Serverless Apache Spark: Data Flow Cloud Service
Oracle recently introduced the serverless Spark Execution Engine, which allows users to now quickly spin up and deploy their Spark applications.
Join the DZone community and get the full member experience.
Join For Free Apache Spark is a technology that is very close to becoming the industry standard among distributed big data processing platforms. It is possible to encounter Spark in almost every company working on big data. We can use this technology, which is widely used with the support of performance and many programming interfaces, in our on-premises systems as well as the interfaces opened by cloud providers.
Apache Spark is a technology that is very close to becoming the industry standard among distributed big data processing platforms. It is possible to encounter Spark in almost every company working on big data. We can use this technology, which is widely used with the support of performance and many programming interfaces, in our on-premises systems as well as the interfaces opened by cloud providers.
 In the past few weeks, Oracle added another one to its cloud services and launched the serverless Spark Execution Engine infrastructure on the Oracle Cloud infrastructure, and this service was designated as Data Flow. Now, users who want to use Spark can easily and quickly raise their Spark Execution Engines and deploy their applications to this environment.
In the past few weeks, Oracle added another one to its cloud services and launched the serverless Spark Execution Engine infrastructure on the Oracle Cloud infrastructure, and this service was designated as Data Flow. Now, users who want to use Spark can easily and quickly raise their Spark Execution Engines and deploy their applications to this environment.
Oracle Cloud Infrastructure Data Flow service has many advantages. Since this service is a cloud-based service, it has a platform that has almost no infrastructure management needs. The service is completely managed by Oracle on the cloud. In addition, a platform has been created in which we can easily export and deploy our existing Spark applications that stand on any platform. Besides, its operation with pay-as-you-go infrastructure provides a very flexible pricing option to Spark users.
There are many connection options where Oracle Cloud Infrastructure Data Flow service can exchange data. These can be Object Storage and Autonomous Database services on OCI as well as third party RDBMS systems. In addition, Cloud Native Security support ensures that this environment is a reliable infrastructure as high as possible.
We have a lot of options while deploying applications into the Data Flow service. Python, Scala, SQL, and Java have currently supported programming language infrastructures. We can deploy Spark solutions that we have developed with these language options to this service.

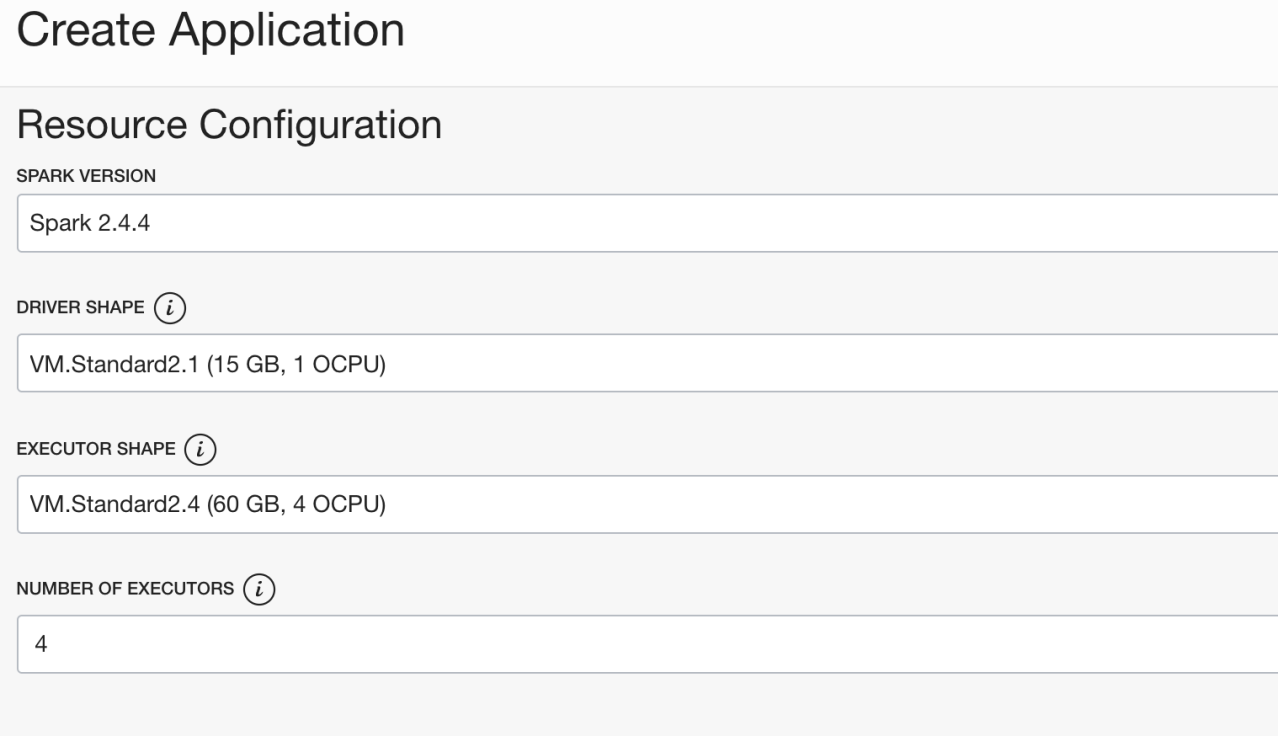
Data Flow service is a virtual machine-based cloud service. While deploying our application in this service, we can ensure the operation of our application with highly flexible virtual machine options with different hardware specifications. We can determine the specifications of both our Driver and Executor separately.

After making the necessary settings of our applications (input and output parameters can also be given from outside), we can successfully perform the deploy operation. After this stage, we can run your application and follow it via SparkUI.
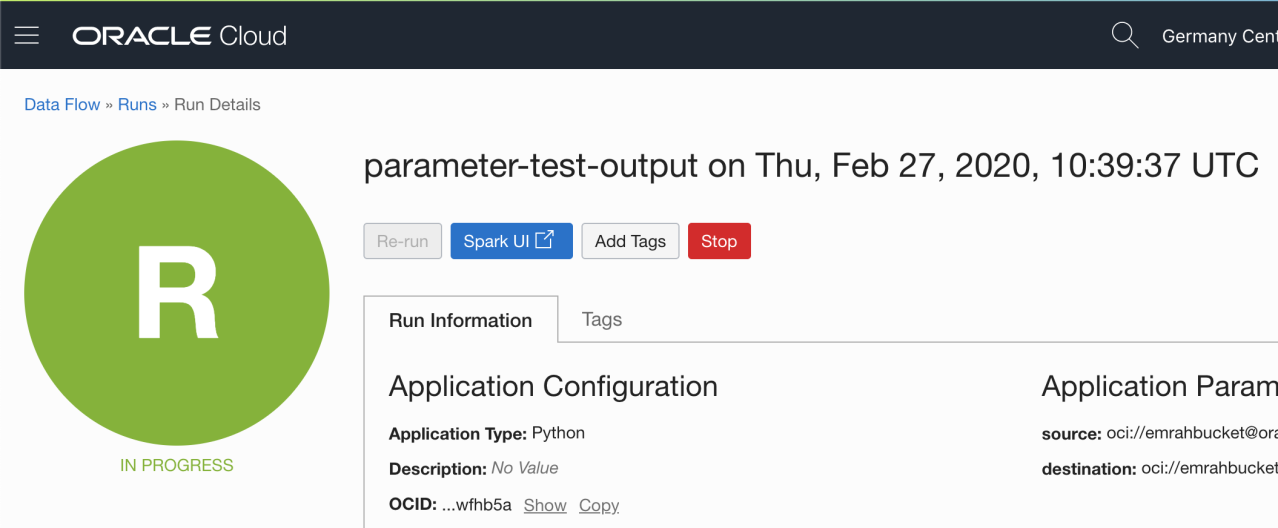
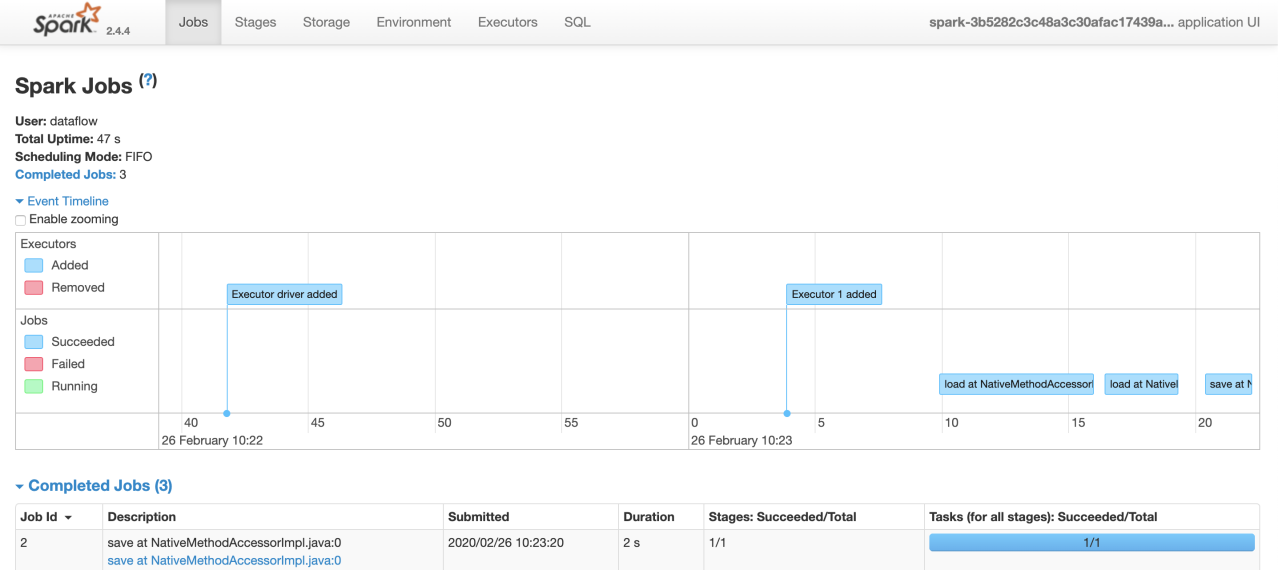
Data Flow Cloud Service in a nutshell:
- Supports many data source systems.
- Very simple troubleshooting.
- Providing a safe application execution environment with cloud-native security infrastructure.
- Almost no need for infrastructural management (managed service).
- Launched with flexible hardware specifications.
It is a flexible, high performance and easy-to-use platform where we can operate our Spark workloads in the cloud environment.
Opinions expressed by DZone contributors are their own.
Comments