SOLID, GRASP, and Other Basic Principles of Object-Oriented Design
Learn principles of Object Oriented Design, and get a firm hold on the ideas behind the SOLID and GRASP languages in this article.
Join the DZone community and get the full member experience.
Join For FreeI will start with a cliché. Code should depict the following qualities:
- Maintainability
- Extensibility
- Modularity
You may find yourself in a difficult situation when you ask a question about whether any particular code depicts the above average qualities or not.
A technique that helps is to look at the development timeline of any piece of software. If the code remains easy to maintain, extend, and modularize over its lifetime then it means that the code is above average in terms of the qualities listed above.
I have written difficult to read, hard to extend, and rotten code. I only knew after six months into the development when a change happened. Hence the development timeline is important in understanding quality factors.
Senior developers, who know about quality, don't have this problem. They feel proud when they see their code has the quality factors which junior developers only dream about. Hence senior developers and experts have distilled a set of principles down to junior developers which they can apply to write quality code and to show off in front of other developers.
In this post, I will cover SOLID principles. These principles are given by Uncle Bob (Robert C. Martin). I will also cover GRASP (General Responsibility Assignment Software Principles) published by Craig Larman and a few other basic object-oriented design principles. I have included examples from my personal experience, therefore you will not find any 'Animal' or 'Duck' examples.
The code examples shown are closer to Java and C#, but they are helpful to any developer who knows the basics of object-oriented programming.
Here is the complete list of principles covered in this post:
- Single Responsibility Principle (SOLID)
- High Cohesion (GRASP)
- Low Coupling (GRASP)
- Open Closed Principle (SOLID)
- Liskov Substitution principle (SOLID)
- Interface Segregation Principle (SOLID)
- Dependency Inversion Principle (SOLID)
- Program to an Interface, not to an Implementation
- Hollywood Principle
- Polymorphism (GRASP)
- Information Expert (GRASP)
- Creator (GRASP)
- Pure Fabrication (GRASP)
- Controller (GRASP)
- Favor composition over inheritance
- Indirection (GRASP)
One mistake that I made early in my career is that I tried to apply all the above principles at one time. That was a big mistake. I don’t want you to do that. I have designed a very simple process that allows you to apply basic design skills, and then build up from there. I compiled that process here.
Single Responsibility Principle
The Single Responsibility Principle (SRP) states:
A class should have only one responsibility.
A class fulfills its responsibilities using its functions or contracts (and data members help functions).
Take the following example class:
Class Simulation{
Public LoadSimulationFile()
Public Simulate()
Public ConvertParams()
}This class handles two responsibilities. First, this class is loading simulation data, and, second, it is performing the simulation algorithm (using the Simulate and ConvertParams functions).
A class fulfills a responsibility using one, or more than one, function. In the example above, loading the simulation data is one responsibility, and performing the simulation is another responsibility. One function is needed to load simulation data (i.e LoadSimulationFile). The remaining two functions are needed to perform the simulation.
How do I know how many responsibilities my class has? Consider the phrase "reason to change" as analogous to responsibility. Hence, look for all the reasons a class has to change. If there is more than one reason to change a class then it means this class does not follow the single responsibility principle.
In our example class above, this class should not contain the LoadSimulationFile function (or loading simulation data responsibility). If we create a separate class for loading simulation data then this class will not violate SRP.
A class can only have a single responsibility. How would you design software with such a hard rule?
Let’s consider another principle which is closely related to SRP: High Cohesion. High cohesion gives you a subjective scale and not an objective one as in the case of SRP. Very low cohesion means a class is fulfilling many responsibilities. For example, there are more than 10 responsibilities for which a class is responsible. Low cohesion means a class is fulfilling around 5 responsibilities and moderate cohesion means a class fulfilling 3 responsibilities. High cohesion means a class is fulfilling a single responsibility. Hence, the rule of thumb while designing is to strive for high cohesion.
Another principle which should be discussed here is Low Coupling. This principle states that one should assign a responsibility so that the dependency between the classes remains low. Again consider the above example class. After applying the SRP and the high cohesion principle, we have decided to make a separate class which will handle simulation files. In this way, we have created two classes which are dependent on each other.
