Software Testing – Is It Time to Fire Your QA Team?
There can be better ways to approach the deployment of code and issue management rather than big bang release cycles.
Join the DZone community and get the full member experience.
Join For FreeTraditionally, for software development and software testing teams that are part of larger organizations, they go through a more rigid process when developing and ultimately deploying their code into production, versus ones that follow a more Agile approach. As organizations become larger, software applications also grow in size too, and stricter and stricter processes need to be in place to stop outages, bugs, errors, crashes, and bad deployments affecting end users negatively. There can, however, be better ways to approach the deployment of code and issue management rather than big bang release cycles. Developers may also be able to have better visibility on how they are contributing to services and products with the code they write every day.

Throwing Code Over the Wall
Some developers can spend months, or even years working on specific features or products and never see them ship. Or if they do ship, have no insights into how their work was received by customers.
Due to externalities. developers in large organizations can be asked to throw their hard work over the wall so to speak to the Quality Assurance (QA) department and software testing teams. Robust software testing finds issues that could have affected customers should the code be placed into the hands of end users, never to be seen again unless it needs further tweaking.
QAs and testers act as the final guard between stakeholders and customers, and they can be petrified that users could be exposed to major bugs or outages should bad code be released into the wild, especially for mission critical software. However once released, visibility to production issues rely on customers to report the issues they experience and for front-line support staff to be the go-between of customer and developer.

The purpose of having a QA team with complex processes is to do as much as possible to prevent large bugs from hitting the user. Organizations are deathly afraid of those large, show stopping exceptions being present for users, and so they should be. QA teams should not go away entirely for enterprise level companies and the QA process is also essential at the startup level to ensure that you don’t lose traction due to a bug that was discovered too late in production.
A bug identified and fixed in the conception or early design stages costs next to nothing, but bugs needing attention in production can cost considerably more.
The challenge is to give the developer a view of errors and crashes caused by in their own code. Though QA teams are effective, they’re often not best placed to find hidden issues. Often the people who built it are the most qualified to debug it.
Giving Developer Teams Better Visibility of Their Code
Here’s how things might work in traditional software development teams. This tends to be prevalent in larger organizations and though inefficient, works for a lot of companies where costs can be consumed and overall shipping of features can be done in regimented cycles. It does, however, limit the front line developer’s ability to see how their code is being used by end users, and if things are getting better or worse for customers.
Developers can create beautifully coded and complex features for users, but only ever get to see the results of their own colleagues internally, using what they built. There is a wall between them and the end user. This is how the process might look, with the Analysis, Design and Implementation phases of the Software Development Lifecycle compressed into ‘Developers’ below:
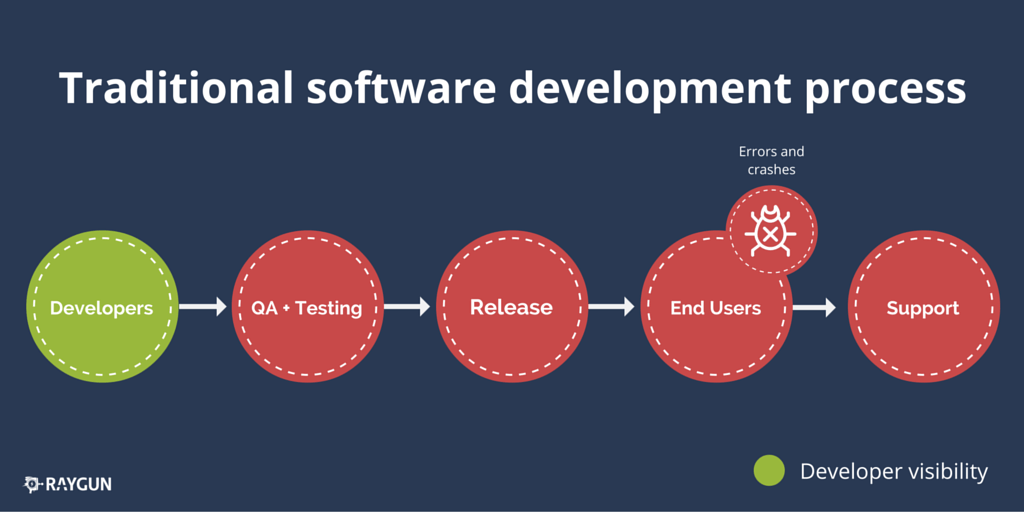
The developers can instead have full visibility of their code whether it is in QA, software testing, production or end user’s hands. How? Well, automated error monitoring and end user performance monitoring keeps a watchful eye on their software and when issues are found the entire team can be alerted immediately.
Rather than a wall in front of them, developer teams now have a window into how users are interacting with their software and the features they build.
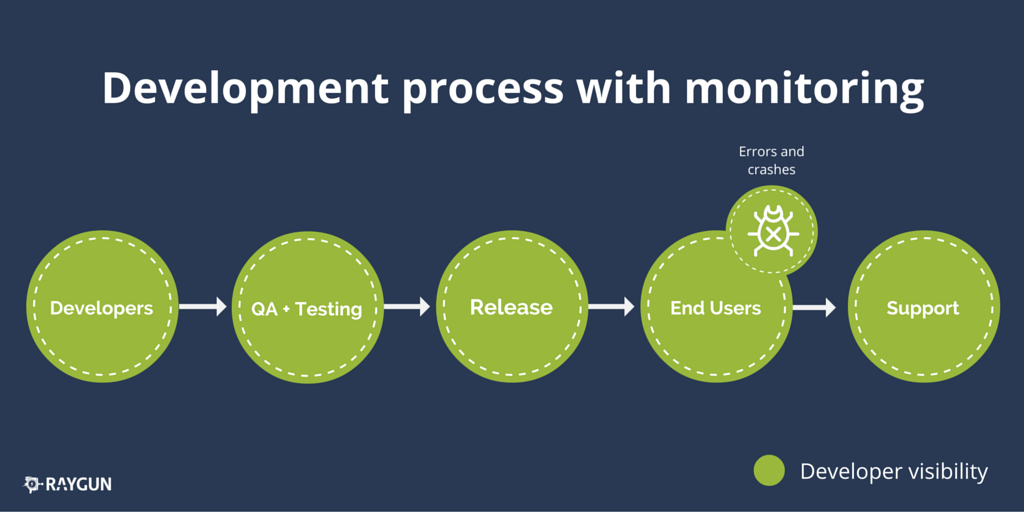
Deploying Code Safely Without Complex QA and Software Testing
For many teams that use automatic error monitoring tools, they’ve completely eliminated the need for thorough QA and software testing of the developer’s code before it goes into production. Now this doesn’t mean they do not continue to do thorough unit, integration and acceptance tests of their code at the development stage and have the wider developer team perform code and peer reviews, but they no longer need to have a strict, inflexible QA process in place, or if they do implement one, it is pushed back till the organization is much, much larger, and only for critical processes.
This is due to an automated error monitoring tool being the guardian from bad code causing issues for users, rather than relying on humans to run test after test to ensure code is safe to deploy and for customers to use.
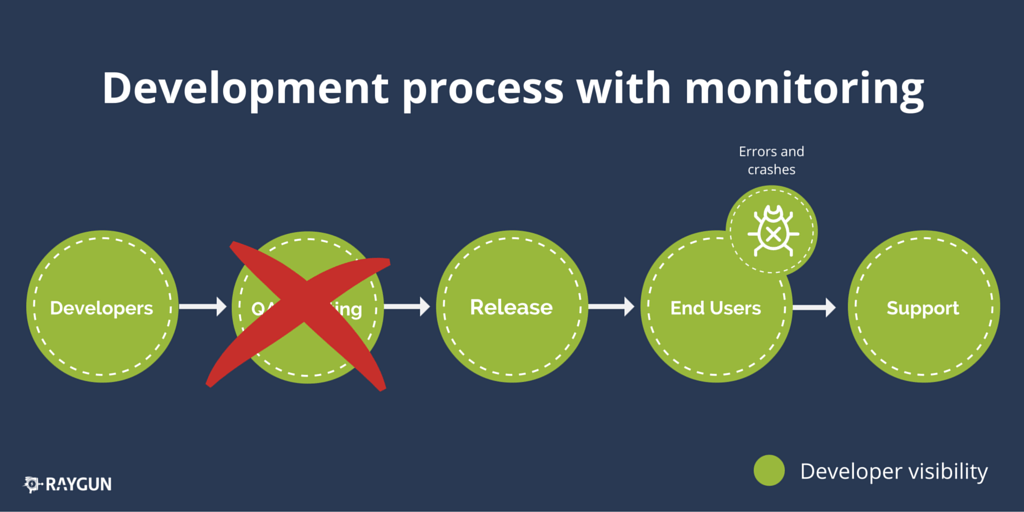
You’ll also see here that there is now a clear line of sight between developers and application errors and crashes. If we were to roll out a bug into production that caused an unhandled exception that affects and is seen by many users, the entire team can be notified of the issue within a few seconds, with diagnostic details providing enough information to fix it quickly.
Again, without the need for long release cycles, software testing and QA processes, code can be shipped on smaller timescales (hours or days) and the issue fixed before any other users encounter the same problem. There is a huge safety net in place should we push bad code into production.
Resolving Errors and Crashes for Users the Easy Way
Here’s how this also breaks down for support issues specifically. In the traditional model when a customer reports an issue the support team will have to take this largely non-technical information to a specific individual on the developer team who is assigned to fix the problem.
Back and forth information ensues, which is often unhelpful for the developer, as they want information such as the user’s browser, operating system, error messages seen, page it happened on, time of day etc so they can check the logs. Why are you putting the biggest effort upon your customers here? Taking time out of their day to explain problems you caused them?

How often has your support team struggled to replicate and/or fix a software issue that a user encountered, but spent hours trying to debug it, digging through log files and going on pasted screenshots in Word documents from a now disgruntled and angry user? Front line support staff are usually the ones dealing with the customer, and information is passed to the developer team inefficiently and often third hand, as the customer tries to explain which page, step or action they encountered the issue.
Our modern software development model with error monitoring solutions in production environments, have issues reported automatically, without the need for users to report them. The development team has full visibility on issues. Should support teams have a customer who has reported an issue, a simple search of their email address can bring up the diagnostic information about the exact error they encountered, including the stack trace and environment data that can be the key to a fast bug fix. It’s so, so easy.

Developers who implement automatic error monitoring with their applications are also empowered to care more about how their code affects end users, because they get the insight into the issues they are encountering.
How the Savings Can Add Up
You may not think that it is worth radically changing your organizational structure, but the status quo of traditional development teams can end up hitting companies hard in the pocket. Error monitoring tools like Raygun offer reasonable monthly plans that can be seen as a business cost, however, if you think about how much money an error monitoring tool can save you, the cost per year can be far outweighed by what you already pay in salaries.
Time is money and digging through log files isn’t a good way to spend it.
It takes time to overcome organizational inertia to implement Agile processes, and bring in a culture of frequent, small, safe and decoupled deployments using workflows and tooling such as Continuous Integration and container deployments, for example. Adding defect monitoring to deployables in production is a low-impact way to greatly reduce the cost and risks of bugs in live systems, without the need to get many stakeholders on board with a re-org.
QA teams are still an important part of enterprise IT teams. Rather than be replaced by error monitoring tools that can detect issues automatically, QA teams should embrace this technology shift to make their jobs easier. If an organization can save themselves from an extra hire or two in the software testing department, customer support department and software development department because their whole team is more streamlined and productive, the cost savings are substantial for any company that ships software.
Published at DZone with permission of . See the original article here.
Opinions expressed by DZone contributors are their own.
Comments