Building a Scalable and Reliable Marketing Data Stack on GCP
A resilient marketing data stack on GCP leverages BigQuery, Pub/Sub, and Dataflow to deliver real-time insights, handle schema drift, and scale analytics.
Join the DZone community and get the full member experience.
Join For FreeCreative campaigns are no longer modern marketing; data is. And not any data: clean, contextual, and timely data that fuels specific, personalised experiences that enable quantifiable outcomes. If you have dozens (or hundreds) of campaigns running across platforms such as Google Ads, Meta, and programmatic DSPs, the infrastructure that enables this orchestration is just as important as the insights themselves.
Today, scaling a marketing data stack is not about selecting a BI tool or lifting a few datasets to the cloud. It’s about architecting a resilient foundation on GCP that can ingest campaign data from multiple sources, support time-zone distributed teams, and power real-time dashboards, all while maintaining governance and operational reliability.
Real-Time Insights: A Survival Feature
Marketing operations have compressed decision cycles. A campaign performance drop on Thursday morning can have repercussions well into Friday afternoon. This implies that batch-based ETL systems like runners, which can only run once or twice daily, are insufficient.
In our deployment, we used BigQuery’s native streaming ingestion APIs to query for displaying real-time dashboards seconds after new ad events hit our system. This combination of data from Funnel.io is piped into Google Cloud Storage, with App Script functions to orchestrate simpler, lightweight transforms, and then is pushed to partitioned BigQuery tables. This setup enabled the analytics layer (using Looker Studio) to automatically power the cost overruns alerts and reach gaps, mimicking real-time campaign fluctuations.
Real-time dashboards transformed from reporting tools to operational control panels by analyzing hundreds of concurrent campaigns for multiple clients.
ETL Resilience Means Designing for Platform Drift
Campaign APIs are unpredictable. Platform changes, throttling limits, and schema shifts are the common ones. And yes, the speed of a modern marketing stack doesn’t matter; it’s not its ability to scale quickly, but how it fares when it crashes.
For our ETL pipelines on GCP, we ran and scheduled our Dataform and scheduled query into BigQuery with retry buffers and error queues via Pub/sub. Several daily jobs started failing silently soon after Meta Ads introduced changes to field availability in early 2023. As such, we then implemented schema registry auditing by writing metadata tables that would compare an expected field type with an actual field type prior to jobs running. The generic handler fallback was introduced to minimize data loss when detecting a mismatch.
Treating ETL as an evolving (rather than a static) interface enabled our stack to heal minor problems and escalate major ones with full context. In this way, our pipelines were both the product interface, as much as they were inside, hard at the edges, and adaptive inside.
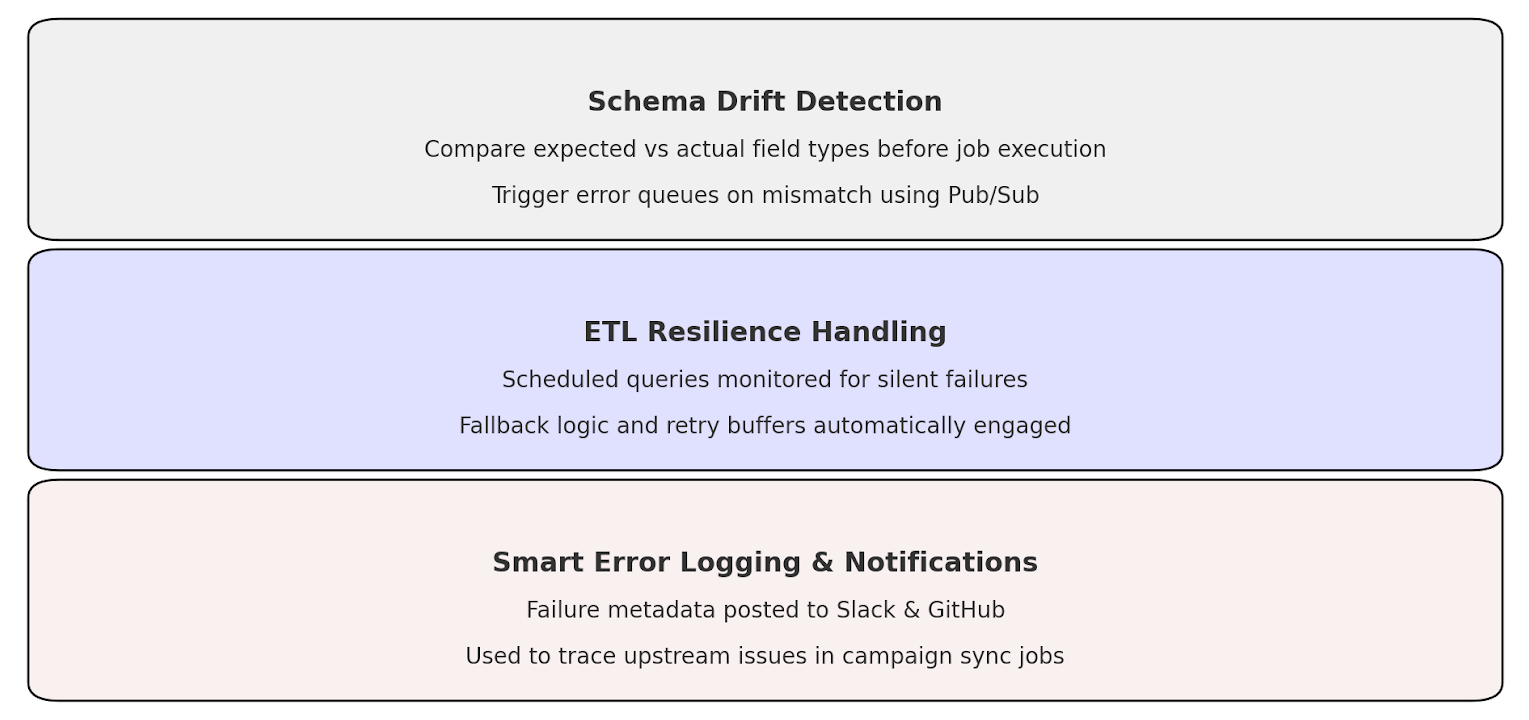
This shows how schema drift handling, retry logic, and error queues enable fault-tolerant pipelines in a GCP-based marketing stack.
How Metadata-Driven Contracts Reduce Attribution Chaos in ETL
Today, alignment is one of the more overlooked challenges in cross-platform campaign data. Google Ads uses last-click attribution, and Facebook reports conversions based on attribution windows. In raw logs, DSPs can mix impressions with engagement. It’s not just something as technical as mapping schemas; it’s about reconciling the meaning between the two.
Next, we built an ETL orchestration layer based on metadata. Every pipeline contract defines the expected input, business definition, and validation rules. A new campaign event wouldn’t just be processed; it would have to be validated against the event dictionary, enriched with campaign context, and normalized using predefined attribution models.
This enabled automated campaign diagnostics. Given the example, the system could have traced lineage down to the busy overlaps, or just days on pacing, of a campaign that underperformed. The automated resolution here was not simply re-running jobs, but recontextualizing data to guide the root cause analysis.
Scaling Data Ops Without Breaking the Team
Running scalable pipelines doesn’t mean hiring a dozen engineers. In other words, it boils down to understanding common workflows when changing, enforcing structure, and using GCP’s managed services rather than reinventing everything. The Cloud Scheduler jobs ran segmentation and enrichment logic, which were stored procedures. Complete lineage was posted to Slack for failures (and cross-posted to GitHub), and we monitored audit logs for BigQuery usage to optimize cost.
In this case, our lean data team could manage multi-terabyte datasets across more than one client without manual babysitting. Data engineering became productized, not reactive.
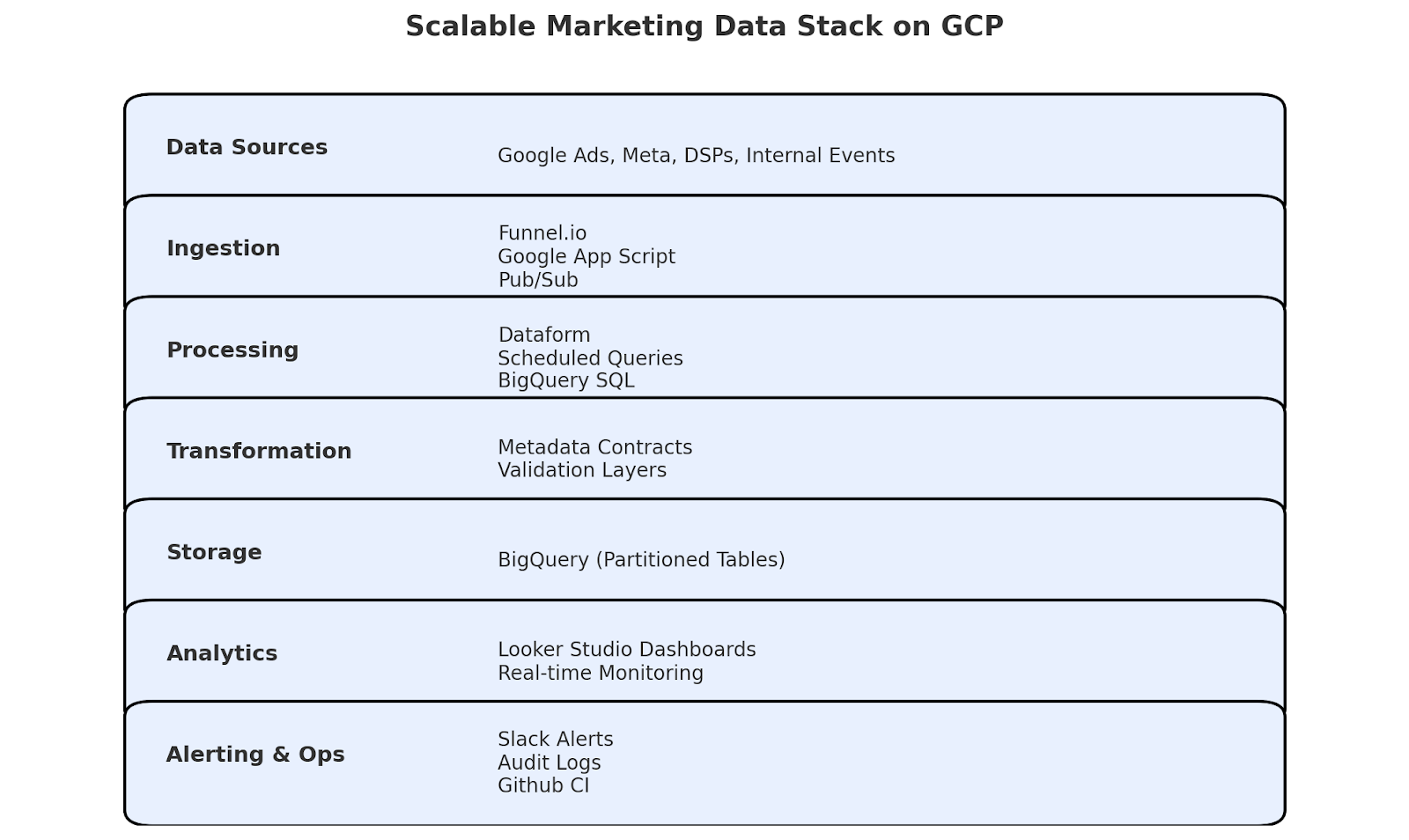
This visualizes the data pipeline from ingestion to real-time analytics using GCP tools like BigQuery, Pub/Sub, and Looker Studio.
Real-Time Resilience in Action: How The New York Times Scaled With GCP
The New York Times perfectly exemplifies how scalable resilience translates into high-pressure environments. When the Newspaper rebuilt its data infrastructure on Google Cloud Platform, it wasn’t only about performance and reliability in the face of extreme, real‑world pressure.
During major news events, their on-prem Hadoop environment had enormous query latency, inconsistent ingestion, and fragile streaming. NYT was able to switch to a real-time, event-driven data stack that could run on top of 273 million global readers during the 2020 U.S. elections with one single data drop using GCP’s BigQuery, Dataflow, Pub/Sub, and App Engine.
This move allowed for faster analytics and editorial agility, enabling the newsroom to create a personalized experience and respond in real time to user behavior. The team was able to work with audience insights, campaign targeting, and content strategy, while GCP’s managed services eliminated manual data wrangling.
With this transformation, you have an example of what a marketing data stack should deliver: automated scale, query precision, and operational calm even at peak demand.
Conclusion
Creating a marketing data stack on GCP is about having elastic infrastructure available in real time and a structure that allows us to create a system offering real-time insights, automatic resiliency, and business-aligned scalability. As The New York Times proves, it’s not about getting through peak loads and chaotic campaign launches; it’s about getting more out of them.
Cloud-native architectures such as BigQuery, Dataflow, and Pub/Sub allow teams to transform from reactive reporting to proactive decision-making through behavioral analytics and operational automation. A GCP-based data stack is technically an upgrade, but done well, it becomes a strategic asset.
Opinions expressed by DZone contributors are their own.
Comments