How to Implement Fuzzy Search (Google's Autocomplete Search) in Java
Join the DZone community and get the full member experience.
Join For FreeApproximate String Search
Approximate String Search, Fuzzy Search, search with mistakes — there are many names for this one problem. In this article, I'll show you two ways to implement a search that takes potential misspelling into account.
Example of the Problem
A user types a company name with a mistake: Tetla, Aptle, Cola Koca, Mikrosoft, and the application returns the correct company name and similar companies (if any exist):
| User query with mistake | Expected result |
| Tela | Tesla |
| Apptle | Apple |
| Cocakola | CocaCola |
| Mikrosoft | Microsoft |
Spell Checker Algorithm Described by Google's Director of Research
Peter Norvig described an algorithm similar to Google's search spell checker in this article. I've changed the provided Java implementation according to the requirements set in this article. You can find the full source code here.
I've changed it a bit to fit our needs. In the dictionary, we add our four companies and after test it:
public class Spelling {
private static final String ABC = "abcdefghijklmnopqrstuvwxyz";
private static Map<String, Integer> dictionary = new HashMap<>();
private static String DICTIONARY_VALUES = "Tesla,Apple,Microsoft,CocaCola";
public static void main(String[] args) {
Stream.of(DICTIONARY_VALUES.toLowerCase().split(",")).forEach((word) -> {
dictionary.compute(word, (k, v) -> v == null ? 1 : v + 1);
});
System.out.println("Correction for Tela: " + correct("Tela"));
System.out.println("Correction for Apptle: " + correct("Apptle"));
System.out.println("Correction for Cocakola: " + correct("Cocakola"));
System.out.println("Correction for Mikrosoft: " + correct("Mikrosoft"));
}
private static Stream<String> getStringStream(String word) {
Stream<String> deletes = IntStream.range(0, word.length())
.mapToObj((i) -> word.substring(0, i) + word.substring(i + 1));
Stream<String> replaces = IntStream.range(0, word.length()).boxed().flatMap((i) -> ABC.chars()
.mapToObj((c) -> word.substring(0, i) + (char) c + word.substring(i + 1)));
Stream<String> inserts = IntStream.range(0, word.length() + 1).boxed().flatMap((i) -> ABC.chars()
.mapToObj((c) -> word.substring(0, i) + (char) c + word.substring(i)));
Stream<String> transposes = IntStream.range(0, word.length() - 1)
.mapToObj((i) -> word.substring(0, i) + word.substring(i + 1, i + 2) + word.charAt(i) + word.substring(i + 2));
return Stream.of(deletes, replaces, inserts, transposes).flatMap((x) -> x);
}
private static Stream<String> edits1(final String word) {
return getStringStream(word);
}
private static String correct(String word) {
Optional<String> e1 = known(edits1(word)).max(Comparator.comparingInt(a -> dictionary.get(a)));
if (e1.isPresent()) return dictionary.containsKey(word) ? word : e1.get();
Optional<String> e2 = known(edits1(word).map(Spelling::edits1).flatMap((x) -> x))
.max(Comparator.comparingInt(a -> dictionary.get(a)));
return (e2.orElse(word));
}
private static Stream<String> known(Stream<String> words) {
return words.filter((word) -> dictionary.containsKey(word));
}
}
The algorithm is working as expected. For our inputs, we get the right correction: Tetla: tesla, Aktle: apple, CokaCola: cocacola, Mikrosaft: microsoft.
Unfortunately, this implementation doesn't support complex cases and therefore isn't ready for production. Let's take a look into the next, much more powerful solution.
Apache Solr
Solr is an enterprise-search platform based on Apache Lucene. Solr has an embedded search that supports this misspelling feature. This project is a part of the Apache open source software foundation, so you can use it for free.
Installation
- Download and extract apache solr.
- Create new core:
solr create -c my_new_core - Change solr\solr-8.4.1\server\solr\newcoretest\conf\solrconfig.xml. Find xml with DirectSolrSpellChecker and change value of field from _text_ to name.
xxxxxxxxxx
<str name="field">name</str>
<str name="classname">solr.DirectSolrSpellChecker</str>
Start Solr on the command line with: solr start (execute administration mode). Then, create an empty Java project and http://www.apache.org/ with a Maven dependency:
xxxxxxxxxx
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>6.4.0</version>
</dependency>
After this step, the default spell check configuration will use the field, "name", in all documents.
Writing Search Application With Spelling Suggestions
Initialization HttpSolrClient:
xxxxxxxxxx
String urlString = "http://localhost:8983/solr/my_new_core";
HttpSolrClient solr = new HttpSolrClient.Builder(urlString).build();
solr.setParser(new XMLResponseParser());
Adding documents to my_new_core
xxxxxxxxxx
Arrays.asList("Tesla", "Apple", "Microsoft", "Coca Cola").forEach(companyName -> {
try {
SolrInputDocument document = new SolrInputDocument();
document.addField("name", companyName);
solr.add(document);
solr.commit();
} catch (Exception ignored) {}
});
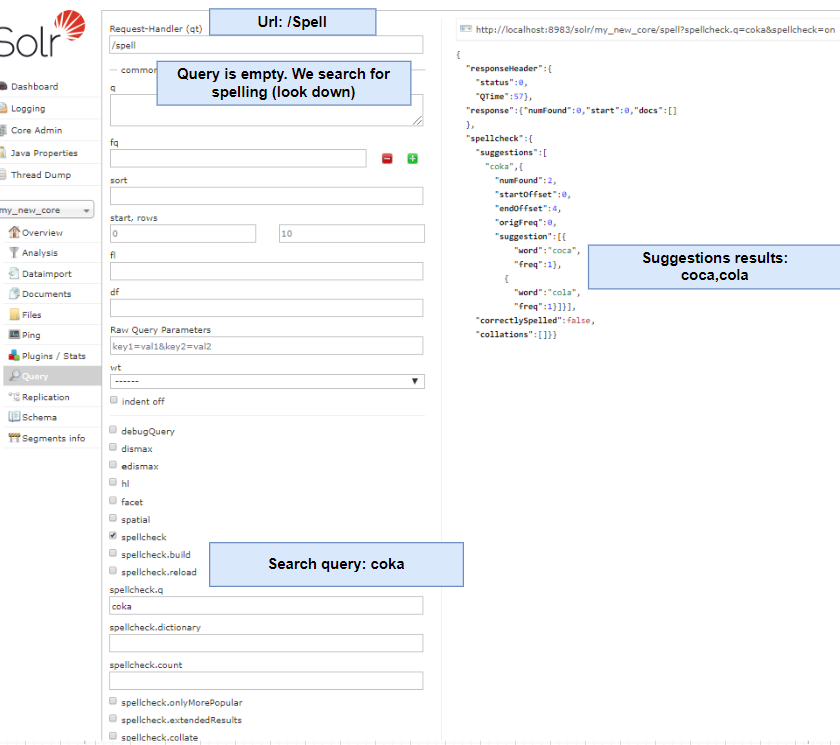
Requesting spelling suggestion request for word "coka":
xxxxxxxxxx
SolrQuery params = new SolrQuery();
params.set("qt", "/spell");
params.set("q", "coka");
params.set("spellcheck", "on");
params.set("spellcheck.build", "true");
QueryResponse response = solr.query(params);
List<SpellCheckResponse.Suggestion> suggestions = response.getSpellCheckResponse().getSuggestions();
for (SpellCheckResponse.Suggestion suggestion : suggestions) {
for(String alternative: suggestion.getAlternatives()){
System.out.println("suggestion for coka:" + alternative);
}
}
For the requested word, "coka", the engine returns an existing word in our library (not documents):
suggestion for coka:coca
suggestion for coka:cola
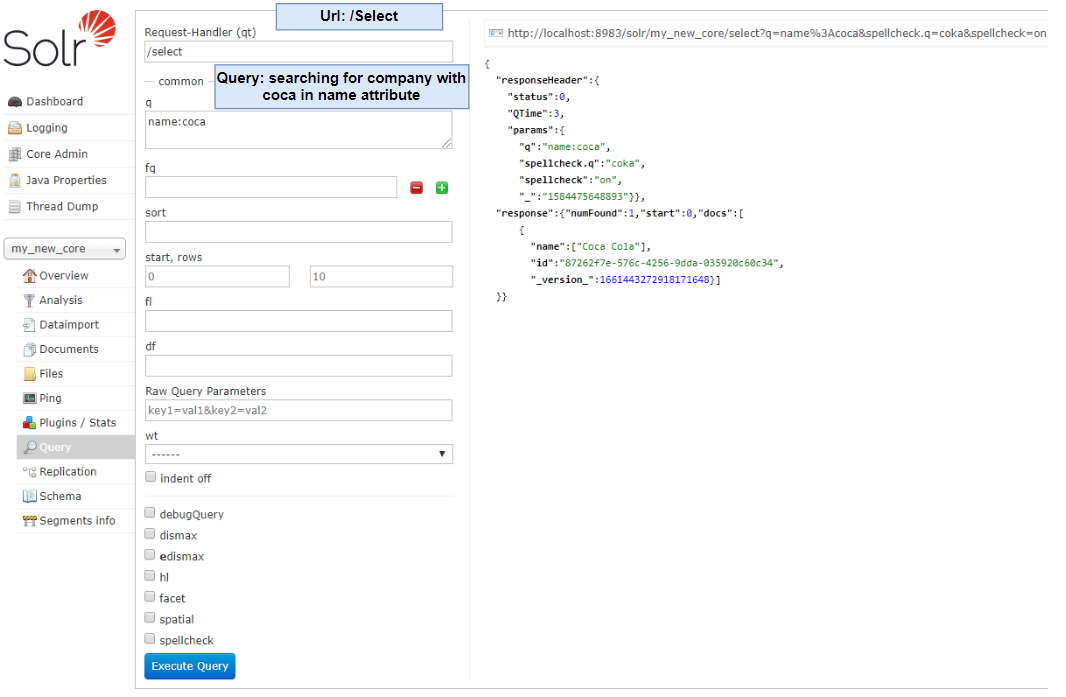
Finally, searching for one of the matched suggestions: "coca"
xxxxxxxxxx
SolrQuery params = new SolrQuery();
params.set("qt", "/query");
params.set("q", "name:" + "coca");
params.set("spellcheck", "on");
params.set("spellcheck.build", "true");
QueryResponse response = solr.query(params);
for (SolrDocument document: response.getResults()){
System.out.println("Matched document: " + document.getFieldValue("name"));
}
Result of execution:
Matched document: Coca Cola
Solr Search Web Interface
For debugging purposes, you can use Solr's web interface. The default address is http://localhost:8983/ .
Spell check request example — searching for "coka" suggestions.
Searching for a specific company name that contains "coca":
The Solr configuration requires time to learn. It's painful at the very begging.
Alternative to Solr: Elasticsearch
Elasticsearch is a known alternative to Solr. It is more powerful but the full version is paid, and the free version has some limitations.
Opinions expressed by DZone contributors are their own.
Comments