Snowflake Data Processing With Snowpark DataFrames
Snowpark is a new developer library in Snowflake that provides an API to process data using programming languages like Scala (and later on Java or Python), instead of SQL.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
Snowpark is a new developer library in Snowflake that provides an API to process data using programming languages like Scala (and later on Java or Python), instead of SQL. The core concept in Snowpark is DataFrame that represents a set of data, e.g. a number of rows from a database table that can be processed using object oriented or functional programming techniques with our favorite tools. The notion of Snowpark DataFrames is similar to Apache Spark or Python Panda DataFrames.
Developers can also create user-defined functions (UDFs) that are pushed down to the Snowflake server where they can operate on the data. The code execution is using lazy evaluation; this will reduce the amount of data to be exchanged between Snowflake warehouse and the client.
The current version of Snowpark runs on Scala 2.12 and JDK 8, 9, 10 or 11. It is in public preview now, available for all accounts.
Architecture
From architecture perspective a Snowflake client is similar to Apache Spark Driver program. It executes the client code then pushes the generated SQL query to Snowflake warehouse and once the Snowflake compute server processed the data, it receives the result back in a DataFrame format.
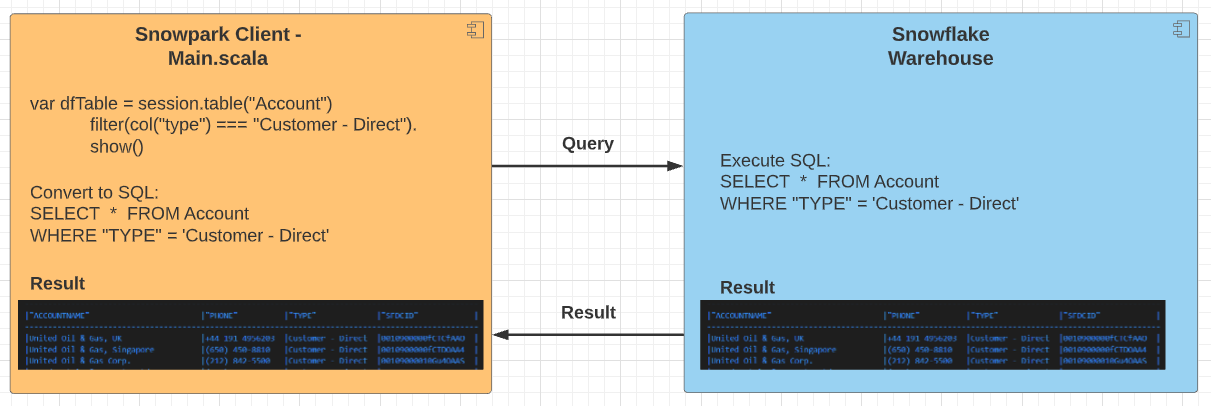
Broadly speaking, Snowflake operations can be put into two categories: transformations and actions. Transformations are lazily executed so they do not cause the DataFrames to be evaluated. Examples for transactions are select, filter, sort, groupBy, etc. Actions are the opposite; they will trigger the evaluation of the DataFrame so Snowpark sends the SQL query for the DataFrame to the server for evaluation and the result will be downloaded to the client's memory. Example for actions include show, collect, take, etc.
Snowpark in Action
Before we can execute any Snowpark transformations and actions, we need to connect to the Snowflake warehouse and establish a session.
object Main {
def main(args: Array[String]): Unit = {
// Replace the <placeholders> below.
val configs = Map (
"URL" -> "https://<SNOWFLAKE-INSTANCE>.snowflakecomputing.com:443",
"USER" -> "<USERNAME>",
"PASSWORD" -> "<PASSWORD>",
"ROLE" -> "SYSADMIN",
"WAREHOUSE" -> "SALESFORCE_ACCOUNT",
"DB" -> "SALESFORCE_DB",
"SCHEMA" -> "SALESFORCE"
)
val session = Session.builder.configs(configs).create
session.sql("show tables").show()
}
}From Snowflake Admin UI perspective, we have a SALESFORCE_DB database with a schema SALESFORCE that ha3 tables: SALESFORCE_ACCOUNT table represents account from our Salesforce instance, SALESFORCE_ORDER table stores orders initiated by these accounts and SALESFORCE_ACCOUNT_ORDER is a joined table that will store the joined query result (we come back to this later on in this post):
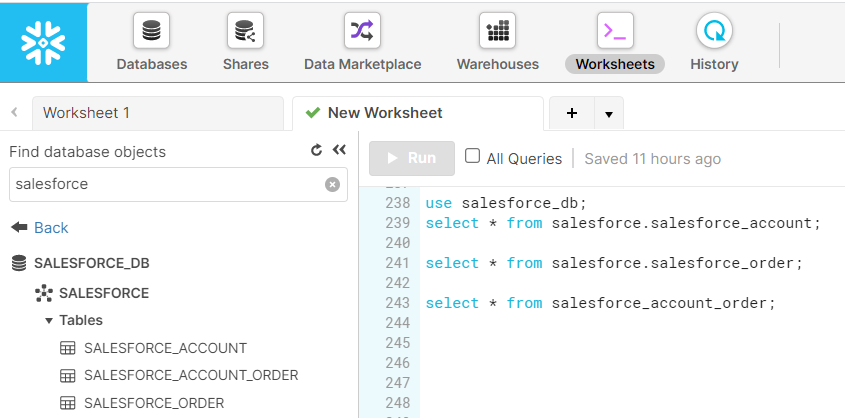
To retrieve the first 10 rows from the Salesforce_Account table we can just simply execute the following DataFrame methods:
// Create a DataFrame from the data in the "salesforce_account" table.
val dfAccount = session.table("salesforce_account")
// To print out the first 10 rows, call:
dfAccount.show()Snowpark will convert the code into SQL and push it to Snowflake warehouse for execution:
[main] INFO com.snowflake.snowpark.internal.ServerConnection - Execute query [queryID: XXXX] SELECT * FROM ( SELECT * FROM (salesforce_account)) LIMIT 10The output in our VSCode IDE looks like this:

We can also filter certain rows and execute transformation (e.g. select columns) of the DataFrame:
val dfFilter = session.table("salesforce_account").filter(col("type") === "Customer - Direct")
dfFilter.show()
val dfSelect = session.table("salesforce_account").select(col("accountname"), col("phone"))
dfSelect.show()Snowpark will generate the corresponding SQL queries and push them down to Snowflake compute server:
[main] INFO com.snowflake.snowpark.internal.ServerConnection - Execute query [queryID: XXXX] SELECT * FROM ( SELECT * FROM ( SELECT * FROM (salesforce_account)) WHERE ("TYPE" = 'Customer - Direct')) LIMIT 10
[main] INFO com.snowflake.snowpark.internal.ServerConnection - Execute query [queryID: XXXX] SELECT * FROM ( SELECT "ACCOUNTNAME", "PHONE" FROM ( SELECT * FROM (salesforce_account))) LIMIT 10And the VSCode output:

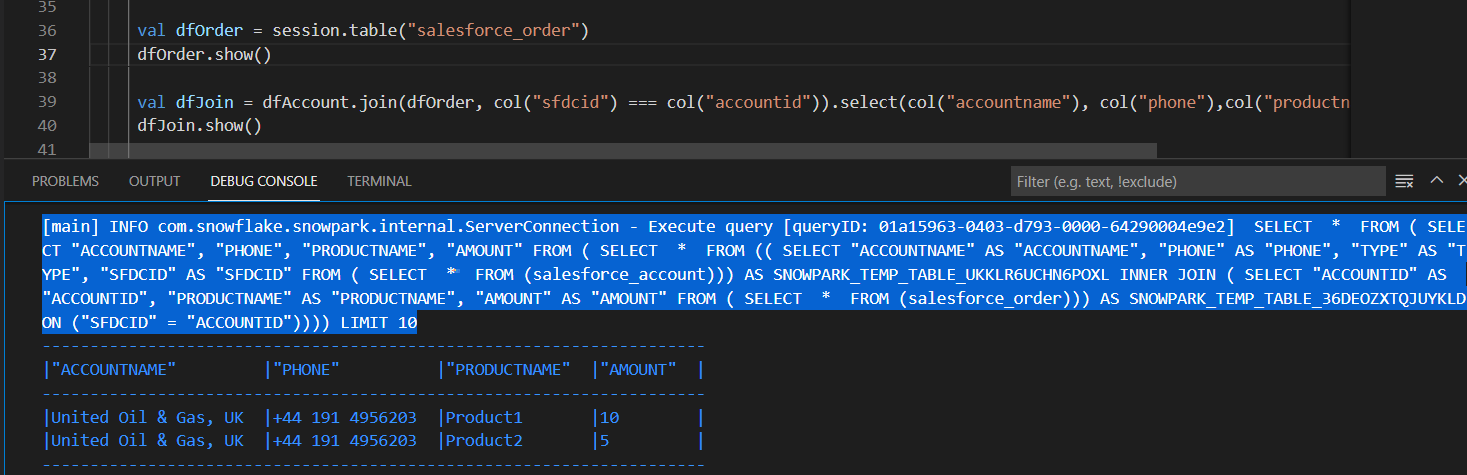
Snowflake DataFrame API also allows joining DataFrames. In our example, we have the Salesforce_Order table in Snowflake containing orders executed by these Salesforce accounts. We can pull that data into our DataFrame and join them with account records:
val dfOrder = session.table("salesforce_order")
dfOrder.show()
val dfJoin = dfAccount.join(dfOrder, col("sfdcid") === col("accountid")).select(col("accountname"), col("phone"),col("productname"), col("amount"))
dfJoin.show()Snowflake converts the DataFrame methods into SQL and pushes them to the Snowflake warehouse. The output will look like this in VSCode:
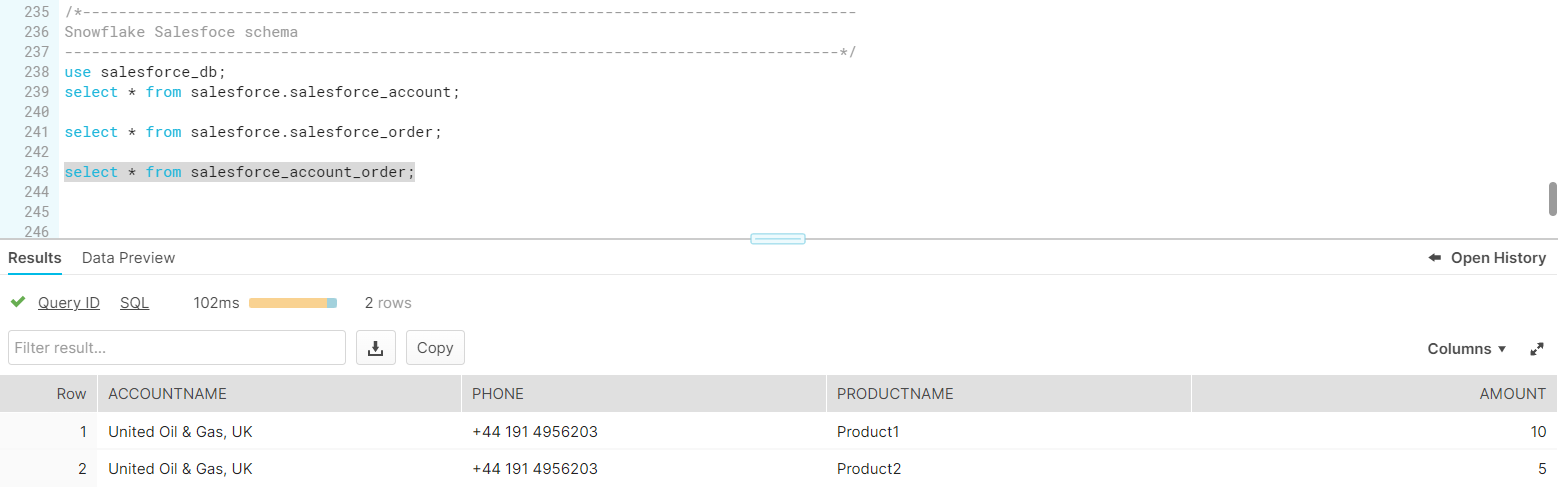
If we want to persist our calculated results, we can do it by using saveAsTable method:
dfJoin.write.mode(SaveMode.Overwrite).saveAsTable("salesforce_account_order")The generated SQL query looks like this:
[main] INFO com.snowflake.snowpark.internal.ServerConnection - Execute query [queryID: XXXX] CREATE OR REPLACE TABLE salesforce_account_order AS SELECT * FROM ( SELECT "ACCOUNTNAME", "PHONE", "PRODUCTNAME", "AMOUNT" FROM ( SELECT * FROM (( SELECT "ACCOUNTNAME" AS "ACCOUNTNAME", "PHONE" AS "PHONE", "TYPE" AS "TYPE", "SFDCID" AS "SFDCID" FROM ( SELECT * FROM (salesforce_account))) AS SNOWPARK_TEMP_TABLE_UKKLR6UCHN6POXL INNER JOIN ( SELECT "ACCOUNTID" AS "ACCOUNTID", "PRODUCTNAME" AS "PRODUCTNAME", "AMOUNT" AS "AMOUNT" FROM ( SELECT * FROM (salesforce_order))) AS SNOWPARK_TEMP_TABLE_36DEOZXTQJUYKLD ON ("SFDCID" = "ACCOUNTID"))))And as a result, Snowpark will create a new table or replace the existing one and store the generated data:
Conclusion
Snowpark opens up a wide variety of operations and tools to be used in the data processing. It allows creating very complex and advanced data pipeline. It is a powerful feature that can push the custom code down to the Snowflake warehouse and execute it close to the data by reducing the need for unnecessary data transfer.
Opinions expressed by DZone contributors are their own.
Comments