Speeding Up Large Collections Processing in Java
The parallel streams of Java 8 are a straightforward way to improve collections processing. But, other custom parallel strategies may perform better.
Join the DZone community and get the full member experience.
Join For FreeAccording to The Britannica Dictionary, the term collection designates:
...a group of interesting or beautiful objects brought together in order to show or study them.
Java, as well as many other programming languages (if not all), owns a data structure that embodies the essence of that term, that is, a group of individual objects represented as a single unit and upon which a set of operations can be performed. From the perspective of computational programs that deal with large volumes of data, a typical operation involving collections is the transformation of each of its objects. In this article, the underlying concept of that operation is being borrowed from the ETL (Extract, Transform, and Load) processes:
...the process of converting the extracted/acquired data from its previous form into the form it needs to be in so that it can be placed into another database.
To keep the focus on the collection handling by itself, the database element will be abstracted from the transform operation. Since version 1.2, Java has counted on an java.util.Collection interface that is the root of its collections hierarchy. Until the release of Java 7, the only way to reach an outstanding improvement in the performance of processing large collections was by parallelizing this operation. However, with the advent of Java 8, the new java.util.stream package provides:
...a Stream API to support functional-style operations on streams of elements. The Stream API is integrated into the Collections API, which enables bulk operations on collections, such as sequential or parallel map-reduce transformations.
Since then, Java offers a native way of trying to get relevant performance improvements considering the parallelization of transform operations applied to collections. This strategy is considered a "trying", as simply using parallel stream operations does not guarantee better performance. It depends on factors that are outside the scope of this article. Despite that, parallel streams constitute a good starting point to look for any processing improvement.
In this article, a very simple transform operation will be applied to a large Java collection. Thus, three different parallel processing strategies will be benchmarked. The performance of each one will be compared with the results achieved using both serial and parallel native streams.
Transform Operation
For the transformation operation, a functional interface was defined. It just takes an element of type R, applies a transform operation, and returns a transformed object of type S.
@FunctionalInterface
public interface ElementConverter<R, S> {
S apply(R param);
}The operation itself consists of capitalizing the String provided as a parameter. Two implementations of the ElementConverter interface were created, one transforms a single String into a single uppercase String:
public class UpperCaseConverter implements ElementConverter<String, String> {
@Override
public String apply(String param) {
return param.toUpperCase();
}
}And the other performs the same operation on a collection:
public class CollectionUpperCaseConverter implements ElementConverter<List<String>, List<String>> {
@Override
public List<String> apply(List<String> param) {
return param.stream().map(String::toUpperCase).collect(Collectors.toList());
}
}An AsynchronousExecutor class was also implemented with a dedicated method for each parallel processing strategy besides some other auxiliaries ones.
public class AsynchronousExecutor<T, E> {
private static final Integer MINUTES_WAITING_THREADS = 1;
private Integer numThreads;
private ExecutorService executor;
private List<E> outputList;
public AsynchronousExecutor(int threads) {
this.numThreads = threads;
this.executor = Executors.newFixedThreadPool(this.numThreads);
this.outputList = new ArrayList<>();
}
// Methods for each parallel processing strategy
public void shutdown() {
this.executor.shutdown();
try {
this.executor.awaitTermination(MINUTES_WAITING_THREADS, TimeUnit.MINUTES);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException(e);
}
}Sublist Partition
The first parallel strategy to boost the transform operation over a collection is based on an extension of the java.util.AbstractList. In a nutshell, the CollectionPartitioner splits a source collection into sublists whose size is computed according to the number of threads that will be used in the processing. First, the chunk size is calculated by taking the quotient between the source collection size and the number of threads. Then each sublist is copied from the source collection based on pairs of indices (fromIndex, toIndex) whose values are synchronously computed as:
fromIndex = thread id + chunk size
toIndex = MIN(fromIndex + chunk size, source collection size)public final class CollectionPartitioner<T> extends AbstractList<List<T>> {
private final List<T> list;
private final int chunkSize;
public CollectionPartitioner(List<T> list, int numThreads) {
this.list = list;
this.chunkSize = (list.size() % numThreads == 0) ?
(list.size() / numThreads) : (list.size() / numThreads) + 1;
}
@Override
public synchronized List<T> get(int index) {
var fromIndex = index * chunkSize;
var toIndex = Math.min(fromIndex + chunkSize, list.size());
if (fromIndex > toIndex) {
return Collections.emptyList(); // Index out of allowed interval
}
return this.list.subList(fromIndex, toIndex);
}
@Override
public int size() {
return (int) Math.ceil((double) list.size() / (double) chunkSize);
}
}Once each thread has applied the transform operation to all objects of its respective sublist, it must synchronously add the modified objects to the output list. These steps are guided by a specific method of the AsynchronousExecutor class.
public class AsynchronousExecutor<T, E> {
public void processSublistPartition(List<T> inputList, ElementConverter<List<T>, List<E>> converter) {
var partitioner = new CollectionPartitioner<T>(inputList, numThreads);
IntStream.range(0, numThreads).forEach(t -> this.executor.execute(() -> {
var thOutput = converter.apply(partitioner.get(t));
if (Objects.nonNull(thOutput) && !thOutput.isEmpty()) {
synchronized (this.outputList) {
this.outputList.addAll(thOutput);
}
}
}));
}
}Shallow Partition
The second parallel processing strategy appropriates the idea behind the shallow copy concept. In fact, the threads involved in the process do not receive a sublist copied from the source collection. Instead, each thread calculates its respective pair of indexes (fromIndex, toIndex) using the same algebra of the Sublist Partition strategy and operates directly on the source collection. But, it is assumed as a requirement of the problem that the source collection cannot be modified. In this case, the threads read the objects respecting their slice of the source collection and store the new transformed objects in a new collection of the same size as the original.
Note that this strategy does not have any synchronous execution points during the transform operation, that is, all threads perform their tasks completely independently of each other. But assembling the output collection can be done using at least two different approaches.
List-Based Shallow Partition
In this approach, a new list composed of default elements is created before processing the collection. Disjoint slices - delimited by index pairs (fromIndex, toIndex) - of this new list are accessed by threads. They store each new object generated from reading the respective slice from the source collection. A new method of the AsynchronousExecutor class is dedicated to this approach.
public class AsynchronousExecutor<T, E> {
public void processShallowPartitionList(List<T> inputList, ElementConverter<T, E> converter) {
var chunkSize = (inputList.size() % this.numThreads == 0) ?
(inputList.size() / this.numThreads) : (inputList.size() / this.numThreads) + 1;
this.outputList = new ArrayList<>(Collections.nCopies(inputList.size(), null));
IntStream.range(0, numThreads).forEach(t -> this.executor.execute(() -> {
var fromIndex = t * chunkSize;
var toIndex = Math.min(fromIndex + chunkSize, inputList.size());
if (fromIndex > toIndex) {
fromIndex = toIndex;
}
IntStream.range(fromIndex, toIndex)
.forEach(i -> this.outputList.set(i, converter.apply(inputList.get(i))));
}));
}
}Array-Based Shallow Partition
This approach differs from the previous one just by the fact threads use an array to store the transformed new objects instead of a list. After all, threads finish their operations, the array is converted to the output list. Again, a new method is added to the AsynchronousExecutor class for this strategy.
public class AsynchronousExecutor<T, E> {
public void processShallowPartitionArray(List<T> inputList, ElementConverter<T, E> converter)
var chunkSize = (inputList.size() % this.numThreads == 0) ?
(inputList.size() / this.numThreads) : (inputList.size() / this.numThreads) + 1;
Object[] outputArr = new Object[inputList.size()];
IntStream.range(0, numThreads).forEach(t -> this.executor.execute(() -> {
var fromIndex = t * chunkSize;
var toIndex = Math.min(fromIndex + chunkSize, inputList.size());
if (fromIndex > toIndex) {
fromIndex = toIndex;
}
IntStream.range(fromIndex, toIndex)
.forEach(i -> outputArr[i] = converter.apply(inputList.get(i)));
}));
this.shutdown();
this.outputList = (List<E>) Arrays.asList(outputArr);
}
}Benchmarking the Strategies
The CPU time of each strategy was calculated by taking the average of 5 executions and collections of 1,000,000 and 10,000,000 random String objects were generated in each execution. The code was executed on a machine running Ubuntu 20.04 LTS 64-bit operating system with 12GB of RAM and a CPU Intel Xeon E3-1240 V3 of 3.40GHz with 4 cores per socket (2 threads per socket). The results are as presented in below table:
|
Strategy
|
CPU time (ms) - 1M objects |
CPU time (ms) - 10M objects
|
|
Native Serial Stream
|
173.6
|
1826.3
|
|
Native Parallel Stream
|
60.8
|
803.9
|
|
Sublist Partition
|
61.1
|
639.2
|
|
List-based Shallow Partition
|
56.4
|
765.6
|
|
Array-based Shallow Partition
|
39.3
|
643.4
|
The first expected result is that the native serial stream achieved the highest CPU time. Actually, it was added to the tests for establishing an initial performance parameter. Simply changing the strategy to a native parallel stream resulted in an improvement of about 34.4% for collections of 1M objects and 44% of 10M objects. Thus, from now on, the performance of the native parallel stream strategy will be used as a reference for the other three strategies.
Considering collections of 1M objects, no relevant decrease in CPU time was observed with the List-based Shallow Partition strategy - there just was a subtle improvement of around 7% - while the Sublist Partition strategy performed worse. The highlight was the Array-based Shallow Partition which decreased the CPU time by around 35.4%. On the other hand, regarding 10 times larger collections, all three strategies beat the parallel stream time. The best performance improvement was achieved by the Sublist Partition - it decreases execution time by about 20.5%. However, a very similar performance was also observed with the Array-based Shallow Partition - it improved the CPU time by almost 20%.
As the Array-based Shallow Partition strategy presented a relevant performance with both collections size, its speed up ratio was analyzed. The speedup is calculated by taking the ratio T(1)/T(p) where T is the CPU time for running the program with p threads; T(1) corresponds to the elapsed time to execute the program sequentially. Below is the result of plotting the Speed Up X Number of Threads chart for that strategy.
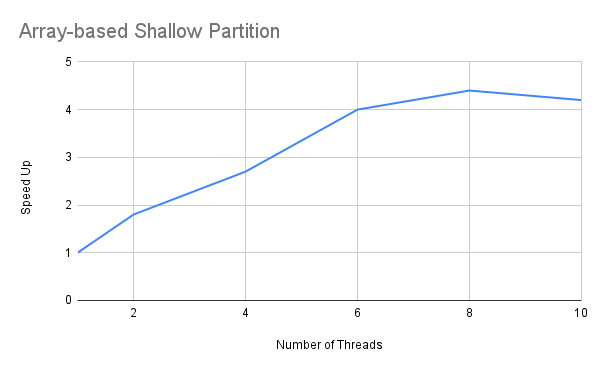
Conclusion
The use of native parallel streams provides a reliable initial threshold to speed up the processing of large collections. Nevertheless, it is worth trying alternatives parallelization strategies to achieve better performances rates. This article presented three distinct algorithms that can be used for overcoming the parallel streams' performance. The complete source code is available on a GitHub repository - it is a Maven project whose specific module is dzone-async-exec.
Opinions expressed by DZone contributors are their own.
Comments