It looks like as if applying high cohesion is causing us to violate the principle of low coupling. This level of coupling is allowed as the goal in order to minimize the coupling, but not to zero the coupling. Some degree of coupling is normal to create an object-oriented design in which tasks are completed by a collaboration of objects.
On the other hand, consider a GUI class which connects to a database, handles remote clients over HTTP and handles screen layout. This GUI class is dependent upon too many classes. This GUI class clearly violates the low-coupling principle. This class cannot be re-used without involving all the related classes. Any change to database component cause changes to GUI class.
Open-Closed Principle
The Open-Closed principles states:
A software module (it can be a class or method ) should be open for extension but closed for modification.
In other words, you cannot update the code that you have already written for a project, but you can add new code to the project.
There are two methods by which you can apply the open-closed principle. You can apply this principle either through inheritance or through composition.
Here is the example of applying the open-close principle using inheritance:
Class DataStream{
Public byte[] Read()
}
Class NetworkDataStream:DataStream{
Public byte[] Read(){
//Read from the network
}
}
Class Client {
Public void ReadData(DataStream ds){
ds.Read();
}
}In this example, the client read data (ds.Read()) comes from the network stream. If I want to extend the functionality of the client class to read data from another stream, e.g. PCI data stream, then I will add another subclass using the DataStream class, as shown in the listing below:
Class PCIDataStream:DataStream{
Publc byte[] Read(){
//Read data from PCI
}
}In this scenario, the client code will function without any error. The client class knows about the base class, and I can pass an object of any of the two subclasses of DataStream. In this way, the client can read data without knowing the underlying subclass. This is achieved without modifying any existing code.
We can apply this principle using composition, and there are other methods and design patterns to apply this principle. Some of these methods will be discussed in this post.
Do you have to apply this principle to every piece of code that you write? No. This is because most of that code will not change. You will only have to apply this principle strategically in those conditions where you suspect a piece of code will change in the future.
Liskov Substitution Principle
The Liskov Substitution Principle states:
Derived classes must be substitutable for their base classes.
Another way to look at this definition is that abstraction (interface or abstract class) should be enough for a client.
To elaborate, let’s consider an example, here is an interface whose listing is given below:
Public Interface IDevice{
Void Open();
Void Read();
Void Close();
}This code represents data acquisition device abstraction. Data acquisition devices differ based upon their interface types. A data acquisition device can use a USB interface, Network Interface (TCP or UDP), PCI express interface, or any other computer interface. Clients of iDevice, however, do not need to know what kind of device they are working with. This gives programmers an enormous amount of flexibility to adapt to new devices without changing the code which depends upon the iDevice interface.
Let’s go into a little history when there were only two concrete classes that implemented iDevice interface shown below:
public class PCIDevice:IDevice {
public void Open(){
// Device specific opening logic
}
public void Read(){
// Reading logic specific to this device
}
public void Close(){
// Device specific closing logic.
}
}
public class NetWorkDevice:IDevice{
public void Open(){
// Device specific opening logic
}
public void Read(){
// Reading logic specific to this device
}
public void Close(){
// Device specific closing logic.
}
}These three methods (open, read, and close) are sufficient to handle data from these devices. Later, there was a requirement to add another data acquisition device which was based upon USB Interface.
The problem with a USB device is that when you open the connection, data from the previous connection remains in the buffer. Therefore, upon the first read call to the USB device, data from the previous session is returned. That behavior corrupted data for that particular acquisition session.
Fortunately, a USB-based device driver provides a refresh function which clears the buffers in the USB-based acquisition device. How can I implement this feature into my code so that the code change remains minimal?
One simple, but unadvised, solution is to update the code by identifying if you are calling the USB object:
public class USBDevice:IDevice{
public void Open(){
// Device specific opening logic
}
public void Read(){
// Reading logic specific to this device<br>
}
public void Close(){
// Device specific closing logic.
}
public void Refresh(){
// specific only to USB interface Device
}
}
//Client code..
