Spring Boot: Boost JPA Bulk Insert Performance by 100x
Want to improve your insert records? In this article, you can learn how to improve bulk insert performance by 100x using Spring Data JPA.
Join the DZone community and get the full member experience.
Join For FreeI was facing a problem where I wanted to insert millions of records into the database, which needed to be imported from the file.
So, I did some research around this, and I would like to share with you what I found which helped me improve the insert records throughput by nearly 100 times.
Initially, when I was just trying to do bulk insert using spring JPA’s saveAll method, I was getting a performance of about 185 seconds per 10,000 records. After doing the following changes below, the performance to insert 10,000 records was just in 4.3 seconds.
Yes, 4.3 Seconds for 10k records.
So, to achieve this, I had to change the way I was inserting data.
1. Change the Number of Records While Inserting
When I was inserting initially, I was pushing all the 10k records from the list directly by calling the saveAll method. I changed this to the batch size of 30. You could also increase the batch size to even 60, but it doesn’t half the time taken to insert records. See the table below.
For this, you need to set the hibernate property batch_size=30 .
xxxxxxxxxx
spring.jpa.properties.hibernate.jdbc.batch_size=30
Then, I added the following connection string properties:
xxxxxxxxxx
cachePrepStmts=true
useServerPrepStmts=true
rewriteBatchedStatements=true
e.g
jdbc:mysql://localhost:3306/BOOKS_DB?serverTimezone=UTC&cachePrepStmts=true&useServerPrepStmts=true&rewriteBatchedStatements=true
2. Send the Batched Records
Next, I changed the code for inserting, so that saveAll methods get batch sizes of 30 to insert as per what we also set in the properties file. A very crude implementation of something like this:
xxxxxxxxxx
for (int i = 0; i < totalObjects; i = i + batchSize) {
if( i+ batchSize > totalObjects){
List<Book> books1 = books.subList(i, totalObjects - 1);
repository.saveAll(books1);
break;
}
List<Book> books1 = books.subList(i, i + batchSize);
repository.saveAll(books1);
}
This reduced the time by a little; it dropped from 185 secs to 153 Secs. That's approximately an 18% improvement.
3. Change the ID Generation Strategy
This made a major impact.
Initially, I was using the @GeneratedValue annotation with strategy i.e GenerationType.IDENTITY on my entity class.
Hibernate has a disabled batch update with this strategy because it has to make a select call to get the id from the database to insert each row. You can read more about it here.
I changed the strategy to SEQUENCE and provided a sequence generator.
xxxxxxxxxx
public class Book {
(strategy = SEQUENCE, generator = "seqGen")
(name = "seqGen", sequenceName = "seq", initialValue = 1)
private Long id;
This drastically changed the insert performance, as Hibernate was able to leverage bulk insert.
From the previous performance improvement of 153 secs, the time to insert 10k records reduced to only 9 secs. That's an increase in performance by nearly 95%.
Note: MySQL doesn’t support creating sequences.
To get around this, I created a table with the name of the sequence having a single field called next_val. Then, I added a single row with an initial value.
For the above sequence, I created the following:
CREATE TABLE `seq` (
`next_val` bigint(20) DEFAULT NULL
);
INSERT INTO `seq` (`next_val`) VALUES(1);
Hibernate then used the table below as a sequence generator.
Next, I pushed it further to use higher batch sizes, and I noticed that doubling the batch size does not double down on time. The time to insert only gradually reduces. You can see this below:
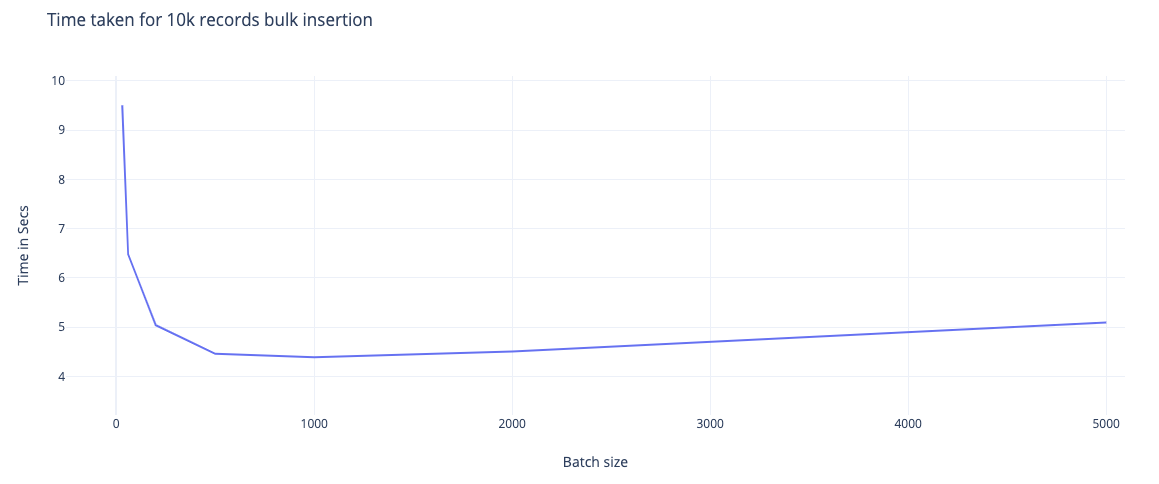
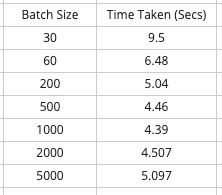
The most optimal batch size for my case was 1,000, which took around 4.39 secs for 10K records. After that, I saw the performance degrading, as you can see in the graph below.
Here are the stats I got:
As always, you can find the code on my GitHub repo.
Published at DZone with permission of Amrut Prabhu. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments