“Just Don’t Put PII in the Prompt” Is a Trap: A Two-Plane Architecture for Safe LLM Apps
Separate Data Plane (sensitive data/actions) from Prompt Plane (sanitized context). Use IDs + summaries so secrets never enter prompts.
Join the DZone community and get the full member experience.
Join For FreeWhy “Just Don’t Put PII in the Prompt” Doesn’t Work
Mobile teams typically start with good intentions: redact emails, don’t log raw text, and avoid sending sensitive fields to an LLM provider. Then reality hits:
- Debug logs capture prompts “temporarily” (and become permanent).
- RAG pulls in internal documents that contain secrets.
- Tool calling expands scope: the model can “ask” for more data.
- Engineers add “one more field” to improve answers.
- A prompt injection attempt convinces the model to request sensitive content.
The core problem is that the prompt becomes a dumping ground for whatever might help the model. Once you do that, you’ve lost control of data boundaries.
In practice, prompts sprawl under delivery pressure, and every exception becomes precedent until a leak becomes a real incident later.
The architectural alternative is simple: move sensitive operations out of the prompt and into a controlled data subsystem.
The Two-Plane Model
Prompt Plane (LLM-Facing)
The Prompt Plane is everything that touches model inputs/outputs:
- prompt builder
- retrieval context assembly
- “assistant” response formatting
- structured output parsing and validation
Rule: The Prompt Plane gets minimal, prompt-safe context — never raw secrets.
Data Plane (Sensitive-Data-Facing)
The Data Plane is where sensitive data lives and where privileged actions happen:
- customer records
- payment instruments
- tokens/keys
- internal documents and entitlements
- write actions (create ticket, change address, refund, etc.)
Rule: The Data Plane is the only place that can access sensitive data, and it’s protected by standard controls (authZ, auditing, encryption, least privilege).
A Reference Architecture You Can Ship
Here’s the production pattern that works across mobile and server:
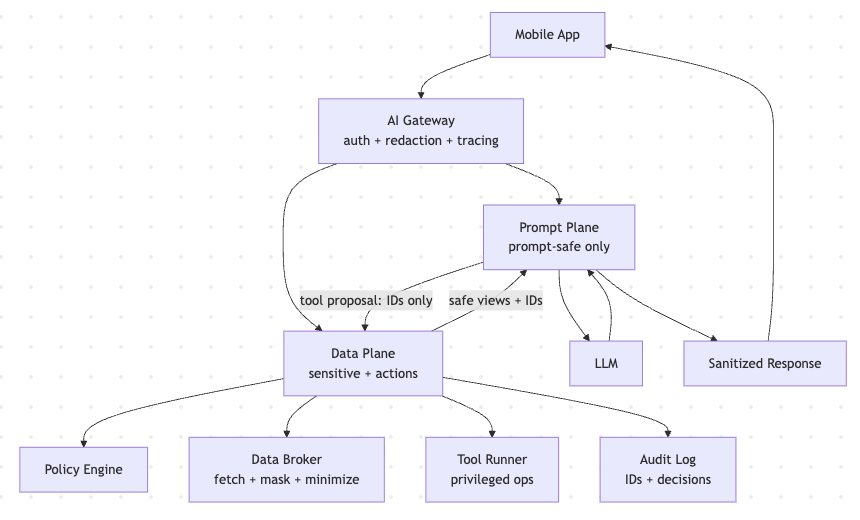
The gateway is your enforcement point: it ensures nothing goes to the model unless it’s allowed and minimized.
The “join-on-ID” Pattern (The Key Trick)
A secrets-safe app avoids putting raw records in prompts. Instead, it uses IDs and derived views.
- Prompt Plane sees: “Order
ORD-8392is delayed by 2 days; customer tier: Gold; refund eligible: Yes/No.” - Data Plane holds: Customer name, address, payment token, full order contents, internal notes.
