Securing Your Cloud-Native Journey
Going cloud-native has its own advantages and challenges; this article should help you tackle your cloud-native journey and the challenges associated.
Join the DZone community and get the full member experience.
Join For FreeIf you have embraced the concept of cloud-native computing and principles, you are ahead; you are on the right path in today’s advanced and competitive IT environment. But we need to understand one thing that, moving your development environment and processes to a cloud-native environment can be daunting and challenging. Anybody can merely advise you to move from a monolithic application to a microservices architecture, but from where and how are the questions that need critical analysis.
Modernizing legacy applications is a bit trickier. You should approach this gradually, starting by containerize parts or all of an existing application without adopting a microservices architecture. From here, you can slowly integrate modern DevOps and cloud methodologies like CI/CD, automation, and observability, step by step. At a certain point, you will either be adding new microservices on top of your existing legacy apps/service, or you will be killing-off services from the monolithic codebase. But that is just the simple theoretical aspect of moving towards the cloud-native journey. What about security?
In this blog, we will discuss more in detail about the security aspects involved in the cloud-native journey and how to solve them.
How cloud-native started?
Almost ten years ago, the term 'cloud-native' was coined by the company Netflix, that leveraged cloud and computing technologies. That gave a boost to the company that transformed itself, going from a mail-order company to one of the world’s trusted and greatest consumer on-demand content delivery networks on earth. Netflix pioneered cloud-native tech, and taught a lot of useful lessons being the first mover on reinventing, transforming, and scaling how we all should be doing software development.
With the help of cloud-native technologies, Netflix was able to deliver more features faster to its customers, and from that point, every company that deals with software wants to more cloud-native tech stories from Netflix. The cloud-native approach is a way to increase the velocity of your business and a methodology to take advantage of the automation and scalability that cloud-native technologies like Containers, Docker, Kubernetes offer.
What does the cloud-native journey look like?
It all comes down to three critical decisions that need to be addressed here in the cloud-native approach.
What is the infrastructure?
One of the essential requirements here is that the computer needs to be elastic. Then there are other capabilities that the infrastructure needs to support, like observability, visibility, a couple of managed services, etc. Infrastructure is a vast topic to discuss, I will be doing another blog on this in detail.
What platform to choose?
The decision is easy to make here as the choice is obvious; Kubernetes has become a defacto platform to run containerized microservices. [Reference a Kubernetes blog]
How to effectively and securely run containerized microservices?
This is a bit of a complex decision to make, and Helm comes handy here. Helm is one of the ways to install services on Kubernetes in a simpler and a reusable way. The choices that we make here helps developers to focus on the business problems and not to worry about the baggage of platform requirements, etc.
These three are the key decisions to make, and this is where your cloud-native journey starts.
Becoming cloud-native is a journey, not a destination.
There are multiple steps a company can take to begin and progress on this journey.
Cloud-native’s fundamental principles include scalable apps, resilient architectures, and the ability to make frequent changes.

Image credits: This is a slide taken from Karthik Gaekwad's presentation at Cisco Devnet Create in April 2019.
Three phases I would like to mention in the journey.
Phase I > Developer Focus > Container Adoption
Phase II > DevOps Focus > Application Deployment
Phase III > Business Focus (end-to-end)> Intelligent Operations
Vodafone presented its Cloud-Native journey in the Cloud-Native World.
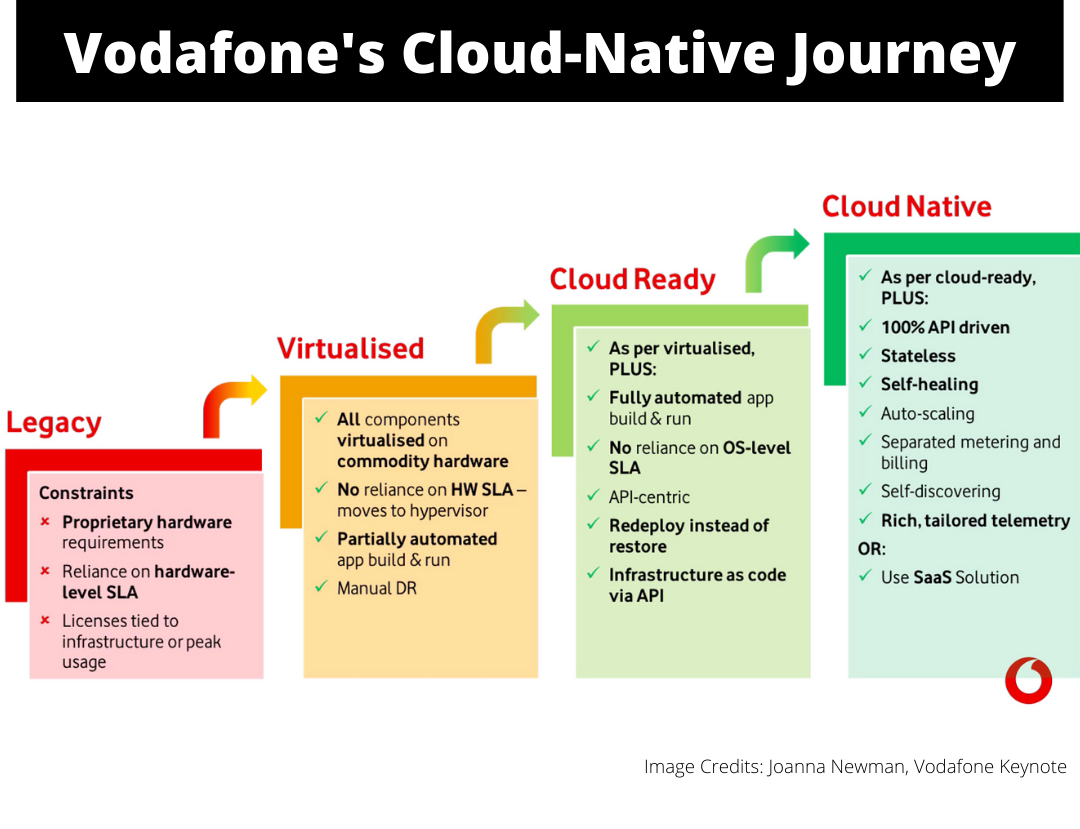
The Vodafone adopted an approach with “Cloud-Ready” as an intermediate step.
This "Cloud-Ready" step was to become more API centric, automate app build & run, remove OS reliance, and adopt Infrastructure as a Code (IaaC) via API.
The IT side of Vodafone seems far more mature than the network side. Most of the IT functions were already in the “Cloud-Ready” stage, but re-architecting the VNFs to containerize and make them cloud-native was one of the challenging tasks.
Checkout Vodafone's cloud-native journey in-depth: 'Vodafone's cloud-native journey: A mix of old school and new'
Common challenges faced on the cloud-native journey
Securing the entry points:
The most important thing is to secure the network. Have a VPC, use NAT (NAT is used to control Egress, just to make sure that none of the IP addresses or nodes or objects are not leaked out). Use RBAC, private network, etc. and these are needed to make sure that everyone can't access the API server, which is running in a Kubernetes cluster. Use namespaces while running containerized microservices on Kubernetes. So it all comes down to monitoring and controlling the entry points.
Specify secrets:
Sensitive information is key and hence needs to be encrypted thus secrets are always preferable. One of the good patterns is to externalize secrets while planning or to design your Helm charts. Then the use of limits, limits are key to contain any abuse within the cluster, and then comes the security context, and it should be a specified set of policies. And then the network policies is another way to contain abuse.
Know the microservices footprint:
If you have microservices running on the selected platform and on the selected infrastructure, it is good to know the entire footprint if you are deploying an application by a Helm chart. A couple of pods are spin-off, in the pod, you can have a main container and an init container, also have a side-car running. You can have multiple replicas of these pods and can also have dependencies as well. Maybe you need a database to run, maybe you need another microservice to run in the same cluster, and again, that dependency may have a main container and can have a side-car container.
