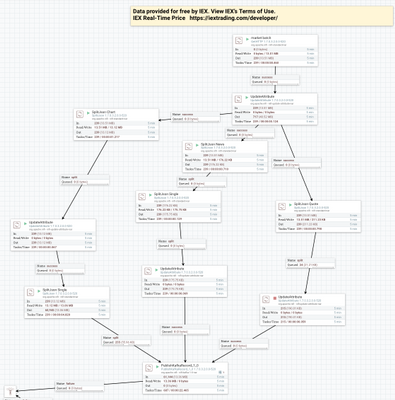
Consume the Different Records from topics and store to HDFS in separate directories and tables.
Let's split up one big REST file into individual records of interest. Our REST feed has quote, chart and news arrays.
Let's Push Some Messages to Slack
We can easily consume from multiple topics in Apache NiFi.
Querying data is easy as it's in motion, since we have schemas
We create schemas for each of our Kafka Topics
We can monitor all these messages going through Kafka in Ambari (and also in much better detail in Cloudera SMM).
I read in data and then can push it to Kafka 1.0 and 2.0 brokers.
Once data is sent, NiFi let's us know.
Projects Used
- Apache Kafka
- Apache NiFi
- Apache Druid
- Apache Hive on Kafka
- Apache Hive on Druid
- Apache Hive on JDBC
- Apache Zeppelin
- NLP - Apache OpenNLP and Stanford CoreNLP
- Horotnworks Schema Registry
- NiFi Registry
- Apache Ambari
- Log Search
- Hortonworks SMM
- Hortonworks Data Plane Services (DPS)
Sources
REST
Sinks
- Apache Hadoop HDFS
- Apache Kafka
- Apache Hive
- Slack
- S3
- Apache Druid
- Apache HBase
Topics
- iextradingnews
- iextradingquote
- iextradingchart
- stocks
- cyber
HDFS Directories
hdfs dfs -mkdir -p /iextradingnews
hdfs dfs -mkdir -p /iextradingquote
hdfs dfs -mkdir -p /iextradingchart
hdfs dfs -mkdir -p /stocks
hdfs dfs -mkdir -p /cyber
hdfs dfs -chmod -R 777 /PutHDFS
- /${kafka.topic}
- /iextradingchart/859496561256574.orc
- /iextradingnews/855935960267509.orc
- /iextradingquote/859143934804532.orc
Hive Tables
CREATE EXTERNAL TABLE IF NOT EXISTS iextradingchart (`date` STRING, open DOUBLE, high DOUBLE, low DOUBLE, close DOUBLE, volume INT, unadjustedVolume INT, change DOUBLE, changePercent DOUBLE, vwap DOUBLE, label STRING, changeOverTime INT)
STORED AS ORC
LOCATION '/iextradingchart';
CREATE EXTERNAL TABLE IF NOT EXISTS iextradingquote (symbol STRING, companyName STRING, primaryExchange STRING, sector STRING, calculationPrice STRING, open DOUBLE, openTime BIGINT, close DOUBLE, closeTime BIGINT, high DOUBLE, low DOUBLE, latestPrice DOUBLE, latestSource STRING, latestTime STRING, latestUpdate BIGINT, latestVolume INT, iexRealtimePrice DOUBLE, iexRealtimeSize INT, iexLastUpdated BIGINT, delayedPrice DOUBLE, delayedPriceTime BIGINT, extendedPrice DOUBLE, extendedChange DOUBLE, extendedChangePercent DOUBLE, extendedPriceTime BIGINT, previousClose DOUBLE, change DOUBLE, changePercent DOUBLE, iexMarketPercent DOUBLE, iexVolume INT, avgTotalVolume INT, iexBidPrice INT, iexBidSize INT, iexAskPrice INT, iexAskSize INT, marketCap INT, peRatio DOUBLE, week52High DOUBLE, week52Low DOUBLE, ytdChange DOUBLE)
STORED AS ORC
LOCATION '/iextradingquote';
CREATE EXTERNAL TABLE IF NOT EXISTS iextradingnews (`datetime` STRING, headline STRING, source STRING, url STRING, summary STRING, related STRING, image STRING)
STORED AS ORC
LOCATION '/iextradingnews';Schemas
{ "type": "record", "name": "iextradingchart", "fields": [ { "name": "date", "type": [ "string", "null" ] }, { "name": "open", "type": [ "double", "null" ] }, { "name": "high", "type": [ "double", "null" ] }, { "name": "low", "type": [ "double", "null" ] }, { "name": "close", "type": [ "double", "null" ] }, { "name": "volume", "type": [ "int", "null" ] }, { "name": "unadjustedVolume", "type": [ "int", "null" ] }, { "name": "change", "type": [ "double", "null" ] }, { "name": "changePercent", "type": [ "double", "null" ] }, { "name": "vwap", "type": [ "double", "null" ] }, { "name": "label", "type": [ "string", "null" ] }, { "name": "changeOverTime", "type": [ "int", "null" ] } ]}{ "type": "record", "name": "iextradingquote", "fields": [ { "name": "symbol", "type": [ "string", "null" ], "doc": "Type inferred from '\"HDP\"'" }, { "name": "companyName", "type": [ "string", "null" ], "doc": "Type inferred from '\"Hortonworks Inc.\"'" }, { "name": "primaryExchange", "type": [ "string", "null" ], "doc": "Type inferred from '\"Nasdaq Global Select\"'" }, { "name": "sector", "type": [ "string", "null" ], "doc": "Type inferred from '\"Technology\"'" }, { "name": "calculationPrice", "type": [ "string", "null" ], "doc": "Type inferred from '\"close\"'" }, { "name": "open", "type": [ "double", "null" ], "doc": "Type inferred from '16.3'" }, { "name": "openTime", "type": [ "long", "null" ], "doc": "Type inferred from '1542033000568'" }, { "name": "close", "type": [ "double", "null" ], "doc": "Type inferred from '15.76'" }, { "name": "closeTime", "type": [ "long", "null" ], "doc": "Type inferred from '1542056400520'" }, { "name": "high", "type": [ "double", "null" ], "doc": "Type inferred from '16.37'" }, { "name": "low", "type": [ "double", "null" ], "doc": "Type inferred from '15.2'" }, { "name": "latestPrice", "type": [ "double", "null" ], "doc": "Type inferred from '15.76'" }, { "name": "latestSource", "type": [ "string", "null" ], "doc": "Type inferred from '\"Close\"'" }, { "name": "latestTime", "type": [ "string", "null" ], "doc": "Type inferred from '\"November 12, 2018\"'" }, { "name": "latestUpdate", "type": [ "long", "null" ], "doc": "Type inferred from '1542056400520'" }, { "name": "latestVolume", "type": [ "int", "null" ], "doc": "Type inferred from '4012339'" }, { "name": "iexRealtimePrice", "type": [ "double", "null" ], "doc": "Type inferred from '15.74'" }, { "name": "iexRealtimeSize", "type": [ "int", "null" ], "doc": "Type inferred from '43'" }, { "name": "iexLastUpdated", "type": [ "long", "null" ], "doc": "Type inferred from '1542056397411'" }, { "name": "delayedPrice", "type": [ "double", "null" ], "doc": "Type inferred from '15.76'" }, { "name": "delayedPriceTime", "type": [ "long", "null" ], "doc": "Type inferred from '1542056400520'" }, { "name": "extendedPrice", "type": [ "double", "null" ], "doc": "Type inferred from '15.85'" }, { "name": "extendedChange", "type": [ "double", "null" ], "doc": "Type inferred from '0.09'" }, { "name": "extendedChangePercent", "type": [ "double", "null" ], "doc": "Type inferred from '0.00571'" }, { "name": "extendedPriceTime", "type": [ "long", "null" ], "doc": "Type inferred from '1542059622726'" }, { "name": "previousClose", "type": [ "double", "null" ], "doc": "Type inferred from '16.24'" }, { "name": "change", "type": [ "double", "null" ], "doc": "Type inferred from '-0.48'" }, { "name": "changePercent", "type": [ "double", "null" ], "doc": "Type inferred from '-0.02956'" }, { "name": "iexMarketPercent", "type": [ "double", "null" ], "doc": "Type inferred from '0.03258'" }, { "name": "iexVolume", "type": [ "int", "null" ], "doc": "Type inferred from '130722'" }, { "name": "avgTotalVolume", "type": [ "int", "null" ], "doc": "Type inferred from '2042809'" }, { "name": "iexBidPrice", "type": [ "int", "null" ], "doc": "Type inferred from '0'" }, { "name": "iexBidSize", "type": [ "int", "null" ], "doc": "Type inferred from '0'" }, { "name": "iexAskPrice", "type": [ "int", "null" ], "doc": "Type inferred from '0'" }, { "name": "iexAskSize", "type": [ "int", "null" ], "doc": "Type inferred from '0'" }, { "name": "marketCap", "type": [ "int", "null" ], "doc": "Type inferred from '1317308142'" }, { "name": "peRatio", "type": [ "double", "null" ], "doc": "Type inferred from '-7.43'" }, { "name": "week52High", "type": [ "double", "null" ], "doc": "Type inferred from '26.22'" }, { "name": "week52Low", "type": [ "double", "null" ], "doc": "Type inferred from '15.2'" }, { "name": "ytdChange", "type": [ "double", "null" ], "doc": "Type inferred from '-0.25696247383444343'" } ]}{ "type" : "record", "name" : "iextradingchart", "fields" : [ { "name" : "date", "type" : ["string","null"] }, { "name" : "open", "type" : ["double","null"] }, { "name" : "high", "type" : ["double","null"] }, { "name" : "low", "type" : ["double","null"] }, { "name" : "close", "type" : ["double","null"] }, { "name" : "volume", "type" : ["int","null"] }, { "name" : "unadjustedVolume", "type" : ["int","null"] }, { "name" : "change", "type" : ["double","null"] }, { "name" : "changePercent", "type" : ["double","null"] }, { "name" : "vwap", "type" : ["double","null"] }, { "name" : "label", "type" : ["string","null"] }, { "name" : "changeOverTime", "type" : ["int","null"] } ] }Messages to Slack
File: ${'filename'}
Offset: ${'kafka.offset'}
Partition: ${'kafka.partition'}
Topic: ${'kafka.topic'}
UUID: ${'uuid'}
Record Count: ${'record.count'}
File Size: ${fileSize:divide(1024)}K
See jsonpath.com
Splits
$.*.quote
$.*.chart
$.*.news
Array to Single
$.*
GETHTTP
URL
FileName
marketbatch.hdp.${'hdp':append(${now():format('yyyymmddHHMMSS'):append(${md5}):append('.json')})} Data provided for free by IEX. View IEX’s Terms of Use.
Queries
SELECT * FROM FLOWFILE
WHERE latestPrice > week52Low
SELECT * FROM FLOWFILE
WHERE latestPrice <= week52LowExample Output
File: 855957937589894
Offset: 22460
Partition: 0
Topic: iextradingquote
UUID: b2a8e797-2249-4689-9a78-4339ddb5ecb4
Record Count:
File Size: 3K
Data Visualization in Apache Zeppelin With Hive and Spark SQL

Creating tables on top of Apache ORC files in HDFS is easy.


Push Some Messages to Slack
Opinions expressed by DZone contributors are their own.
Comments