When the model needs an action, it proposes something like:
-
refund_order(order_id="ORD-8392", amount=12.99, reason="late delivery")
Then the Data Plane:
- checks policy (eligible? user allowed?)
- fetches the real payment token internally
- executes the refund
- returns a sanitized result (“Refund initiated, reference #…”) to the Prompt Plane
The model never touches secrets, yet the user still gets a smooth AI experience.
A Secure Request Flow (End-to-End)
- User request arrives (mobile → gateway).
- Intent classificationdecides whether sensitive data is needed:
- “Explain refund policy” → no sensitive data
- “Refund my last order” → sensitive access required
- Data Plane generates a prompt-safe context:
- fetch only the minimum fields
- mask or summarize sensitive values
- attach stable IDs, not raw records
- Prompt Plane calls the LLMwith:
- task instructions
- prompt-safe context
- strict output schema (typed tool calls)
- LLM produces either:
- an answer grounded in safe context, or
- a tool proposal referencing IDs
- Tool runner executes in the Data Plane:
- policy check + entitlements
- least-privilege credential usage
- audit record created
- Response returns to the user with sanitized results and no secret spill.
This flow also makes prompt injection far less scary: even if the model is coerced, it can’t “leak” what it never received.
Guardrails That Make the Split Real (Not Just a Diagram)
1. Policy Before Data
Every Data Plane fetch goes through a policy engine:
- tenant isolation
- user role and consent
- feature-level rules (what this screen can access)
2. Prompt-Safe Views (Explicit Contracts)
Define “safe” DTOs like:
CustomerSummary: tier, last order ID, eligibility flagsPaymentStatus: success/fail + reason codes (no PANs, no tokens)DocSnippet: approved excerpt + doc ID/version
If it’s not in a safe view, it can’t enter the prompt.
3. Capability Tokens For Actions
When the model proposes an action, require a short-lived, scoped capability:
- bound to user + feature + resource ID
- expires quickly
- one tool, one purpose
4. Audit-Safe Logging
Log:
- request IDs, tool names, policy decisions, resource IDs
Not:
- raw prompts, raw retrieved chunks, full user text (unless you have a protected pipeline)
Mobile-Specific Considerations
- On-device redaction: Scrub obvious PII before requests leave the device (emails, phone numbers). Still enforce server-side redaction too.
- Local caches are dangerous if they store sensitive prompt content. Cache IDs + timestamps, not full prompts.
- Debug builds leak: Ensure dev logging doesn’t accidentally ship to production analytics.
- Offline mode: Keep offline AI features strictly within on-device safe context; don’t queue raw sensitive prompts for later upload.
Common Mistakes (and How This Architecture Prevents Them)
- Putting JWTs, session tokens, or device identifiers in prompts. Data Plane handles auth; Prompt Plane never sees tokens.
- RAG that retrieves “internal wiki pages” with secrets. Retrieval runs in the Data Plane with allowlisted corpora and safe snippets only.
- Tool outputs are returned verbatim to the model. Tool runner returns sanitized, minimal results.
- “Temporary logging” of prompts for debugging. Audit logging uses IDs and decisions; prompt content is minimized by design.
Implementation Checklist
- Define Prompt Plane vs. Data Plane ownership boundaries in code and reviews.
- Build prompt-safe DTOs and ban raw domain objects in prompts.
- Enforce policy checks on every sensitive fetch/action.
- Use IDs + derived summaries (“join-on-ID”) instead of raw records.
- Validate typed tool calls; reject anything outside the schema.
- Sanitize tool outputs before sending back to the model.
- Log decisions and IDs, not raw sensitive content.
Takeaways
If your LLM feature depends on “we’ll be careful,” it will eventually leak. A two-plane architecture makes safety repeatable:
- Data Plane: sensitive access, actions, policies, auditing
- Prompt Plane: minimal context, generation, strict schemas
You don’t need perfect prompts. You need bounded systems.
Opinions expressed by DZone contributors are their own.
Comments