Operationalizing Responsible AI: Turning Ethics Into Engineering
This article will provide a direction on how to build a reliable AI system in production by incorporating bias mitigation strategies.
Join the DZone community and get the full member experience.
Join For FreeLately, it feels like everyone is talking about responsible AI — but what does it actually mean when you are the engineer pushing a model to production?
You already check for latency, accuracy, and monitoring before a release — but do you ever check off "ethical AI"? When your model delivers a prediction or recommendation and a user asks, "Why these results and not the other ?", do you have a clear explanation or just a shrug and "the algorithm suggested it"? This is the uncomfortable gap between AI capability and AI accountability.
Ethical AI is not a high-level policy statement. It is a design decision made at every steps of the model development process.
As regulations and frameworks for AI go live around the world, engineers need to design and build AI systems that are not just performant but also responsible and trustworthy. But how do you address bias? Transparency? Privacy? Governance? How can you bake ethics in while building, not retrospectively after deployment?
In the post, we will walk through how to operationalize five dimensions of responsible AI — fairness, transparency, privacy, accountability, and sustainability — with examples, metrics, and an open demo you can play with at Ethical AI Demo.
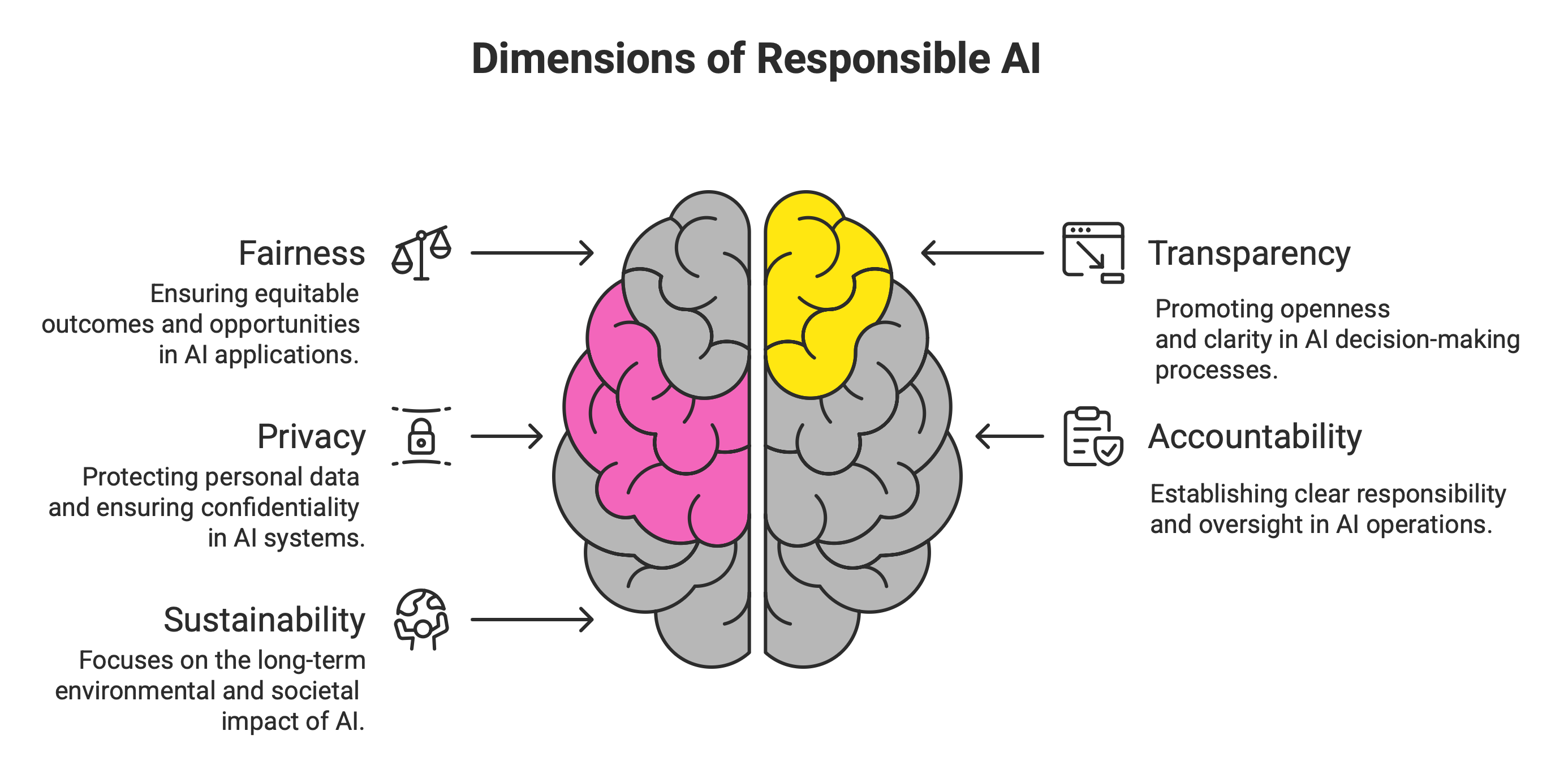
Fairness and Bias Mitigation: Detecting and Reducing Bias
ML algorithms have started to influence our everyday life, and they are part of many high-stakes decisions in areas such as recruitment, medical diagnosis, clinical drug discoveries, etc. We cannot afford to have 'unfair' decisions. Fairness is not about being politically correct. It's about not amplifying real-world inequality through your model decisions. Biases in the data skew will prevent the algorithm from making fair decisions, even when the data is unbiased. For example, a dataset with mostly male applicants for a job will have a gender skew.
Now, beyond obvious bias, there is latent bias or proxy discrimination where the model unintentionally picks up information from features that correlate strongly with sensitive attributes, even if those attributes are not directly included in the data. For example, even if you didn't include "gender" or "race," your model may still discriminate through proxy features (like ZIP code or education level).
These are some common ways in which bias leaks into production.
Deep Dive: Mitigation
- Always quantify fairness through metrics, don't guess it.
- Define fairness metrics early in your model design. Some examples are:
- Demographic Parity (equal outcomes across groups)
- Equalized Odds (equal error rates across groups)
- Predictive Parity (similar precision/recall per group)
- These metrics turn fairness from philosophy into concrete targets to measure
- Instrument bias testing, like you do unit testing.
- Visualize fairness trade-offs through dashboards that plot accuracy vs fairness gap across different model versions. These kinds of visualizations let teams discuss ethics using data and not opinions.
Example: Fairlearn Bias Check
from fairlearn.metrics import MetricFrame, selection_rate, demographic_parity_difference
from sklearn.metrics import accuracy_score
#y_true = groud truth, y_pred = model predictions
#sensitive_features = eg.g.,gender column
metrics = {'accuracy': accuracy_score, 'selection_rate': selection_rate}
mf = MetricFrame(
metrics=metrics,
y_true=y_true,
y_pred=y_pred,
sensitive_features=gender_column
)
print("Accuracy by group:\n", mf.by_group['accuracy'])
print("Demographic Parity Difference:",
demographic_parity_difference(y_true, y_pred,
sensitive_features=gender_column))
Case Study: Bias Mitigation in Practice
| Model | Accuracy | Demographic Parity Diff | Equalized Odd Diff | Notes |
|---|---|---|---|---|
| Baseline | 86.2% | 0.208 | 0.132 | Accurate but biased |
| Demographic Parity Constraint | 84.4% | 0.022 | 0.284 | Equal outcomes, higher error gap |
| Equalized Odds Constraint | 85.7% | 0.109 | 0.037 | Balanced fairness + accuracy |
Interpretation
- Baseline – best accuracy, worst fairness
- Demographic parity – balances outcomes, diverges on error rates
- Equalized odds – achieves the best trade-off between fairness and performance
Engineering Takeaway
Treat fairness metrics as a non-functional requirement of your model, just like latency or throughput. If your model isn't fair, it's not ready for production.
Transparency and Explainability: Making Models Understandable
The most significant security risk associated with a lack of transparency is the erosion of trust, accountability, and ethical integrity. If the decision-making process or predictions of an AI model cannot be understood, it is nearly impossible to detect and correct biases, verify fairness, or ensure regulatory compliance.
In other words, opaque AI systems become "black boxes" that can facilitate discrimination, reinforce social inequities, and undermine public trust. This challenge is not only an ethical issue but also has practical consequences. Non-transparent models can compromise the reproducibility of results, impede effective governance, and hinder root-cause analysis in the event of failures. This can leave organizations exposed to reputational, legal, and operational risks. In short, the lack of transparency undermines the reliability and legitimacy of AI-driven decisions.
Deep Dive: What You Should Do
- Explain at multiple levels.
- Local explanations: Why did this prediction occur?
- Global explanations: What patterns does the model rely on overall?
- Quantify feature influence.
- Use SHAP to calculate how each feature shifts a prediction.
- Present these values in dashboards or reports that business users can interpret
- Document your model lifecycle.
- Create a Model Card(like a nutrition label for AI):
- Intended use cases
- Training data sources
- Fairness tests performed
- Known limitations
Example: SHAP
Please refer to the git repository Ethical AI Demo for full implementation and interpretation of the waterfall plot.
import shap
#create SHAP explainer
explainer = shap.Explainer(model, X_train)
shap_values = explainer(X_test[:1])
#Generate waterfall plot for a single prediction
shap.plots.waterfall(shap_values[0])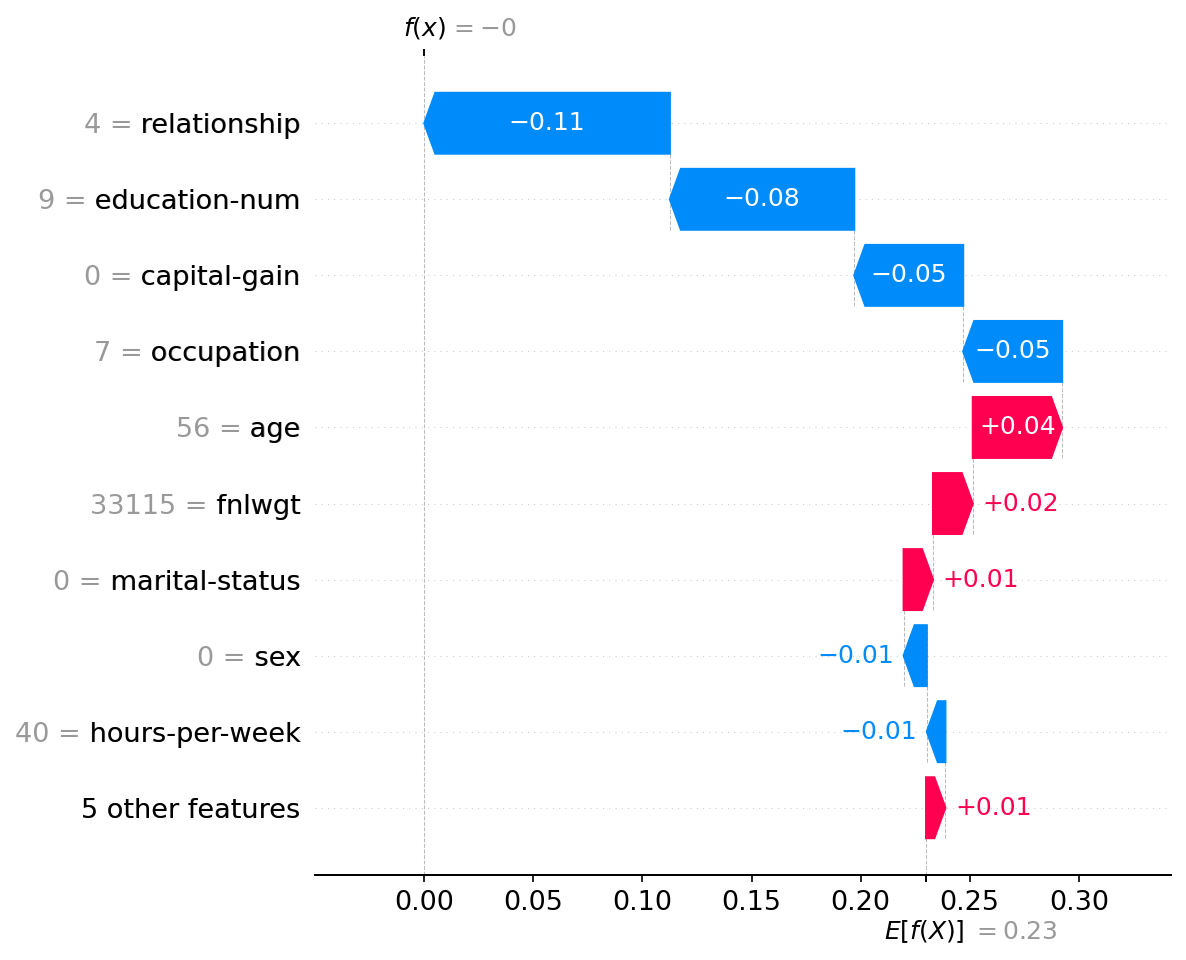
Interpretation: Transparency Aspect
- Explains the black-box model by highlighting all the features ranked by impact.
- Quantifying each attribute's contribution ( -11%, -8%, etc.) to understand how much it matters in model prediction.
- The model can be validated mathematically; every percentage point is traced from the baseline (23%) to the final prediction (0%).
- Here is an example reference on how you interpret this demo result directly with the regulatory compliance.
| Regulation | Requirement | Waterfall Provides |
|---|---|---|
| EU GDPR Article 22 | Right to explanation for automated decisions | Individual-level explanations |
| Fair Housing Act | Cannot discriminate on protected attributes | Reveals proxy discrimination (relationship to gender) |
| EU AI Act (2024) | High-risk AI systems must be transparent and auditable | Full feature attribution |
Engineering Takeaway
If you can't explain it, you can't defend it. Integrate explainability reporting into every release note or dashboard your team ships.
Privacy and Security: Protecting Data and Models
Data privacy and security are always coined together — data privacy is primarily about honoring the user's rights, and data security is about protecting that data from any external attack. Starting from the most obvious attacks like data leaks or exposure to more sophisticated risks like re-identification, model inversion, and membership inference, will expose the most vulnerable truths about modern AI systems: your model can be the very vector of privacy loss.
Models overfitting on your training data or datasets not properly anonymized leak user information and cause irreparable reputational damage. When sensitive data can be reconstructed, linked, or inferred, whether through direct exposure, correlation with external datasets, or reverse-engineering model outputs, the damage cascades far beyond technical failure. It undermines public confidence, invites regulatory scrutiny, and signals a collapse in organizational responsibility. Once trust is lost, even the most accurate model becomes unusable because ethical lapses, not accuracy gaps, are what truly destroy reputations.
Always remember that in Responsible AI, privacy is the bedrock of trust; it is not just a compliance checkbox
Deep Dive: What You Should Do
- Protect the training data.
- Use Differential Privacy (DP) during training to mask individual records.
- Libraries like Opacus (PyTorch) make this simple.
- Distribute learning without centralizing sensitive data
- Use Federated Learning to train on decentralized nodes.
- Implement secure aggregation so no node can infer others' data.
- Secure the model itself
- Test your model against adversarial attacks(e.g., evasion, poisoning).
- Restrict access using role-based permissions in your MLOps pipeline
Example: Reference Implementation With OPACUS
from opacus import PrivacyEngine
from torch import nn, optim
#Simple diagnostic model [e.g disease prediction]
model = nn.Linear(128, 1)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
#Attach differential privacy engine
privacy_engine = PrivacyEngine(
model,
sample_size=10000,
batch_size=64,
noise_multiplier=1.1, #controls strength of noise (ε)
max_grad_norm=1.0 #gradient clipping bound
)
privacy_engine.attach(optimizer)
#training loop now applies DP guarantees automaticallyReal-World Practice
In healthcare, a diagnostic model trained with DP-SGD ensures that no patient record can be reconstructed. Even if model weights leak, privacy holds. A standard training process can overfit and memorize rare samples instead of learning the generalized signals from the dataset. And if someone obtains these model weights, they might reconstruct or infer information about specific patients.
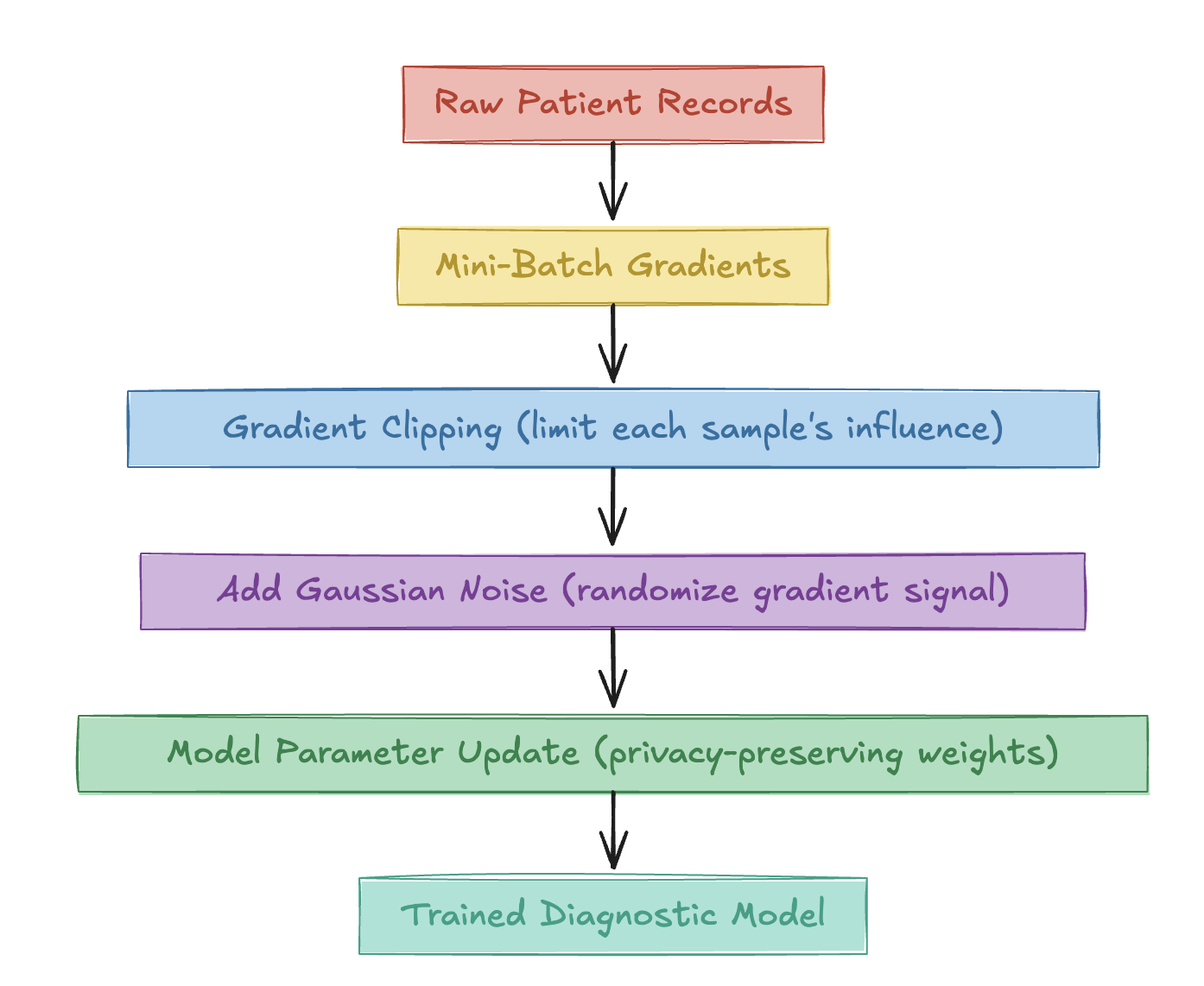
Interpretation
- Raw Patient Records -> Mini-Batch Gradients
- Each training batch computes gradients that represent how much to adjust the model based on those samples.
- Gradient Clipping:
- Each patient's contribution is clipped to a fixed limit so no single record can dominate the update.
- Add Gaussian Noise:
- Random noise is added to the aggregated gradients, blurring any trace of an individual's data.
- Model Parameter Update:
- The model updates its weights using the noisy, clipped gradients resulting in privacy-preserving parameters
- Trained Diagnostic Model:
- Even if those weights leak, they no longer encode exact patient information; they capture only population-level patterns.
Engineering Takeaway
Make "privacy budgets" as standard as "computer budgets". Data protection is not just an Enterprise Security job; it is a developer's design decision.
Accountability and Governance: Making AI Traceable
Privacy, transparency, and fairness build the ethical framework, but governance is enforcement. Ethical values are great, but without governance, they can't enforce themselves. Governance is how we operationalize our principles into measurable, auditable outcomes.
Ethics are the commitment; governance is the follow-through. Principles without processes are just words. Left to their own devices, even the most well-meaning systems will rot, models will wander, and documentation will degrade. Oversight will become lax, not through any malice, but through sheer entropy. Governance gives us the architecture and the accountability to close the loop, to translate our ethics from aspiration into evidence. In other words, ethics tells us what is right. Governance keeps us doing it - reliably, transparently, and over time.
Deep Dive: What You Should Do
- Human-in-the-loop approval
- For high-impact decisions(hiring, credit, healthcare), ensure human review before action.
- Build escalation paths - don't let automation be the final judge. Establish clear escalation paths so that a human reviewer can pause, question, or override a model's recommendation.
- Model traceability - Log
- Dataset hashes - to prove which version of data was used for training or validation.
- Model hyperparameters - to reproduce exact outcomes.
- Fairness and performance metrics per vision - to track whether accuracy and equity move in sync.
- Tools: MLflow, kubeflow.
- Adopt a governance framework.
- Align your practices with NIST AI RMF or ISO/IEC 42001.
- Maintain AI audit trails accessible to the compliance and data science teams alike so that accountability is shared and not siloed.
Example
Assume in your organization's HR screening pipeline, built by an ML classifier, every model retrained automatically logs:
- Fairness scores and hyperparameters
- Dataset lineage and schema versions
If a candidate disputes a hiring decision, the team can reproduce the exact decision end-to-end and explain how the model arrived at it and under what assumptions.
Engineering Takeaway
Accountability means your model is reproducible under scrutiny. If you cannot replay the decision, you will not be able to claim governance.
Sustainability and Social Impact: Scaling Responsibly
By now, we know AI has the potential to help us learn, govern, and innovate better. But it should not cost the Earth to change the world. In a 2019 study, University of Massachusetts Amherst researchers calculated that the CO₂ emissions for training a single large language model can reach more than 626,000 pounds. This is roughly the lifetime carbon footprint of five average American cars. But the problem does not stop there.
Consider ongoing model fine-tuning, 24/7 inference serving, and large-scale data center operations, and the environmental impact balloons further still. If not managed, AI innovation risks becoming a compounding ecological debt machine, scaling at a much more rapid rate than the underlying systems supporting it.
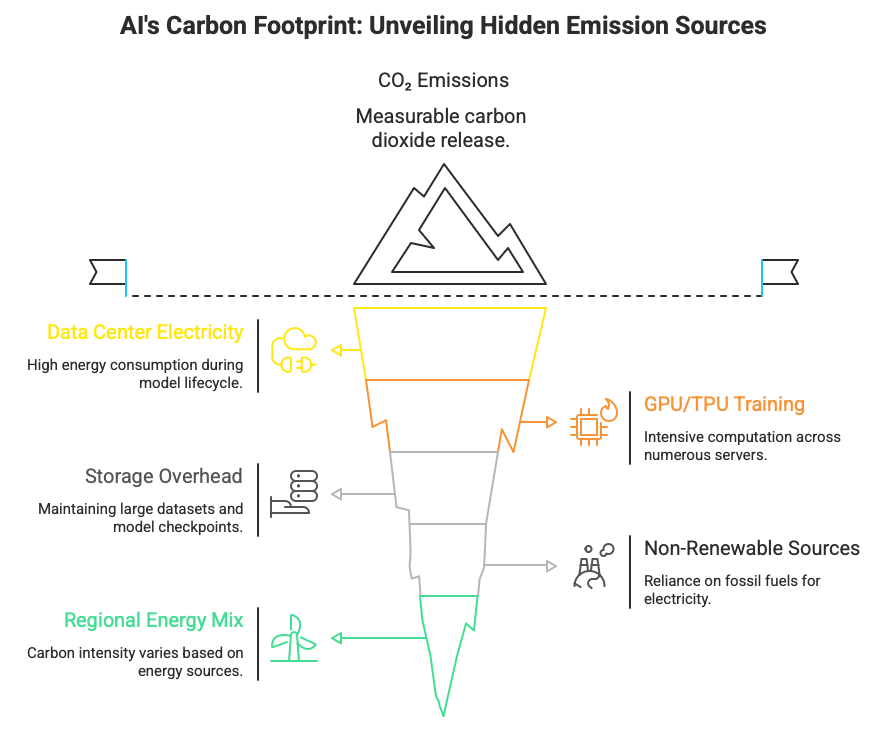
Deep Dive: What You Should Do
- Measure compute and emissions.
- Use tools like CodeCarbon to track energy use, monitor GPU hours, and CO₂ footprint.
- Include these metrics in your model performance dashboards.
- Optimize resource efficiency.
- Apply quantization (e.g: quantized the model from 8-bit to 4-bit precision), neuron pruning, and knowledge distillation to train smaller, faster student models.
Example Reference Implementation: CodeCarbon
Please refer to the git repository Ethical AI Demo for full implementation.
# Example: Measuring training emissions using CodeCarbon
from codecarbon import EmissionsTracker
from transformers import Trainer, TrainingArguments
from datasets import load_dataset
# Initialize the tracker
tracker = EmissionsTracker(project_name="ethicalai-demo")
tracker.start()
# Example model training (using Hugging Face Trainer)
dataset = load_dataset("imdb")
args = TrainingArguments(output_dir="./results", per_device_train_batch_size=8)
trainer = Trainer(model_init=lambda: AutoModelForSequenceClassification.from_pretrained("bert-base-uncased"),
args=args,
train_dataset=dataset["train"].shuffle(seed=42).select(range(2000)),
eval_dataset=dataset["test"].select(range(1000)))
trainer.train()
# Stop tracker and print emissions summary
emissions: float = tracker.stop()
print(f"Estimated emissions: {emissions:.4f} kg CO₂")Interpretation
Results from my local system run here for reference.
| Component | Energy Used (kWh) | Description |
|---|---|---|
| RAM | 0.000196 kWh | RAM draws continuous low power |
| CPU | 0.000031 kWh | Energy consumed by all CPU cores - preprocessing, tokenization, training steps |
| GPU | 0.000958 kWh | GPU consumed roughly 80% of total energy |
| Total Energy | 0.001185 kWh | Combined consumption CPU + GPU +RAM |
| Estimated Emissions | 0.0004 kg CO₂ | This is extremely low |
Notice that the total training energy was just 0.001 kWh, which is 0.0004kg CO₂ (equivalent to the energy of a 10W LED bulb being on for a few minutes). Trivial, sure, but imagine that same workload running thousands of times in production.
In practice, quantization (e.g., to 4 bits) and distillation techniques have been shown by recent work QLoRA (Dettmers et al., 2023) and GPTQ (Frantar et al., 2022) to reduce the cost of inference and memory footprint by 2-4x while achieving near-original performance. It is quite likely that with some additional engineering and model-specific tuning, some deployments may see a GPU consumption in the 50-60% range reduction in production systems.
Engineering Takeaway
In the future, AI excellence will not be measured solely by accuracy or latency, but by how responsibly intelligence is powered. Once again, ethical AI is not only what your model predicts, but how responsibly it learns, runs, and scales.
Conclusion: Making Responsible AI Measurable
Operationalizing Responsible AI translates principles into engineering artifacts. Fairness checks, explainability dashboards, privacy safeguards, governance logs, and sustainability metrics integrate into your pipelines, making ethics measurable and auditable just as you would for performance or uptime.
The next time you ship a model, in addition to asking "Does it work?" you'll also ask, "Does it work fairly, securely, and transparently - today and tomorrow?"
Because real innovation is not just smart — it is responsible, reproducible, and trustworthy.
Opinions expressed by DZone contributors are their own.
Comments