Observability:
Microservices are the basis of cloud-native architecture, but when you break apart your monolithic application, you create dozens or hundreds of micro-applications. Each of these micro-applications requires to be observed and monitored, and it is a big challenge.
Since many microservices are involved in building modern cloud-native applications - rapid provisioning, deployment, continuous delivery, stringent DevOps practices, and a holistic approach to monitoring and observability are necessary.
With observability, you will see what your microservices are doing, which can assure you of their performance and behavior. It is highly essential to have tools to know your system's health and functionality as a whole.
Logging has been considered the conventional method used since the start of programming as observability and monitoring metrics, but that is not sufficient for cloud-native applications.
It is important how much you can able to observe what is happening within the systems. It is essential to have modern monitoring tools, SLA, and to understand the extent of how robust is your service level, how quickly you can resolve issues, warnings, and mean time to resolution.
At JFrog, the community centers like GoCenter and ChartCenter are built with many microservices. All these services have health checks built by default into the code as a good practice of observability.
How to deploy apps on K8S in a repeatable way?
Take, for example, we have installed Redis today on a Kubernetes cluster, and the question is, can I reuse my install piece and run it 100 times, and still can I get the same output? If the answer is a NO, then there is a security issue. Along with security issues, its a maintenance nightmare. With Microservices, reusability is key, and not knowing where the dependencies are coming from, then there is a big issue.
So, how do you tackle this issue? The answer is simple - use a package manager, use Helm. Helm is one of the ways to encourage reusability and repeatability. So, there are Helm charts and Helm chart versions to achieve repeatability.
But, is it really true? Does the Helm ecosystem guarantee repeatability?

Above mentioned are some serious questions and more connected towards the security issues. So, with good pros, there are also serious cons involved in the Helm ecosystem.
With Kubernetes becoming the de-facto container orchestration platform for companies navigating through the cloud-native journey, Helm makes it easy for applications to be installed and upgraded in a repeatable fashion as discussed above. Even though ‘Kubernetes + Helm’ combo is a way to get started on the cloud-native path, there was a lack of security aspect, and this need to continuously secure the cloud-native ecosystem is fulfilled by ChartCenter.
ChartCenter can be a solution to secure the cloud-native ecosystem by providing public Helm charts in a repeatable fashion and at the same time, be able to contain the spread of ever-increasing security concerns.
JFrog ChartCenter allows a secure and reliable source for Helm charts of publicly available K8s apps. There’s no standard for producers to share security mitigation or advisory notes with consumers in the cloud-native ecosystem. We have addressed this problem by proposing a standard that helps producers provide security mitigation information with Helm charts. Once the author presents security mitigation information, it also influences when and what high CVEs are represented on ChartCenter’s Security tab.
Noting down some unique ChartCenter differentiators,
1. Central repo for artifact distribution allows for easy client setup and traceability
2. Highly available and scalable service provides confidence to run production services reliably. The immutability aspect furthermore ensures the charts you use will always be accessible even if the source author deletes it
3. The superior search allows us to quickly find the right chart based on namespace, name, description, and tags.
4. Upstream dependencies - Installing Helm charts results in pulling in container images and other sub-charts that may contain security and license issues, deprecated artifacts, or outdated library dependencies. Having this vital information readily available for production deployments is essential.
5. As charts evolve rapidly, knowing who might be impacted by the changes helps to promote stability and trust. Chart owners find this useful to support backward compatibility and manage breaking changes.
6. Security & Mitigation - ChartCenter runs continuous scans of 1.8M components in 12k+ Docker images being referred by 30k+ Helm chart versions. And this valuable information is what’s displayed on Chartcenter’s Security tab for every public Helm chart repository.
[Try ChartCenter]
Every company these days wants to fasten their software releases with quality and utmost reliability. The cloud-native approach gives that confidence for companies to release fast with quality. Platforms like Kubernetes and Helm have evolved big time, and both are helping software companies to utilize the power of cloud-native principles such as modern CI/CD, microservices, etc. But going cloud-native has its advantages and challenges; the points mentioned in this article should help you tackle your cloud-native journey and the challenges associated.
Published at DZone with permission of Pavan Belagatti, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments