Smart Batching
By
 ·
·
Interview
·
·
Interview
Likes
(1)
Likes
There are no likes...yet! 👀
Be the first to like this post!
It looks like you're not logged in.
Sign in to see who liked this post!
Comment
Save
11.6K Views
Join the DZone community and get the full member experience.
Join For Free
How often have we all heard that “batching” will increase latency? As
someone with a passion for low-latency systems this surprises me. In my
experience when batching is done correctly, not only does it increase
throughput, it can also reduce average latency and keep it consistent.
Well then, how can batching magically reduce latency? It comes down to what algorithm and data structures are employed. In a distributed environment we are often having to batch up messages/events into network packets to achieve greater throughput. We also employ similar techniques in buffering writes to storage to reduce the number of IOPS. That storage could be a block device backed file-system or a relational database. Most IO devices can only handle a modest number of IO operations per second, so it is best to fill those operations efficiently. Many approaches to batching involve waiting for a timeout to occur and this will by its very nature increase latency. The batch can also get filled before the timeout occurs making the latency even more unpredictable.
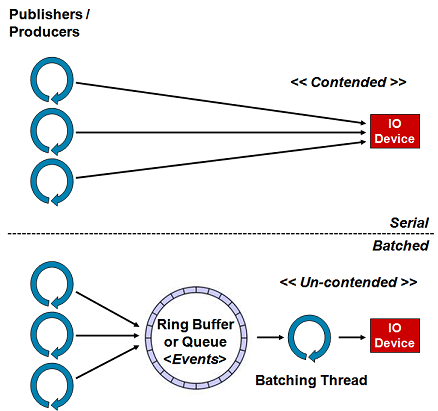
Figure 1. above depicts decoupling the access to an IO device, and therefore the contention for access to it, by introducing a queue like structure to stage the messages/events to be sent and a thread doing the batching for writing to the device.
The Algorithm
An approach to batching uses the following algorithm in Java pseudo code:
Basically, wait for data to become available and as soon as it is, send it right away. While sending a previous message or waiting on new messages, a burst of traffic may arrive which can all be sent in a batch, up to the size of the buffer, to the underlying resource. This approach can use ConcurrentLinkedQueue which provides low-latency and avoid locks. However it has an issue in not creating back pressure to stall producing/publishing threads if they are outpacing the batcher whereby the queue could grow out of control because it is unbounded. I’ve often had to wrap ConcurrentLinkedQueue to track its size and thus create back pressure. This size tracking can add 50% to the processing cost of using this queue in my experience.
This algorithm respects the single writer principle and can often be employed when writing to a network or storage device, and thus avoid lock contention in third party API libraries. By avoiding the contention we avoid the J-Curve latency profile normally associated with contention on resources, due to the queuing effect on locks. With this algorithm, as load increases, latency stays constant until the underlying device is saturated with traffic resulting in a more "bathtub" profile than the J-Curve.
Let’s take a worked example of handling 10 messages that arrive as a burst of traffic. In most systems traffic comes in bursts and is seldom uniformly spaced out in time. One approach will assume no batching and the threads write to device API directly as in Figure 1. above. The other will use a lock free data structure to collect the messages plus a single thread consuming messages in a loop as per the algorithm above. For the example let’s assume it takes 100µs to write a single buffer to the network device as a synchronous operation and have it acknowledged. The buffer will ideally be less than the MTU of the network in size when latency is critical. Many network sub-systems are asynchronous and support pipelining but we will make the above assumption to clarify the example. If the network operation is using a protocol like HTTP under REST or Web Services then this assumption matches the underlying implementation.
The absolute lowest latency will be achieved if a message is sent from the thread originating the data directly to the resource, if the resource is un-contended. The table above shows what happens when contention occurs and a queuing effect kicks in. With the serial approach 10 individual packets will have to be sent and these typically need to queue on a lock managing access to the resource, therefore they get processed sequentially. The above figures assume the locking strategy works perfectly with no perceivable overhead which is unlikely in a real application.
For the batching solution it is likely all 10 packets will be picked up in first batch if the concurrent queue is efficient, thus giving the best case latency scenario. In the worst case only one message is sent in the first batch with the other nine following in the next. Therefore in the worst case scenario one message has a latency of 100µs and the following 9 have a latency of 200µs thus giving a worst case average of 190µs which is significantly better than the serial approach.
This is one good example when the simplest solution is just a bit too simple because of the contention. The batching solution helps achieve consistent low-latency under burst conditions and is best for throughput. It also has a nice effect across the network on the receiving end in that the receiver has to process fewer packets and therefore makes the communication more efficient both ends.
Most hardware handles data in buffers up to a fixed size for efficiency. For a storage device this will typically be a 4KB block. For networks this will be the MTU and is typically 1500 bytes for Ethernet. When batching, it is best to understand the underlying hardware and write batches down in ideal buffer size to be optimally efficient. However keep in mind that some devices need to envelope the data, e.g. the Ethernet and IP headers for network packets so the buffer needs to allow for this.
There will always be an increased latency from a thread switch and the cost of exchange via the data structure. However there are a number of very good non-blocking structures available using lock-free techniques. For the Disruptor this type of exchange can be achieved in as little as 50-100ns thus making the choice of taking the smart batching approach a no brainer for low-latency or high-throughput distributed systems.
This technique can be employed for many problems and not just IO. The core of the Disruptor uses this technique to help rebalance the system when the publishers burst and outpace the EventProcessors. The algorithm can be seen inside the BatchEventProcessor.
Note: For this algorithm to work the queueing structure must handle the contention better than the underlying resource. Many queue implementations are extremely poor at managing contention. Use science and measure before coming to a conclusion.
Batching with the Disruptor
The code below shows the same algorithm in action using the Disruptor's EventHandler mechanism. In my experience, this is a very effective technique for handling any IO device efficiently and keeping latency low when dealing with load or burst traffic.
The endOfBatch parameter greatly simplifies the handling of the batch compared to the double loop in the algorithm above.
I have simplified the examples to illustrate the algorithm. Clearly error handling and other edge conditions need to be considered.
Separation of IO from Work Processing
There is another very good reason to separate the IO from the threads doing the work processing. Handing off the IO to another thread means the worker thread, or threads, can continue processing without blocking in a nice cache friendly manner. I've found this to be critical in achieving high-performance throughput.
If the underlying IO device or resource becomes briefly saturated then the messages can be queued for the batcher thread allowing the work processing threads to continue. The batching thread then feeds the messages to the IO device in the most efficient way possible allowing the data structure to handle the burst and if full apply the necessary back pressure, thus providing a good separation of concerns in the workflow.
Conclusion
So there you have it. Smart Batching can be employed in concert with the appropriate data structures to achieve consistent low-latency and maximum throughput.
Well then, how can batching magically reduce latency? It comes down to what algorithm and data structures are employed. In a distributed environment we are often having to batch up messages/events into network packets to achieve greater throughput. We also employ similar techniques in buffering writes to storage to reduce the number of IOPS. That storage could be a block device backed file-system or a relational database. Most IO devices can only handle a modest number of IO operations per second, so it is best to fill those operations efficiently. Many approaches to batching involve waiting for a timeout to occur and this will by its very nature increase latency. The batch can also get filled before the timeout occurs making the latency even more unpredictable.
 |
| Figure 1. |
Figure 1. above depicts decoupling the access to an IO device, and therefore the contention for access to it, by introducing a queue like structure to stage the messages/events to be sent and a thread doing the batching for writing to the device.
The Algorithm
An approach to batching uses the following algorithm in Java pseudo code:
public final class NetworkBatcher
implements Runnable
{
private final NetworkFacade network;
private final Queue<Message> queue;
private final ByteBuffer buffer;
public NetworkBatcher(final NetworkFacade network,
final int maxPacketSize,
final Queue<Message> queue)
{
this.network = network;
buffer = ByteBuffer.allocate(maxPacketSize);
this.queue = queue;
}
@Override
public void run()
{
while (!Thread.currentThread().isInterrupted())
{
while (null == queue.peek())
{
employWaitStrategy(); // block, spin, yield, etc.
}
Message msg;
while (null != (msg = queue.poll()))
{
if (msg.size() > buffer.remaining())
{
sendBuffer();
}
buffer.put(msg.getBytes());
}
sendBuffer();
}
}
private void sendBuffer()
{
buffer.flip();
network.send(buffer);
buffer.clear();
}
}Basically, wait for data to become available and as soon as it is, send it right away. While sending a previous message or waiting on new messages, a burst of traffic may arrive which can all be sent in a batch, up to the size of the buffer, to the underlying resource. This approach can use ConcurrentLinkedQueue which provides low-latency and avoid locks. However it has an issue in not creating back pressure to stall producing/publishing threads if they are outpacing the batcher whereby the queue could grow out of control because it is unbounded. I’ve often had to wrap ConcurrentLinkedQueue to track its size and thus create back pressure. This size tracking can add 50% to the processing cost of using this queue in my experience.
This algorithm respects the single writer principle and can often be employed when writing to a network or storage device, and thus avoid lock contention in third party API libraries. By avoiding the contention we avoid the J-Curve latency profile normally associated with contention on resources, due to the queuing effect on locks. With this algorithm, as load increases, latency stays constant until the underlying device is saturated with traffic resulting in a more "bathtub" profile than the J-Curve.
Let’s take a worked example of handling 10 messages that arrive as a burst of traffic. In most systems traffic comes in bursts and is seldom uniformly spaced out in time. One approach will assume no batching and the threads write to device API directly as in Figure 1. above. The other will use a lock free data structure to collect the messages plus a single thread consuming messages in a loop as per the algorithm above. For the example let’s assume it takes 100µs to write a single buffer to the network device as a synchronous operation and have it acknowledged. The buffer will ideally be less than the MTU of the network in size when latency is critical. Many network sub-systems are asynchronous and support pipelining but we will make the above assumption to clarify the example. If the network operation is using a protocol like HTTP under REST or Web Services then this assumption matches the underlying implementation.
| Best (µs) | Average (µs) | Worst (µs) | Packets Sent | |
|---|---|---|---|---|
| Serial | 100 | 500 | 1,000 | 10 |
| Smart Batching | 100 | 150 | 200 | 1-2 |
The absolute lowest latency will be achieved if a message is sent from the thread originating the data directly to the resource, if the resource is un-contended. The table above shows what happens when contention occurs and a queuing effect kicks in. With the serial approach 10 individual packets will have to be sent and these typically need to queue on a lock managing access to the resource, therefore they get processed sequentially. The above figures assume the locking strategy works perfectly with no perceivable overhead which is unlikely in a real application.
For the batching solution it is likely all 10 packets will be picked up in first batch if the concurrent queue is efficient, thus giving the best case latency scenario. In the worst case only one message is sent in the first batch with the other nine following in the next. Therefore in the worst case scenario one message has a latency of 100µs and the following 9 have a latency of 200µs thus giving a worst case average of 190µs which is significantly better than the serial approach.
This is one good example when the simplest solution is just a bit too simple because of the contention. The batching solution helps achieve consistent low-latency under burst conditions and is best for throughput. It also has a nice effect across the network on the receiving end in that the receiver has to process fewer packets and therefore makes the communication more efficient both ends.
Most hardware handles data in buffers up to a fixed size for efficiency. For a storage device this will typically be a 4KB block. For networks this will be the MTU and is typically 1500 bytes for Ethernet. When batching, it is best to understand the underlying hardware and write batches down in ideal buffer size to be optimally efficient. However keep in mind that some devices need to envelope the data, e.g. the Ethernet and IP headers for network packets so the buffer needs to allow for this.
There will always be an increased latency from a thread switch and the cost of exchange via the data structure. However there are a number of very good non-blocking structures available using lock-free techniques. For the Disruptor this type of exchange can be achieved in as little as 50-100ns thus making the choice of taking the smart batching approach a no brainer for low-latency or high-throughput distributed systems.
This technique can be employed for many problems and not just IO. The core of the Disruptor uses this technique to help rebalance the system when the publishers burst and outpace the EventProcessors. The algorithm can be seen inside the BatchEventProcessor.
Note: For this algorithm to work the queueing structure must handle the contention better than the underlying resource. Many queue implementations are extremely poor at managing contention. Use science and measure before coming to a conclusion.
Batching with the Disruptor
The code below shows the same algorithm in action using the Disruptor's EventHandler mechanism. In my experience, this is a very effective technique for handling any IO device efficiently and keeping latency low when dealing with load or burst traffic.
public final class NetworkBatchHandler
implements EventHander<Message>
{
private final NetworkFacade network;
private final ByteBuffer buffer;
public NetworkBatchHandler(final NetworkFacade network,
final int maxPacketSize)
{
this.network = network;
buffer = ByteBuffer.allocate(maxPacketSize);
}
public void onEvent(Message msg, long sequence, boolean endOfBatch)
throws Exception
{
if (msg.size() > buffer.remaining())
{
sendBuffer();
}
buffer.put(msg.getBytes());
if (endOfBatch)
{
sendBuffer();
}
}
private void sendBuffer()
{
buffer.flip();
network.send(buffer);
buffer.clear();
}
}The endOfBatch parameter greatly simplifies the handling of the batch compared to the double loop in the algorithm above.
I have simplified the examples to illustrate the algorithm. Clearly error handling and other edge conditions need to be considered.
Separation of IO from Work Processing
There is another very good reason to separate the IO from the threads doing the work processing. Handing off the IO to another thread means the worker thread, or threads, can continue processing without blocking in a nice cache friendly manner. I've found this to be critical in achieving high-performance throughput.
If the underlying IO device or resource becomes briefly saturated then the messages can be queued for the batcher thread allowing the work processing threads to continue. The batching thread then feeds the messages to the IO device in the most efficient way possible allowing the data structure to handle the burst and if full apply the necessary back pressure, thus providing a good separation of concerns in the workflow.
Conclusion
So there you have it. Smart Batching can be employed in concert with the appropriate data structures to achieve consistent low-latency and maximum throughput.
From http://mechanical-sympathy.blogspot.com/2011/10/smart-batching.html
Algorithm
Data (computing)
Network
Contention (telecommunications)
Opinions expressed by DZone contributors are their own.
Comments