Public void Acquire(IDevice aDevice){
aDevice.Open();
// Identify if the object passed here is USBDevice class Object.
if(aDevice.GetType() == typeof(USBDevice)){
USBDevice aUsbDevice = (USBDevice) aDevice;
aUsbDevice.Refresh();
}
// remaining code….
}In this solution, client code is directly using the concrete class as well as the interface (or abstraction). It means abstraction is not enough for the client to fulfill its responsibilities.
Another way to state the same thing is to say that the base class cannot fulfill the required behavior (refresh behavior), but the derived class does, in fact, have this behavior. Hence, the derived class is not compatible with the base class and thus the derived class cannot be substituted. Therefore, this solution violates the Liskov Substitution Principle.
In the example above, the client is dependent upon more entities (iDevices and USB Devices) and any change in one entity will cause a change in other entities. Therefore, violation of the LSP causes dependency between the classes.
Below I give a solution to this problem that follows the LSP:
Public Interface IDevice{
Void Open();
Void Refresh();
Void Read();
Void Close();
}
Now the client of iDevice is:
Public void Acquire(IDevice aDevice)
{
aDevice.open();
aDevice.refresh();
aDevice.acquire()
//Remaining code..
}Now the client does not depend upon the concrete implementation of iDevice. Hence, in this solution, our interface (iDevice) is enough for the client.
There is another angle to look at the LSP principle within the context of object-oriented analysis. To get an introduction and a simple method to apply object-oriented analysis read this. In summary, during OOA, we think about the classes and their hierarchies that could be part of our software.
When we are thinking about the classes and hierarchies we can come up with classes which violate the LSP.
Let’s consider the classic example of the rectangle and the square. When looking from the outset it looks like that square is a specialized version of the rectangle and a happy designer would draw the following inheritance hierarchy:
Public class Rectangle{
Public void SetWidth(int width){}
Public void SetHeight(int height){}
}
Public Class Square:Rectangle{
//
}What happens next is you cannot substitute a square object in place of a rectangular object. Since the square inherits from the rectangle, therefore, it inherits its method setWidth() and setHeight(). A client of the square object can change its width and height to different dimensions. But width and height of a square are always identical, hence we get a failing of the normal behavior of the software.
This can only be avoided by looking at classes according to different usage scenarios and conditions. Therefore, when you are designing classes in isolation there is a probability that your assumptions may fail. As in the case of Square and Rectangle, a relationship looks good enough during initial analysis, but as we look at different conditions this relationship failed to work with the correct behavior of the software.
Interface Segregation Principle
The Interface Segregation Principle (ISP) states:
Clients should not be forced to depend upon the interfaces that they do not use.
Again consider the previous example:
Public Interface IDevice{
Void Open();
Void Read();
Void Close();
}There are three classes that implement this interface: USBDevice, NetworkDevice, and PCIDevice. This interface is good enough to work with the network and PCI devices. But the USB device needs another function (Refresh()) to work properly.
Similar to the USB device, there can be another device which may require a refresh function to work properly. Due to this, iDevice is updated as shown below:
Public Interface IDevice{
Void Open();
Void Refresh();
Void Read();
Void Close();
}The problem is now each class that implements iDevice has to provide the definition for the refresh function.
For example, I have to add the following lines of code to the NetworkDevice class and PCIDevice class to work with this design:
public void Refresh()
{
// Yes nothing here… just a useless blank function
}Hence, iDevice represents a fat interface (too many functions). This design violates the Interface Segregation Principle because the fat interface is causing unnecessary clients to depend upon it.
There are numerous ways to solve this problem, but I will tackle this problem while staying within our predefined range of object-oriented solutions.
I know that refresh is directly called after the open function. Hence, I moved the logic of refresh from the client of iDevice to the specific concrete class. In our case I moved the call to refresh logic to the USBDevice class as shown here:
Public Interface IDevice{
Void Open();
Void Read();
Void Close();
}
Public class USBDevice:IDevice{
Public void Open{
// open the device here…
// refresh the device
this.Refresh();
}
Private void Refresh(){
// make the USb Device Refresh
}
}In this way, I have reduced the number of functions in the iDevice class and made it less fat.
Dependency Inversion Principle (DIP)
This principle is a generalization of the other principles discussed above.
Before jumping to the textbook definition of DIP, let me introduce a closely related principle which will help understand DIP.
The principle is:
Program to an interface, not to an implementation.
This is a simple one. Consider the following example:
Class PCIDevice{
Void open(){}
Void close(){}
}
Static void Main(){
PCIDevice aDevice = new PCIDevice();
aDevice.open();
//do some work
aDevice.close();
}
The above example violates the “program to an interface" principle because we are working with the reference of the concrete class PCI Device. The below listing follows this principle:
Interface IDevice{
Void open();
Void close();
}
Class PCIDevice implements IDevice{
Void open(){ // PCI device opening code }
Void close(){ // PCI Device closing code }
}
Static void Main(){
IDevice aDevice = new PCIDevice();
aDevice.open();
//do some work
aDevice.close();
}Hence it’s very easy to follow this principle. The Dependency Inversion Principle is similar to this principle, but DIP asks us to do one more step.
DIP says:
High-level modules should not depend upon low-level modules. Both should depend upon abstractions.
You can easily understand the line “both should depend upon abstractions,” as it is saying each module should program to an interface. But what are high-level modules and low-level modules?
To understand the first part we have to learn what high-level modules and low-level modules actually are.
See the following code:
Class TransferManager{
public void TransferData(USBExternalDevice usbExternalDeviceObj,SSDDrive ssdDriveObj){
Byte[] dataBytes = usbExternalDeviceObj.readData();
// work on dataBytes e.g compress, encrypt etc..
ssdDriveObj.WrtieData(dataBytes);
}
}
Class USBExternalDevice{
Public byte[] readData(){
}
}
Class SSDDrive{
Public void WriteData(byte[] data){
}
}In this code, there are three classes. The TransferManager class represents a high-level module. This is because it is using two classes in its one function. Hence the other two classes are low-level modules.
The high-level module function (TransferData) defines logic based upon how data is transferred from one device to another device. Any module which is controlling the logic, and uses the low-level modules in doing so, is called the high-level module.
In the code above, the high-level module is directly (without any abstraction) using the lower-level modules, hence violating the dependency inversion principle.
Violation of this principle makes the software difficult to change. For example, if you want to add other external devices you will have to change the higher-level module. Hence your higher-level module will be dependent upon the lower-level module, and that dependency will make the code difficult to change.
The solution is easy if you understand the principle above: "program to an interface." Here is the listing:
Class USBExternalDevice implements IExternalDevice{
Public byte[] readData(){
}
}
Class SSDDrive implements IInternalDevice{
Public void WriteData(byte[] data){
}
}
Class TransferManager implements ITransferManager{
public void Transfer(IExternalDevice externalDeviceObj, IInternalDevice internalDeviceObj){
Byte[] dataBytes = externalDeviceObj.readData();
// work on dataBytes e.g compress, encrypt etc..
internalDeviceObj.WrtieData(dataBytes);
}
}
Interface IExternalDevice{
Public byte[] readData();
}
Interfce IInternalDevice{
Public void WriteData(byte[] data);
}
Interface ITransferManager {
public void Transfer(IExternalDevice usbExternalDeviceObj,SSDDrive IInternalDevice);
}In the code above both high-level module and low-level modules depend upon abstractions. This code follows the Dependency Inversion Principle.
Hollywood Principle
This principle is similar to the Dependency Inversion Principle. This principle states:
Don’t call us, we will call you.
This means a high-level component can dictate low-level components (or call them) in a manner so that neither one is dependent upon the other.
This principle helps to prevent dependency rot. Dependency rot happens when each component depends upon every other component. In other words, dependency rot is when dependency happens in each direction (upward, sideways, downward). The Hollywood Principle allows us to only make dependency in one direction.
The difference between the Dependency Inversion Principle and the Hollywood Principle is that the DIP gives us a general guideline: “Both higher-level and lower-level components should depend upon abstractions and not on concrete classes.” On the other hand, the Hollywood Principle specifies how higher-level component and lower-level components interact without creating dependencies.
You want to learn more about object oriented programming then visit here.
Polymorphism
What -- polymorphism is a design principle? Yes, it's the basic requirement for any OOP language to provide a polymorphism feature where derived classes can be referenced through parent classes.
It’s also a design principle in GRASP. This principle provides guidelines about how to use this OOP language feature in your object-oriented design.
This principle restricts the use of run-time type identification (RTTI). We implement RTTI in C# in the following manner:
if(aDevice.GetType() == typeof(USBDevice)){
//This type is of USBDEvice
}In Java, RTTI is accomplished using the function getClass() or instanceOf()
if(aDevice.getClass() == USBDevice.class){
// Implement USBDevice
Byte[] data = USBDeviceObj.ReadUART32();
}
If you have written this type code in your project then now is the time to refactor that code and improve it using the polymorphism principle.
Look at the following diagram:
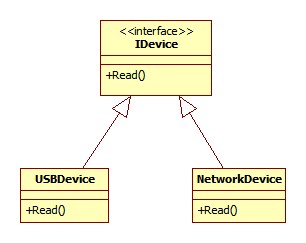
Here I have generalized the read method in the interface and delegated the device specific implementation to their classes (e.g ReadUART32() in USBDevice).
Now, I just use the method Read.
//RefactoreCode
IDevice aDevice = dm.getDeviceObject();
aDevice.Read();Where will the implementation of getDeviceObject() come from? This we will discuss in the Creator Principle and Information Expert Principle below, where you will learn about assigning the responsibilities to classes.
Information Expert
This is a simple GRASP principle and it gives guidelines about giving responsibilities to classes. It states that you should assign a responsibility to the class which has the information necessary to fulfill that responsibility.
Consider the following classes:

In our scenario, a simulation is performed at full speed (600 loops per second), whereas the user display is updated at a reduced speed. Here, I have to assign a responsibility to determine whether to display the next frame or not.
Which class should handle this responsibility? I have two options: either the Simulation class or SpeedControl class.
Now the SpeedControl class has the information about which frames have been displayed in the current sequence, thus according to the Information Expert SpeedControl should have this responsibility.
Creator
Creator is a GRASP principle which helps to decide which class should be responsible for creating a new instance of a class. Object creation is an important process, and it is useful to have a principle in deciding who should create an instance of a class.
According to Larman, a class, B, should be given the responsibility to create another class, A, if any of the following conditions are true.
a) B contains A
b) B aggregates A
c) B has the initializing data for A
d) B records A
e) B closely uses A
In our example of polymorphism, I have used Information Expert and Creator principles to give the DeviceManager class the responsibility to create a Device Object (dm.getDeviceObject()). This is because DeviceManger has the information to create a Device Object.
Pure Fabrication
In order to understand Pure Fabrication, you must first understand object-oriented analysis (OOA).
Object Oriented Analysis is a process through which you can identify the classes in your problem domain. For example, the domain model for a banking system contains classes like Account, Branch, Cash, Check, Transaction, etc. In this example, the domain classes need to store information about the customers. In order to do that one option is to delegate data storage responsibility to domain classes. This option will reduce the cohesiveness of the domain classes (more than one responsibility). Ultimately, this option violates the SRP principle. To learn more about object oriented analysis visit here.
Another option is to introduce another class which does not represent any domain concept. In the banking example, we can introduce a class called, “PersistenceProvider.” This class does not represent any domain entity. The purpose of this class is to handle data storage functions. Therefore “PersistenceProvider” is a pure fabrication.
Controller
When I started developing software, I wrote most of my programs using Java's swing components and most of my logic behind listeners.
Then I learned about domain models. So, I moved my logic from listeners to Domain models. But I directly called the domain objects from listeners. This creates a dependency between the GUI components (listeners) and the domain model. Controller design principles helped in minimizing the dependency between GUI components and the Domain Model classes.
There are two purposes of the Controller. The first purpose of the Controller is to encapsulate a system operation. A system operation is something that your user wants to achieve, e.g. buying a product or entering an item into the cart. This system operation is then accomplished by calling one or more method calls between the software objects.The second purpose of the Controller is to provide a layer between the UI and the Domain Model.
A UI enables users to perform system operations. A Controller is the first object after the UI layer that handles the system operations requests, and then delegates the responsibility to the underlying domain objects.
For example, here is a MAP Class which represents a Controller in one of our software codes.

From the UI we delegate the responsibility of "moving cursor" to this Controller and then this calls the underlying domain objects to move the cursor.
By using the Controller principle you will have the flexibility to plug in another user interface like a command line interface or a web interface.
Favor Composition Over Inheritance
Primarily there are two tools in object oriented programming to extend the functionality of existing code. The first one is inheritance.
The second method is composition. In programming words, by having a reference to another object you can extend that object’s functionality. If using composition, add a new class create its object and then use that object using its reference where you want to extend the code.
A very helpful feature of the composition is that behavior can be set at run-time. On the other hand, using inheritance you can only set the behavior at compile time. This will be shown in the example below.
When I was a newbie and used inheritance to extend the behavior, these are the classes that I designed:

Initially, I only know about processing an incoming stream of data, and there were two kinds (Stream A and Stream B) of data. After a few weeks, I figured out that endianness of the data should be handled. Thus, I came up with the class design shown below:

Later on, another variable was added to the requirements. This time I have to handle the polarity of the data. Imagine how many classes I have to add? Two types of polarity for Stream A, StreamB, a stream with endianness, and so on. A class explosion! Now I will have to maintain a large number of classes.
Now, if I handle the same problem using composition, the following will be the class design:
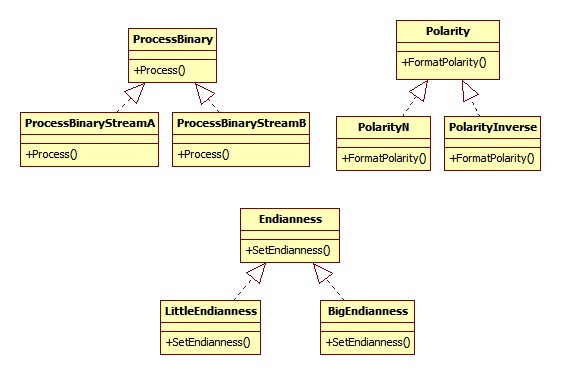
I added new classes and then used them in my code by using their references. See the listing below:
clientData.setPolarity(new PolarityOfTypeA); // or clientData.setPolarity(new PolarityOfTypeB)
clientData.FormatPolarity;
clientData.setEndianness(new LittleEndiannes());// setting the behavior at run-time
clientData.FormatStream();Hence I can provide the instances of the classes according to the behavior that I want. This feature reduced the total number of classes and ultimately the maintainability issues. Hence favoring composition over inheritance will reduce maintainability problems and give you the flexibility to set behavior at run-time.
Indirection
This principle answers one question: How do you cause objects to interact in a manner that makes bond among them remain weak?
The solution is: Give the responsibility of interaction to an intermediate object so that the coupling among different components remains low.
For example, a software application works with different configurations and options. To decouple the domain code from the configuration a specific class is added - which shown in the following listing:
Public Configuration{
public int GetFrameLength(){
// implementation
}
public string GetNextFileName(){
}
// Remaining configuration methods
}In this way, if any domain object wants to read a certain configuration setting it will ask the Configuration class object. Therefore, the main code is decoupled from the configuration code.
If you have read the Pure Fabrication Principle, this Configuration class is an example of pure fabrication. But the purpose of indirection is to create de-coupling. On the other hand, the purpose of pure fabrication is to keep the domain model clean and represent only domain concepts and responsibilities.
Many software design patterns like Adapter, Facade, and Observer are specializations of the Indirection Principle.
Published at DZone with permission of Muhammad Umair. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments