Serverless Kubernetes, Managed Nodes on AWS EKS, and More
Look some new features released on the latest AWS Reinvent that will change the way we deploy and manage workloads on EKS.
Join the DZone community and get the full member experience.
Join For FreeToday, we are going to talk about some new features released on the latest AWS Reinvent that will change the way we deploy and manage workloads on EKS.
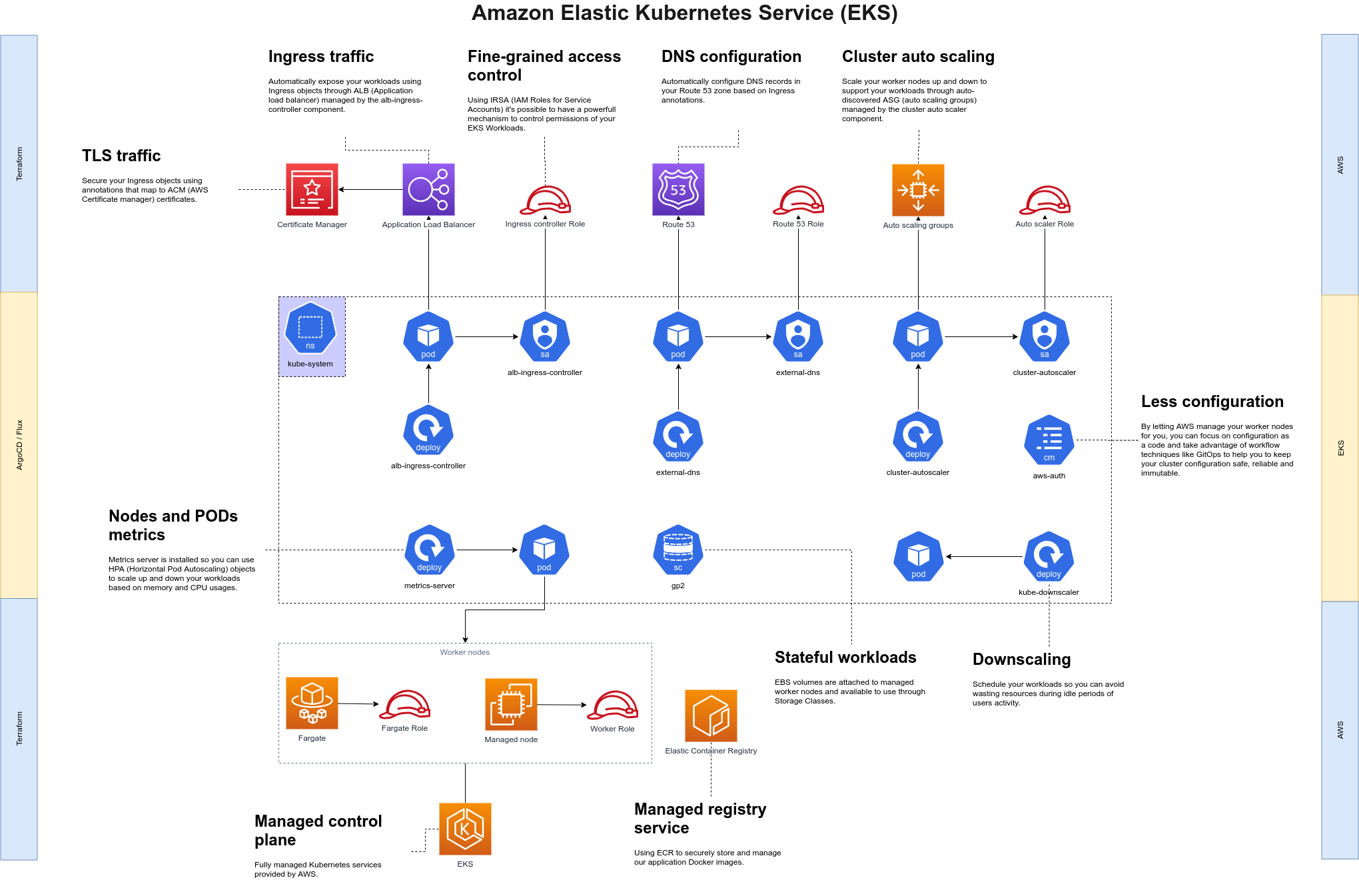
AWS Fargate + EKS = Serverless Worker Nodes
First, we would like to talk a little bit about why and how we manage to achieve serverless worker nodes on EKS.
Many of you probably heard about AWS Fargate, the new Serverless infrastructure for ECS and EKS, focused on running containers instead of pure EC2 instances and designed to save you from having to deal with infrastructure management, node security, upgrades, lifecycle, auto-scaling, and cost optimization. This last one is a tricky statement, I know, but let me explain why, with Fargate, you pay just for the processing time and memory you consumed. Of course, you will have to pay for the networking and other AWS resources as usual.
Getting Started With Fargate on EKS
How do you use EKS with Fargate? It’s pretty well-explained on AWS official documentation, but in short you:
- Create a Fargate Profile in your cluster choosing the private subnets you want (from your cluster VPC)
- Specify any number of namespaces you want to run on Fargate
- Additionally, specify node labels so you can have pods running from the same namespace on different Fargate profiles (in different AZs for example) and/or in managed nodes (more about this later).
Just to make this last point more clear, namespaces and labels are inclusive. So, for example, if you specify the namespace team-a and the label lifecycle=fargate, pods running in the namespace team-a AND with the label lifecycle=fargate will be scheduled on Fargate.
Best Practices
It’s also not a good ideia for you to run away from the best practices just yet, specially when talking about money. So you may follow any of these simple but useful rules:
- Properly plan the size of your pods with kube-resource-report
- Schedule the working hours so you can avoid unnecessary ‘idle’ costs with kube-downscaler
- Use HPA to control the number of running replicas (and consequently worker nodes)
- Use VPA to set the right size for your pod’s resource limits (just two quick tips here, first you need to choose between VPA and HPA for your deployment as they are mutually exclusive for CPU and memory metrics, second for VPA the scheduler will evict your pods if you tell it to automatically adjust the limits for you, this can cause an undesired behaviour if you don’t plan for this beforehand — https://github.com/kubernetes/autoscaler/tree/master/vertical-pod-autoscaler#known-limitations)
The Good
For the ones that are used to deal with self-managed worker nodes (manually or through IaC), serverless worker nodes are a must. Of course, one of the main concerns of any software architect when thinking about the cloud is to be more flexible/agile, but most importantly, to save money (hold that thought, because we will talk more about it in a minute).
The Ugly
One important thing to consider before diving into Fargate as your ‘default’ way of running k8s workloads is that you must be aware of the current limitations. If you are planning to run stateful workloads (EBS or AFS), AWS itself doesn’t recommend this practice, so don’t.
Another limitation is about CPU and memory limits for your pods; you won’t be able to specify more than 4 CPU and 30 GB in a single pod. You probably won’t see this scenario too often, but be aware.
Fargate for EKS also requires private subnets and to get traffic into your pods y̶̶̶o̶̶̶u̶̶̶ ̶̶̶n̶̶̶e̶̶̶e̶̶̶d̶̶̶ ̶̶̶t̶̶̶o̶̶̶ ̶̶̶u̶̶̶s̶̶̶e̶̶̶ ̶̶̶a̶̶̶n̶̶̶ ̶̶̶A̶̶̶L̶̶̶B̶̶̶ (which in our opinion is the best way to expose services in EKS, through the ALB Ingress Controller which, beyond the ability to configure everything for you, it enables you to easily integrate with ACM, automatically create Route 53 records using the external-dns component, configure WAF to increase app security, and so on). There is also the fact that EKS + Fargate is available only in a few regions. For an up-to-date list of the current limitations, we recommend you to check the official documentation.
It’s also possible to get traffic into your Fargate pods by using the Nginx Ingress Controller. This may be useful for the ones that are not ready to pay for one ALB per Ingress (which can be very expensive in some scenarios).
The Bad
Another interesting fact is that we do have Spot instances for Fargate on ECS. This way, we can use spare capacity to run our fault-tolerant workloads paying much less (AWS mentions something around 70% of cost savings). Unfortunately, Fargate Spot instances aren’t currently supported on EKS but this is (obviously) on AWS containers roadmap and we really believe that this feature will be soon generally available for AWS customers.
AWS Managed Node Groups
What if you still need to run stateful workloads on EKS (Prometheus monitoring stack for example)? Don’t worry, here it’s when Managed Node Groups comes to the rescue. This is another almost new feature from AWS designed to make node management easier for the ones that need to run stateful workloads or for some other reasons are not intending to go to Fargate just now.
Getting Started With Managed Node Groups
Managed nodes work just as expected; you create any number of groups with different instance types, volume sizes, AZ, number of instances (min, max and desired), and AWS will handle the creation of ASG, launch configurations, gracefully handle node lifecycle, choose the right/latest AMI, and you are ready to run workloads on it (even if you want to run Windows-based worker nodes — I know, it’s there so I needed to mention it, don’t blame me).
Best Practices
There’re other common configurations to consider that count for any kind of worker nodes like for example, node labeling (useful for a vast number of reasons, especially for high availability and workload isolation), node IAM roles and resource tagging (for better cost management and governance). With managed nodes you still can use the amazing cluster autoscaler in conjunction with HPA to optimize your costs. The other best practices to save costs with Fargate on EKS we mentioned in this article also count.
The Bad
Maybe you are wondering, "What about my EC2 Spot instances? Do I have similar available options?" Unfortunately, the answer is no. But honestly, I wouldn’t be writing this article if I wasn’t expecting AWS to release this feature very soon. Just like Spot instances on Fargate/EKS, we do believe we will have this in the near future. For most of you, this will be a no-go. It’s ok, we all understand that. Just keep in mind that managed nodes came to make our lives better, with much fewer minutes of ‘Support Ops’ and more of those precious ‘Dev Ops’ minutes. Also, think about manually cluster upgrades and all that common stuff we will be able to avoid very soon.
The Good
If you think about having your cluster infrastructure as a code (using Terraform for example), these two features will make things easier for you since you don’t have to bother with boiporlate infrastructure and also with the ‘not cool’ aws-auth config map.
The Ugly
Note that you still need to map your IAM users on it so you can use EKS RBAC to deal with authorization, but in this scenario, it’s easier for you to keep this configmap under source control and enable a GitOps workflow to control changes in your cluster configuration (keeping cluster infrastructure code and configuration code separated).
IAM Roles for Service Account
There’s one last cool thing I would like to mention here is that recently, AWS released what they call IRSA or IAM Roles for Service Accounts.
With this feature, it’s possible to turn your EKS Cluster into an OIDC provider and attach IAM Roles to your pod’s Service Accounts. The advantages are fine-grained access control of your workloads running on EKS and a more powerful integration between EKS and AWS’s many available services. It’s also very easy to propagate the identity to your containers, so I recommend you to check this out before trying to deal with authentication/authorization of EKS workloads within AWS Services.
Below it’s an example of how to create an OIDC provider for your EKS cluster and create an IAM Role for ALB Ingress Controller with Terraform.
# Cluster IRSA
data "external" "thumbprint" {
program = ["./thumbprint.sh", var.aws_region]
}
resource "aws_iam_openid_connect_provider" "cluster-oidc-provider" {
client_id_list = ["sts.amazonaws.com"]
thumbprint_list = [data.external.thumbprint.result.thumbprint]
url = aws_eks_cluster.eks-cluster.identity.0.oidc.0.issuer
}
data "template_file" "assume_role_policy" {
template = file("eks-oidc-assume-role.json.tpl")
vars = {
oidc_provider_arn = aws_iam_openid_connect_provider.cluster-oidc-provider.arn
cluster_oidc_issuer_url = replace(aws_iam_openid_connect_provider.cluster-oidc-provider.url, "https://", "")
}
}
# ALB Ingress Controller IAM
resource "aws_iam_role" "alb-ingress-role" {
name = "${var.cluster_name}-irsa"
assume_role_policy = data.template_file.assume_role_policy.rendered
}
resource "aws_iam_role_policy_attachment" "alb-ingress-ALBIngressControllerIAMPolicy" {
policy_arn = aws_iam_policy.alb-ingress-policy.arn
role = aws_iam_role.alb-ingress-role.name
}
resource "aws_iam_policy" "alb-ingress-policy" {
name = "ALBIngressControllerIAMPolicy"
path = "/"
policy = file("alg-ingress-controller-policy.json")
}
Thanks for reading.
Published at DZone with permission of Eduardo Goncalves. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments